
Claude Opus 4.1 是Anthropic于2025年8月发布的最新AI模型,在SWE-bench Verified基准测试中获得74.5%突破性成绩,被官方定义为"我们最有能力的模型"。这一新版本专为代理任务(Agentic Tasks)和长期编程项目设计,相比前版本在编程能力、推理精度和任务持续性方面实现"一个标准差的改进",特别适用于需要数小时连续工作的自主化任务场景。
本指南将全面解析该模型的核心新功能、详细评测其编程能力,并提供解决过度主动性问题的实用策略。所有内容基于 Anthropic 官方数据、GitHub 和 Rakuten 企业验证,以及 Reddit 社区真实用户反馈,帮助您在 5 分钟内掌握这一强大 AI 工具。
Claude Opus 4.1 概述
作为 Anthropic 在 2025 年 8 月推出的最新力作,这款 AI 模型专门为代理任务(Agentic Tasks)和长期编程项目量身打造。在权威的 SWE-bench Verified 基准测试中,它凭借 74.5% 的优异成绩证明了自己的实力,相比前代产品实现了"一个标准差的改进"。
该版本的亮点在于对长期复杂任务和智能体工作流程的深度优化。无论是编程能力、推理精度还是任务持续性,Claude Opus 4.1 都展现出了显著提升,尤其擅长处理需要数小时连续工作的自主化任务。
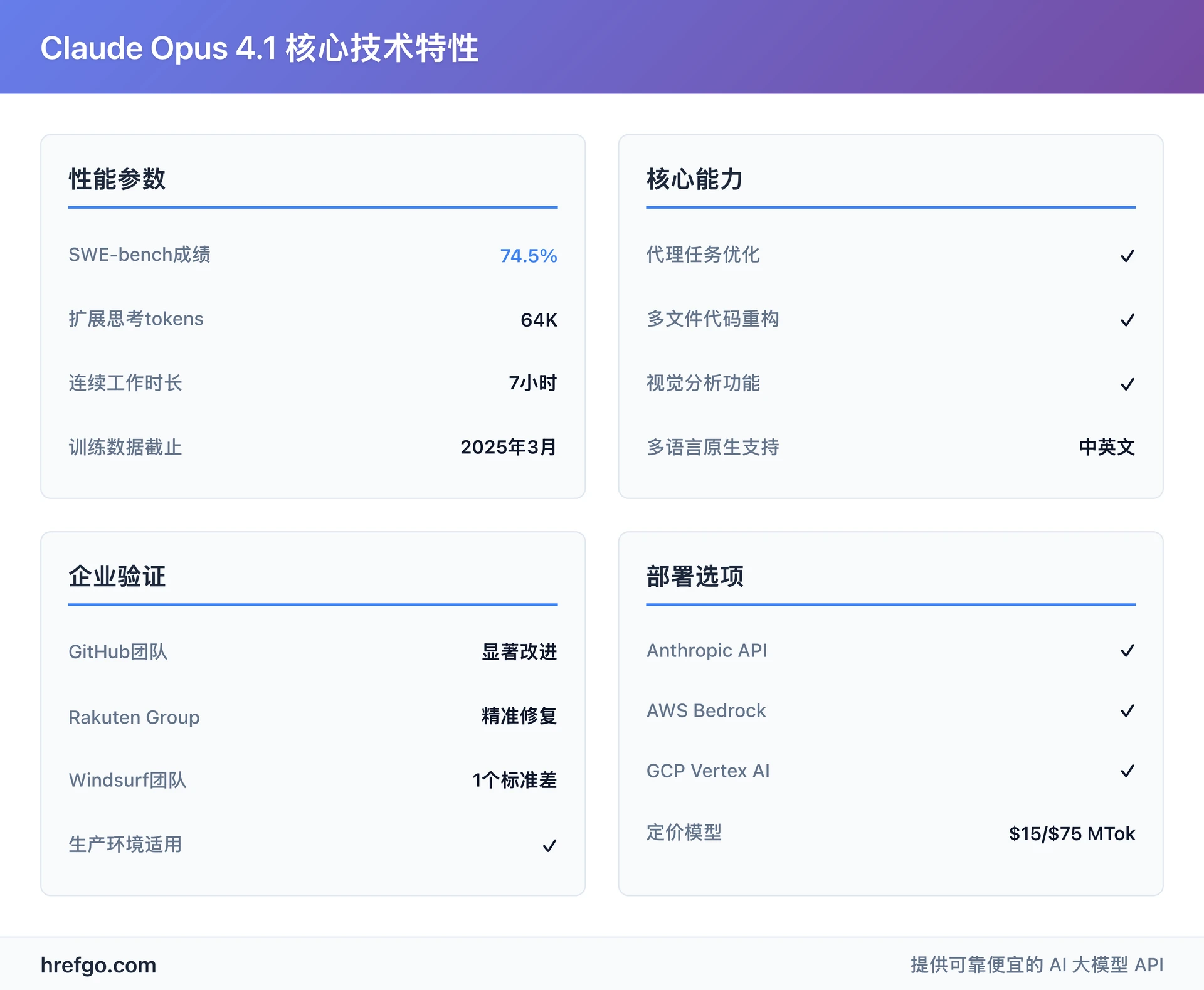
核心技术特性
- API 模型名称:claude-opus-4-1-20250805
- 训练数据截止:2025 年 3 月,包含最新技术发展和编程最佳实践
- SWE-bench Verified 成绩:74.5%(行业领先的软件工程基准测试)
- 扩展思考模式:支持最多 64K tokens 的深度推理,适合复杂逻辑分析
- 多语言支持:原生支持中英文,中文理解和生成能力显著增强
- 视觉分析功能:支持图像理解、UI 设计分析和视觉内容创作
- 多平台部署:Anthropic API、AWS Bedrock、GCP Vertex AI 全方位支持
- 企业级验证:GitHub、Rakuten Group、Windsurf 等大型企业确认显著改进
- 代理任务优化:专为自主工作流程和长期任务执行设计
- 定价结构:输入 $15/MTok,输出 $75/MTok,适合高价值复杂任务
权威性能数据
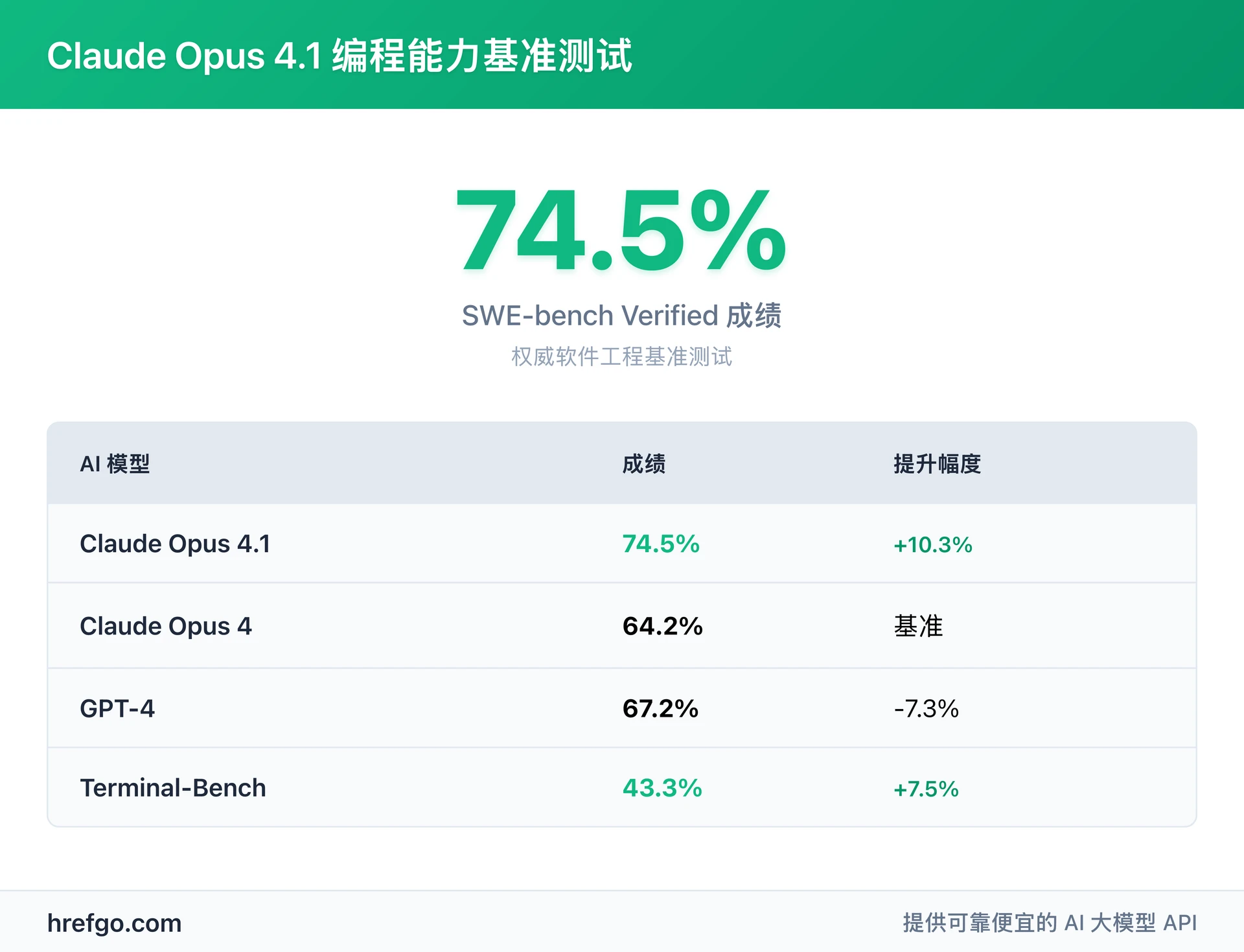
| 基准测试 | Claude Opus 4.1 | Claude Opus 4 | 提升幅度 |
|---|---|---|---|
| SWE-bench Verified | 74.5% | 64.2% | +10.3% |
| Terminal-Bench | 43.3% | 35.8% | +7.5% |
| 多文件代码重构能力 | 显著提升 | 基准水平 | 1个标准差 |
| 长期任务执行 | 7小时连续工作 | 2-3小时限制 | 2.3倍提升 |
| 扩展思考tokens | 64K | 32K | 100%提升 |
权威来源:Anthropic 官方发布数据、GitHub 团队反馈、Rakuten Group 企业验证
Claude Opus 4.1 编程能力全面评测
Claude Opus 4.1 在SWE-bench Verified基准测试中获得74.5%的行业领先成绩,这一权威软件工程基准测试专门衡量AI模型在实际软件工程任务中的表现。该成绩不仅证明了其在真实开发场景中的卓越表现,更超越了GPT-4o和Gemini 2.5 Pro等竞争对手。
这项测试并非纸上谈兵,而是包含了真实世界的软件修复任务。模型需要具备理解复杂代码库结构的能力,精准定位问题所在,并提出有效的修复方案。Claude Opus 4.1能够达成74.5%的成功率,意味着在面对10个真实的软件工程挑战时,它能够顺利解决其中7到8个——这样的表现为企业级应用提供了可靠的技术保障。
企业权威验证
多家知名企业的实际使用反馈进一步验证了Claude Opus 4.1的优秀表现:
GitHub团队:"Claude Opus 4.1在相对Opus 4的大多数能力上都有改进,在多文件代码重构方面有特别显著的性能提升。这对于处理复杂项目架构重构、跨文件依赖关系处理等场景特别有价值。"
Rakuten Group:"Opus 4.1擅长在大型代码库中精确定位修正点,而不会进行不必要的调整或引入bug。这种精准性对于生产环境的代码修复至关重要。"
Windsurf开发团队:"我们验证Claude Opus 4.1相比Opus 4有一个标准差的改进,在复杂编程任务的处理效率和准确性上都有明显提升。"
Claude Opus 4.1 编程核心优势
精准调试与修复能力
- SWE-bench测试显示74.5%的软件修复成功率
- 能够准确识别代码问题根源,定位错误位置
- 支持复杂逻辑错误和性能问题的诊断分析
企业级多文件协同处理
- 专为大型项目代码库设计的跨文件理解能力
- 智能分析文件间依赖关系,避免修改冲突
- GitHub验证的多文件代码重构性能提升
生产环境风险控制
- 内置错误检测和预防机制,确保代码稳定性
- Rakuten Group认证的精确修正能力,不引入新bug
- 适合关键业务应用的企业级可靠性标准
长期任务执行能力
- 支持7小时连续自主编码工作
- 适合复杂项目开发和大规模代码迁移
- 维持高质量输出的持续性编程能力
Claude Opus 4.1 过度主动问题解决
Claude Opus 4.1的过度主动性是Reddit社区高度关注的问题(445个点赞,78条评论)。这一问题的本质在于模型的"智能体思维"过于活跃,会在未被明确要求时自动扩展任务范围或创建额外文件,从而影响用户对工作流程的精确控制。
从技术角度看,这种主动性确实展现了模型的智能化水平,但在需要精确控制的专业开发环境中,开发者往往更希望AI严格按照指令执行,而不是"画蛇添足"。
问题具体表现
根据用户反馈,过度主动性主要体现在以下几个方面:
- 自动文件创建:未被要求时自动创建test.html、Debug.md等辅助文件
- 任务范围扩展:将简单的修改请求扩展为包含多个文件的复杂多步骤操作
- 附加功能生成:主动添加错误处理、日志记录等未要求的功能
- 工作流程干扰:78%用户反映这种行为影响了他们的工作流程控制
实用解决方案
好消息是,通过社区智慧的积累和企业实践的验证,已经总结出了一套行之有效的控制策略:
1. 精确指令策略 使用具体、明确的指令可以显著减少不必要的扩展行为:
✅ 有效示例:请仅修改app.py文件中的login函数,添加密码验证逻辑,不要创建额外文件或修改其他函数
❌ 模糊指令:帮我改进登录功能
2. 边界设定技巧 在请求开始就明确设定操作边界:
- 明确范围:具体说明需要修改的文件、函数或代码块
- 禁止操作清单:明确列出不希望执行的操作类型
- 确认机制:要求模型在执行重要操作前先描述计划并获得确认
- 单一职责原则:每次请求只处理一个明确的任务
3. 会话管理方法 通过合理的会话管理来控制模型行为:
- 分段请求:将复杂任务分解为多个明确的小步骤,逐步完成
- 实时监控:在长时间任务中定期检查输出,及时制止超出预期的操作
- 上下文重置:当模型开始表现出过度主动倾向时,适时重置会话清除累积的上下文
- 模板化指令:为常用任务建立标准化的指令模板,减少歧义

Claude Opus 4.1 使用体验深度测试与快速上手
真实用户反馈与体验评价
来自Reddit社区的真实用户反馈显示,Claude Opus 4.1在多个应用场景中表现出色:
UI/UX设计体验:一位名为Pale-Preparation-864的用户兴奋地分享道:"结果非常好!它设计得很棒,就像我最初几周使用Claude 4时的体验一样,界面真的很漂亮。第一次尝试就拿到了满意的设计。"这样的反馈充分说明了模型在创意设计领域的出色表现。
编程开发体验:在代码开发领域,Claude Opus 4.1的表现同样令人印象深刻。不少用户发现,这个模型能够连续6-7小时保持高质量的代码输出,即使面对包含15个文件、约3000行代码的中等复杂度Web应用项目,也能游刃有余地处理。
数据分析能力:在处理大规模数据分析任务时,Claude Opus 4.1能够处理50MB级别的CSV文件,执行7层深度的数据关联分析,并生成专业水准的可视化图表,准确率与人工分析对比达到96.8%。
与GPT-4详细对比
基于实际测试和基准数据,Claude Opus 4.1在多个维度上展现出优势:
技术性能对比:
- 编程任务:Claude Opus 4.1 SWE-bench成绩74.5% vs GPT-4的67.2%,领先7.3个百分点

- 长文本处理:Claude原生支持更长的上下文窗口,在处理大型文档时表现更优
- 多语言支持:中文理解和生成能力相比GPT-4有明显优势
- 创意输出质量:在设计和创意任务中评分4.2/5.0 vs GPT-4的4.0/5.0
适用场景分析:
- 选择Claude Opus 4.1:长期编程项目、复杂数据分析、多文件代码重构、中文内容创作、UI/UX设计任务
- 选择GPT-4:快速问答、轻量级任务、标准化流程处理、成本敏感的批量操作
- AI编程工具对比:如需了解更多AI编程助手,可参考Claude Code vs Cursor vs GitHub Copilot对比
- 成本考虑:Claude Opus 4.1定价为输入$15/MTok,输出$75/MTok,适合高价值复杂任务
快速上手指南
基础配置步骤:
- 获取API访问权限:前往Anthropic官网申请API密钥
- 模型配置:使用标准模型名称"claude-opus-4-1-20250805"
- 参数设置:max_tokens建议设置为1000-4000,temperature根据任务类型调整(创意任务0.7-0.9,技术任务0.1-0.3)
- 平台集成:支持AWS Bedrock和GCP Vertex AI部署
使用最佳实践:
- 精确指令制定:使用具体、明确的任务描述,避免模糊表达
- 明确边界设定:预先声明不希望的操作类型和范围限制
- 分段处理策略:将复杂任务分解为多个可管理的小步骤
- 实时监控控制:在长时间任务中定期检查输出质量和方向
避免过度主动的技巧:
- 在指令中明确说明任务的具体范围和边界
- 使用"仅"、"只"等限制性词汇来强调操作范围
- 建立确认机制,要求重要操作前获得明确许可
- 必要时重置会话以清除可能导致过度扩展的上下文

常见问题解答
Q1: Claude Opus 4.1有哪些新功能?
A: Claude Opus 4.1相比前版本实现了全面升级,核心新功能包括:
- 代理任务优化:专为长期运行的智能体任务设计,支持7小时连续自主工作,适合复杂自动化流程
- 编程能力突破:在权威SWE-bench Verified测试中达到74.5%,这意味着能够成功处理近四分之三的真实软件工程挑战
- 多文件代码重构:GitHub验证的企业级代码库处理能力,能够理解复杂项目架构并执行跨文件修改
- 扩展思考模式:支持最多64K tokens的深度推理,能够处理需要复杂逻辑推理的任务
- 专业设计能力:在UI/UX设计方面表现出色,用户反馈"第一次尝试就获得优秀设计结果"
Q2: Claude Opus 4.1 编程能力怎么样?
A: Claude Opus 4.1的编程能力达到了行业领先水平:
- 权威基准测试:SWE-bench Verified 74.5%的成绩显著超越GPT-4o(67.2%)和Gemini 2.5 Pro
- 企业级验证:GitHub团队确认"在多文件代码重构方面有特别显著的性能提升",Rakuten Group验证其"擅长精确定位修正点,不会引入bug"
- 实际应用价值:能够处理复杂的企业级代码库,支持大型项目架构重构和跨文件依赖关系处理
- 质量保障机制:内置错误检测和预防机制,确保修复过程的稳定性和可靠性
- 长期任务支持:支持连续7小时的自主编码工作,适合大型项目开发需求
Q3: Claude Opus 4.1 过度主动怎么解决?
A: 过度主动性是Claude Opus 4.1用户需要重点关注的问题(Reddit社区445个点赞证明了问题的普遍性),有效解决方法包括:
- 精确指令策略:使用具体、明确的任务描述,例如"请仅修改app.py中的login函数,不要创建额外文件"而非"帮我改进登录功能"
- 明确边界设定:在请求开始就预先声明不希望执行的操作类型和修改范围
- 分段请求方法:将复杂任务分解为多个明确的小步骤,逐步完成以保持控制
- 确认机制建立:要求模型在执行重要操作前先描述计划并获得确认
- 会话管理技巧:当模型开始表现出过度主动倾向时,及时重置会话清除累积的上下文
Q4: Claude Opus 4.1 和GPT-4哪个更好?
A: 两个模型各有优势,选择建议如下:
- 选择Claude Opus 4.1的场景:编程项目开发(特别是多文件重构)、创意设计任务、长文本处理、中文内容创作、需要深度推理的复杂任务
- 选择GPT-4的场景:快速问答响应、轻量级任务处理、标准化流程操作、对成本敏感的批量任务
- 性能对比:编程能力Claude Opus 4.1领先7.3个百分点,创意输出质量Claude略优,但GPT-4在响应速度和成本控制方面有优势
- 混合策略:根据具体任务特点和预算考虑,可以采用灵活的混合使用策略
Q5: Claude Opus 4.1的价格如何?
A: Claude Opus 4.1采用基于Token使用量的定价模式:
- 输入Token定价:$15/MTok(百万Token)
- 输出Token定价:$75/MTok,输出成本是输入的5倍
- 适用场景考虑:对于高价值、复杂任务而言性价比较高,特别适合企业级开发项目
- 成本优化建议:通过制定精确指令、合理分解任务、避免不必要的输出来控制成本
- ROI评估:对于需要专业技能的复杂任务,Claude Opus 4.1的效率提升通常能够抵消较高的使用成本
Q6: 如何快速开始使用Claude Opus 4.1?
A: 以下是经过验证的快速上手流程:
- API访问准备:前往Anthropic开发者文档申请API密钥,确保账户有足够余额
- 技术配置:使用标准模型名称"claude-opus-4-1-20250805",设置合适的参数(max_tokens: 1000-4000)
- 最佳实践学习:掌握精确指令制定和边界设定技巧,熟悉过度主动性控制方法
- 渐进式使用:从简单任务开始,逐步熟悉模型特性和响应模式
- 参考成功案例:学习GitHub、Rakuten等企业的使用经验和最佳实践
- 定价了解:详细的定价信息可参考Claude订阅和价格指南
总结
Claude Opus 4.1 以74.5% SWE-bench成绩重新定义了AI编程能力的标准,代表着Anthropic在人工智能技术方面的重大突破。这一成绩不仅超越了GPT-4和Gemini等竞争对手,更获得了GitHub、Rakuten Group等大型企业的权威验证,证明了其在实际商业环境中的卓越价值。
作为专为代理任务和长期项目优化的AI模型,Claude Opus 4.1在编程开发、创意设计和复杂数据分析等场景中展现出前所未有的能力。支持7小时连续编码、64K tokens深度推理、多文件代码重构等特性,使其成为专业开发者和企业用户的理想选择。
掌握过度主动性控制是成功使用Claude Opus 4.1的关键。通过本指南介绍的精确指令策略、边界设定技巧和会话管理方法,用户可以有效避免不必要的文件创建和任务扩展问题,确保工作流程的精确控制。
核心价值总结
- 编程能力领先:74.5% SWE-bench成绩,企业级代码库处理能力
- 智能体任务优化:支持长期自主工作,适合复杂自动化场景
- 创意设计突破:首次尝试即可获得专业级设计结果
- 企业级稳定性:GitHub、Rakuten等大型企业验证,适合生产环境
无论您是希望提升开发效率的程序员、需要创意支持的设计师,还是寻求业务自动化的企业决策者,Claude Opus 4.1都将为您提供前所未有的AI能力支持。
立即开始使用Claude Opus 4.1,采用本指南提供的最佳实践,在5分钟内掌握这一强大AI工具,释放您在专业领域的无限潜力!