
你接了个大活:把一个老项目从一个框架迁到另一个,改动散在四十几个文件里——service、路由、测试、配置都要动。你打开 Claude Code,把任务一口气讲给它。前十几个文件改得挺顺,然后它开始走样:把一个已经改过的接口又改回去,"忘了"前面定下的命名约定,改到第三十个文件时连最初要做什么都模糊了。你重开一轮对话想接着干,上下文已经断了。就在你来回试的时候,刷到有人提 /workflows、提 ultracode,说这玩意儿能把这种大任务跑下来;可你手上已经在用 agent、用 skill、用子代理,实在分不清这又是个什么新东西。
先把你最想要的答案给你:这里说的 workflow(动态工作流),是一段 Claude 替你写、由运行时在后台执行的 JavaScript 脚本,用来大规模编排子代理,把"计划"从对话上下文搬进代码。 关键在最后半句。你刚才之所以翻车,是因为整个计划、每一步的中间结果都挤在那个会越填越满的对话窗口里;workflow 把循环、分支、中间产物都固化进脚本,Claude 的对话上下文只需要装最终答案,不再被几十个文件的来回撑爆。这是搜 claude workflow 最该先记住的一句。
它跟你熟悉的那个 Claude Code 是同一套东西的延伸,不是另起炉灶。Claude Code 本来就不是网页版那种你复制粘贴代码的对话助手——它是命令行工具,自动从项目目录拉上下文、读 CLAUDE.md,能直接改文件、跑测试、提交版本控制(据 Milvus 的对比说明)。workflow 就长在这套"能在你项目里连续动手"的能力之上。
这篇要解决两层困惑。一层是概念:workflow 到底是什么,它和一句话 prompt、和 agent 的本质区别在哪,跟你已经在用的 skill、子代理又是什么关系、该用哪个。另一层是实操:怎么把它触发起来、怎么让 Claude 写一个、值不值得用、会不会一不留神烧爆 token。从概念这层开始拆。
prompt、workflow、agent:差别在「谁掌握那份计划」
要看懂 workflow 和你平时随手敲的一句话有什么不一样,把 AI 交互摆成三层就清楚了。

最底下一层是 prompt(提示,也就是一次输入一次响应的最简单用法)。给一个输入,模型生成一次响应,效果好不好全看你这句话写得怎么样(Confluent 的对比把它叫做最简单的 AI 交互形式)。让 Claude 改一个函数、解释一段报错,都是这一层——一进一出,没有第二步。
往上一层是 workflow(工作流)。它把「一进一出」拉成一串预先定义好、由代码编排的步骤,按固定顺序执行,模型在这中间不做决策、也不迭代,只是把每一步跑完。换句话说,流程长什么样在脚本写好的那一刻就定死了——谁先谁后是代码说了算,不是模型临场判断。打个比方:prompt 像你口头临时吩咐一件事,workflow 像一张写死的流水线工单,第一步读文件、第二步改代码、第三步跑测试,顺序写死在那。
最上面一层是 agent(代理)。Anthropic 给它的定义是:大语言模型自己动态决定流程和工具使用、掌控如何完成任务的系统。和 workflow 正好对着——agent 是模型边走边决定下一步,workflow 是路径提前铺好。
Anthropic 把这两者都归进代理式系统(agentic systems,即由大模型驱动的自动化系统这一大类),但特意在架构上划了一刀,分界线就一句话:**编排路径是预先写死的代码,还是由模型动态决定。**工作流是前者(大语言模型和工具通过预定义的代码路径来编排),代理是后者。这条线也是你区分这三层的唯一判据——不用记一堆特征,只问一句「这次的步骤顺序,是谁定的」。
那 Claude Code 里看到的 /workflows,算哪一层
这里有个容易绕晕的地方,得专门点破。
Anthropic 架构定义里的 workflow 是个抽象概念,指「流程由预定义代码路径决定」这一类系统。但你在 Claude Code 里实际用到的「动态工作流」,那段编排子代理的 JavaScript 脚本不是你手写的,是 Claude 根据你的任务描述当场生成的(前面给过这个定义)。
所以它卡在中间:脚本一旦写好、跑起来,就是 workflow——固定的代码路径,运行时照着执行;但「写出这段脚本」这个动作本身是模型动态决策的,带着 agent 的味道。可以把 Claude Code 的动态工作流理解成那个抽象 workflow 概念的产品化落地,只不过连「写脚本」这一步也交给了模型。它处在 workflow 和 agent 之间,两头的特征都沾一点。
知道这个定位有实际用处:当你看到有人争论「workflow 到底算不算 agent」,多半是两边在说不同的东西——一边指那段固定的脚本,一边指生成脚本的过程。以 Claude Code 官方 /workflows 功能为准时,它指的是前者那段可执行、可保存的脚本。
怎么把它触发起来
知道了它是什么,下一个问题就是怎么让它动。有三种方式,按你想要的控制粒度选。
只想让某一次任务走工作流,在 prompt 里加上关键词 ultracode。这会让 Claude 为这个任务写一段工作流脚本,而不是逐回合手动处理。不想记关键词也行——直接用大白话说「use a workflow」「run a workflow」,效果一样。
想让 Claude 自动判断每个任务该不该用工作流,敲 /effort ultracode。ultracode 是把 xhigh 推理强度和自动工作流编排捆在一起的一个设置,开了之后,Claude 会为这个会话里每个实质性任务都主动规划一个工作流,不用你每次开口要。代价是它会自己决定哪些任务值得拆给并行子代理(它内部先做一轮预评估再定走不走,这套判断逻辑和它会在哪翻车,后面避坑那节再说)。
作用域要记牢:ultracode 只在当前会话有效,开一个新会话就重置回去。手头这摊大活干完、回去做日常小修小补时,用 /effort high 退回常规模式即可。
版本和关键词的坑:用错了根本触发不了
| 你的版本 | 字面关键词 | 自然语言(如 "use a workflow") |
|---|---|---|
| 低于 v2.1.154 | 用不了 | 用不了 |
| v2.1.154 ~ v2.1.160 之前 | workflow | 有效 |
| v2.1.160 及以后 | ultracode | 有效 |
两件事会咬到你。一是版本门槛:动态工作流要求 Claude Code v2.1.154 或更高,旧版本里这功能压根不存在。二是关键词换过名:v2.1.160 之前触发的字面关键词是 workflow,之后改成了 ultracode。如果你跟着一篇老文章敲 workflow,但本地已经升到新版,关键词对不上就触发不了——这种情况最稳的办法是别赌关键词,直接用自然语言「use a workflow」,它在两个版本里都认。

它还在变,别当成稳定功能用
动态工作流目前是**研究预览(research-preview,即官方放出来试水、尚未定型的阶段)**阶段的工具。Anthropic 已经拿它干过真活——内部用它做过规模相当大的代码移植——但研究预览意味着关键词、行为、默认开关都可能在版本间继续调整。你现在学到的触发方式和作用域规则,过几个版本未必原样保留,遇到对不上的时候,先去官方文档核一遍当前口径,比照着任何二手教程都靠谱(本节涉及的版本号、关键词均为截至 2026 年 6 月的状态)。
触发机制和版本限制清楚了,接下来的问题往往是:你手上已经有 agent、subagent、skill、agent team,workflow 到底该什么时候用、什么时候不用?
workflow、subagent、skill、agent team 该用哪个
子代理、技能、代理团队、工作流都能跑一个多步任务。区分它们的不是"哪个更强",而是一个更朴素的问题:这件事的计划握在谁手里(这是 Claude Code 官方文档给出的判据)。子代理是 Claude 派生出去的工作者,技能是 Claude 遵循的一套指令,代理团队是一个领头代理监督多个对等会话,工作流是运行时在后台执行的脚本。前三者里,Claude 自己是逐回合的编排者——它每一步决定下一个派生谁、分配什么,而每个返回的结果都会落进它的上下文窗口;工作流不一样,它把循环、分支、中间结果这套编排逻辑整个固化进脚本,Claude 的上下文最后只装一个最终答案。

记住这个判据,下面这张表的每一行就都能对上号。
| 原语 | 是什么 | 什么时候用 | 什么时候别用 | 成本 / 调试 |
|---|---|---|---|---|
| 工作流 Workflow | 运行时执行的脚本,编排逻辑写死在代码里 | 下一步取决于你刚发现什么——探索式、分阶段、要派很多代理 | 步骤都已确定、只是想并行跑快一点 | 成本最低、最好调试(脚本能读能改),但脚本层不并行 |
| 子代理 Subagent | Claude 用 Task 工具派生的独立实例,干完就退 | 你已经知道要做什么,只需要把活并行铺开 | 流程要随中间结果改道 | 成本中等,可并行 |
| 代理团队 Agent Team | 一个领头代理监督多个持久、专门化的对等会话 | 跨阶段、需要不同角色长期专门化协作的大工程 | 一次性的简单任务 | 能力最强,但设置最复杂、成本最高 |
| 技能 Skill | Claude 按需动态加载的指令、脚本、资源文件夹 | 你有一套可复用的领域知识或工具要打包给 Claude | 只是想省几次按键、没有真正可复用的东西 | 不是编排层,和上面三者不在一个维度 |
表里成本/调试这一列来自 MindStudio 对三种编排模式的横向对比:工作流成本最低、最容易调试,代价是脚本本身不并行;子代理成本中等、能并行;代理团队能力最强,但设置最复杂、成本也最高。
工作流和子代理最容易混,记一句话就够:下一步取决于你刚发现什么,用工作流;已经知道要做什么、只差并行去做,用子代理。子代理是临时且同质的——同一类活、喂不同输入、干完即退;代理团队成员是持久且专门化的,各有角色、可能各有配置,处理不同种类的工作。还有一个量级差异值得知道:据 Anthropic 工程师的说法,工作流能支持的代理数比子代理团队多 1 到 2 个数量级,而且工作按阶段半结构化地推进——这就是为什么大规模批量任务更适合走工作流,而不是攒一个代理团队。
技能根本不在"编排方式"这条线上。它是 Claude 通过渐进式披露动态加载的能力包:它先判断哪些技能跟当前任务相关,再按需把对应的指令和脚本读进来,避免一股脑塞满上下文。工作流回答"这些步骤怎么编排",技能回答"Claude 手上有什么能力可调"——一个是编排方式,一个是能力包,可以同时存在。Reddit 上一个流传较广的心智模型把三者边界说得很直白:工作流用于可重复的路径,代理用于不确定性,技能只在它真正打包了可复用的上下文或工具时才值得做,而不是只为省几次按键。技能是按需动态激活、在 Claude 各处都能用,而 Claude 项目(Projects)是始终加载的静态背景知识——别把这两个搞混。
两套口径在打架,先认出来再选
这里有个坑,很多人是被它绕晕的,不是被概念本身绕晕的。"工作流"这个词在社区里有两套互不兼容的语义。 Claude Code 官方、以及 MindStudio 这类跟着官方口径走的文章,把工作流当成一个独立的编排原语——它和子代理、技能、代理团队平级,就是上面那张表里的用法。但安全研究者 Daniel Miessler 提出的是另一套三层架构:技能是领域容器(放在 ~/.claude/skills/{领域}/),工作流是嵌套在技能内部 Workflows/ 目录里的任务程序,代理才是并行工作者。在他这套体系里,工作流不是和技能平级的东西,而是被装在技能里头的一个零件——Claude 把用户意图匹配到技能的 description(描述)字段,加载技能后再路由到对应的工作流。
两套口径都自洽,但混用就会让人彻底分不清"工作流到底和技能是平级还是从属"。判断很简单:你谈的是 Claude Code 里那个 /workflows 功能时,用官方口径(工作流是独立编排原语,就是本文从头到尾在讲的那个);只有读 Daniel Miessler 那套博客和模板时,才切到他的从属语义。认出你眼前的文章用的是哪套,比记住谁对谁错更要紧。
代理团队目前是 Claude Code 已发布但默认禁用的实验性功能,得手动开实验开关才能用。如果你在界面上找不到它,不是版本不对,是它默认就关着。
让 Claude 写一个 workflow,存下来当 /命令 反复用
决定用 workflow 之后,整条操作链是这样:让 Claude 写脚本 → 审批它规划的阶段 → 跑一遍 → 把这次运行存成命令 → 之后用 /名字 调用并传参。按这个顺序走一遍。
让 Claude 写脚本有两种入口。 一种是在提示里直接要——用自然语言把任务说清楚,加上 ultracode 关键词;另一种是设 /effort ultracode,之后这个会话里每个实质任务 Claude 都会先自动规划一个 workflow 再动手。两种方式在 Claude Code 的 workflows 文档里都有写。
脚本规划好之后,Claude 不会自己开跑。它先问你是否允许,提示长什么样取决于你的权限模式,批准提示里会把规划好的各个阶段列出来给你看。在一次实测里,脚本写好后 Claude 明确拒绝自动运行——因为这个 workflow 要在 20 个规格上改代码、动整个代码库,所以它要求作者显式敲命令启动。一个会改动整个仓库的脚本,应该是你主动按下的一次键,而不是聊天的副作用。这个设计就是用来挡「随口一句话把全仓库改了」的。
保存:两个位置,传参靠 args
跑出一次满意的运行后存下来:运行 /workflows,选中那次运行,按 s;在 Tab 键切换两个保存位置之间,按 Enter 存。之后它就以 /<名字> 出现,和 Claude Code 自带的那些 workflow 一样进 / 的自动补全列表。
两个保存位置区别要分清:
| 位置 | 路径 | 谁能用 | 可见性 |
|---|---|---|---|
| 项目级 | .claude/workflows/ | 克隆这个仓库的人都能用 | 随仓库共享 |
| 用户级 | ~/.claude/workflows/ | 你的每个项目都能用 | 只有你可见 |
同名时项目级优先——你给团队定的那份 workflow 会盖过你自己同名的个人版本。
存下来不等于写死。保存的 workflow 通过 args 参数接收输入,脚本里用一个名叫 args 的全局变量读它。调用时把研究问题、一串目标路径、或一个配置对象传进去,不用为每次运行去改脚本本身。同一个 workflow 这周对 src/auth 跑、下周对 src/billing 跑,传不同的 args 就行。
一个 workflow 脚本长什么样
脚本骨架很固定:一个 meta 块(写 name、description、phases),加一段把工作扇出去的正文。parallel(...) 对每个工作单元各起一个 agent() 并发跑。一个对每个文件并行处理的脚本大致是这个形状:
export const meta = {
name: "migrate-modules",
description: "把指定目录下每个模块迁移到新接口",
phases: ["discover", "build"],
};
// args 是调用时传进来的全局变量,比如 { dir: "src/auth" }
const files = await discover(args.dir);
// 对每个文件并发起一个 agent,各干各的
const results = await parallel(
files.map((file) =>
agent({
task: `迁移 ${file} 到新接口,跑测试确认通过`,
})
)
);
真写出来会复杂得多,但这个形状不变:meta 在顶上声明身份和阶段,正文用 parallel + agent 把活儿铺开。中间结果留在脚本变量里,不进你的对话上下文——这正是 workflow 区别于逐回合编排子代理的地方。
它能扛多大的活:一个完整实测
在 dev.to 上的一篇实测里,作者只用自然语言描述需求,Claude 就写出一个约 286 行、分 Discover/Understand/Plan/Build 四个阶段的脚本,去落地 20 个已批准的规格。脚本跑了约两小时、全程无人值守,产出一个真实的 26 文件改动集——新的 lib/social-* 模块、一次数据库迁移、schema 接线、打底测试。286 行脚本换两小时不用盯的工作,这个比例就是判断 workflow 值不值得起的锚点。
Claude Code 里自定义斜杠命令已经并入技能,现有的 .claude/commands/*.md 仍可用,推荐结构是 .claude/skills/<名字>/SKILL.md。所以你保存的 workflow 命令和技能命令同属一套斜杠命令体系,都用来把重复的提示或流程变成可复用的命令。
workflow 在底层怎么跑、有什么上限、要花多少 token
写出来、存下来之后,真正决定你敢不敢放它跑整个仓库的,是另外三件事:它在底层怎么动、有没有封顶、会不会失控烧钱。
脚本本身不碰你的代码。工作流运行时把脚本放进一个和你当前会话隔离的环境里执行,中间结果留在脚本变量里,不进 Claude 的上下文——这正是它和子代理逐回合编排的本质差别(工作流的上下文只装最终答案)。脚本自己也没有文件系统和 shell 访问权限:读文件、写文件、跑命令全由它派生的子代理做,脚本只负责协调这些代理。每个子代理实际走的执行路径,TrueFoundry 的实操指南拆得很清楚——读文件 → 解释任务 → 调用工具 → 打补丁 → 跑测试 → 观察输出 → 迭代或停止。
这里要把「隔离」分两层看,别混成一回事。被隔离的是脚本的运行环境——编排逻辑跑在和会话分开的运行时里;但脚本派生的子代理始终以 acceptEdits 模式运行、文件编辑自动批准,它们动的就是你工作目录里的真实文件,不是先在一份副本或沙盒里改完再合回来。所以「跑一半停掉会不会留下半改的文件」这个担心是成立的:中途停下时,已经完成的代理早把改动写进了真实文件,没轮到的代理则一行没动,工作区会停在一个部分改完的中间态(停了能不能接着跑、缓存怎么算,下面讲恢复机制时再细说)。真正要防的就是这个中间态本身,标准做法是先在干净的 git 工作区(或独立 worktree)里跑,万一中途崩了用版本控制一键回退,而不是指望运行时帮你回滚。
两条硬上限,记住就不会被一段失控脚本吓到。 单次运行最多 16 个并发代理(CPU 核数少的机器更少),一次运行总共最多 1000 个代理。这个上限不是摆设:运行时的代理上限本身就给单次运行能派生多少代理封了顶,所以哪怕脚本逻辑写飞了,成本也有天花板。
运行起来之后它基本不接受你插话。工作流跑的过程中没有中途输入,只有子代理弹出的权限提示能让你暂停一次运行;如果你的任务需要在阶段之间停下来人工签字确认,正确做法是把每个阶段拆成独立的工作流分开跑,而不是指望在一次运行里插断点。中途停了也不算白跑:在同一个 Claude Code 会话内可以恢复,已经完成的代理直接返回缓存结果、其余的实时接着跑——但前提是别退出 Claude Code,一旦退出,下次会话只能从头开始。
计划、权限和监控
谁能用、用的时候权限怎么走,一张表说清:
| 维度 | 具体规则 |
|---|---|
| 可用计划 | 所有付费计划(Pro / Max / Team / Enterprise)都能用,也支持 Anthropic API、Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundry |
| Pro 计划的坑 | Pro 上默认不开,要去 /config 里 Dynamic workflows 那一行手动打开,否则触发不了 |
| 子代理权限 | 派生的子代理始终以 acceptEdits 模式运行、继承你的工具白名单,文件编辑自动批准,和你会话本身的权限模式无关 |
| 仍会弹提示 | 不在白名单里的 shell 命令、web fetch、MCP 工具,运行中照样会弹确认提示 |
监控用 /workflows。它列出运行中和已完成的工作流,进度视图按阶段显示代理数、token 总量和耗时;键盘上 p 暂停或恢复、x 停止选中代理或整个工作流、r 重启选中的运行中代理、s 把这次运行的脚本存成命令(保存的完整步骤前面写脚本那节讲过)。每次运行还会把脚本写到会话目录下 ~/.claude/projects/ 里的一个文件,Claude 在运行开始时就拿到路径——你可以打开它读 Claude 写的编排逻辑、和上次运行的脚本做 diff,或者改完让 Claude 从修改版重新启动。脚本是真能读能改的代码,不是不可追溯的实现。
token 怎么算、怎么控
先认清一个事实:工作流会派生很多代理,所以单次运行很可能比你在对话里做同一件事用明显更多的 token,而且这些用量照常计入你计划的额度和速率限制。并行尤其放大成本——10 个代理并行跑,大约就是一个顺序代理的 10 倍花销,N 个并行约等于 N 倍 token。
控成本不靠猜,靠三个动作:
- 先在小切片上跑一遍估花销。 官方建议很直接:别一上来就整个仓库,先挑一个目录、一个窄问题跑,运行中
/workflows视图会实时显示每个代理的 token 用量,看清楚一次小规模运行在你的代码库上花多少钱,再决定要不要放大。随时停,已经完成的工作不会丢。 - 按阶段路由小模型。 工作流里每个代理默认用你会话的模型,除非脚本把某个阶段路由到别的。大型运行前先
/model检查一下,描述任务时直接让 Claude 对那些不需要最强模型的阶段(比如简单的文件读取、格式整理)换更小的模型。落到操作上有两条路,优先走第一条:让某阶段降级到 Haiku,最省事的是在描述任务时用自然语言点名——「discover 阶段只是读文件列清单,用 Haiku;build 阶段动代码,保持 Opus」,Claude 写脚本时就会把对应阶段的模型设进去,你不用碰代码。第二条是脚本生成之后再调:模型是agent()选项对象里的一个字段,打开~/.claude/projects/下那份脚本,把对应阶段agent()调用里的模型参数改成 Haiku,再让 Claude 从改过的版本重启。一句话描述能搞定的就别去手改脚本,自然语言点名是默认做法,改参数是它没按你意思分配时的兜底。 - 靠代理上限兜住极端情况。 哪怕前两条都没做,前面说的 1000 个代理运行时上限也给失控脚本封了顶——这是底线,不是日常控成本的手段。
成本失控到什么程度才算翻车、极端案例有多夸张,留到后面避坑那节一起说,那里冲击更直接;这里你只要记住一句:在 workflow 上,成本本身也是一种需要先估再跑的风险,截至 2026 年 6 月,控它的全部办法就是上面这三条加那两条硬上限。
五种工作流模式:官方命名和实操命名怎么对上
读 Anthropic 的文章你会看到一套模式名,去 MindStudio 这类实操博客又是另一套名,词对不上,很容易以为是两批东西。其实大半是同一个东西换了说法。Anthropic 的《Building Effective AI Agents》总结了五种工作流模式:提示链(prompt chaining)、路由(routing)、并行化(parallelization)、编排者-工作者(orchestrator-workers)、评估者-优化者(evaluator-optimizer)。MindStudio 的实操盘点给的是另一套:顺序流(Sequential Flow)、编排者(Operator)、拆分合并(Split-and-Merge)、代理团队(Agent Teams)、无头(Headless)。
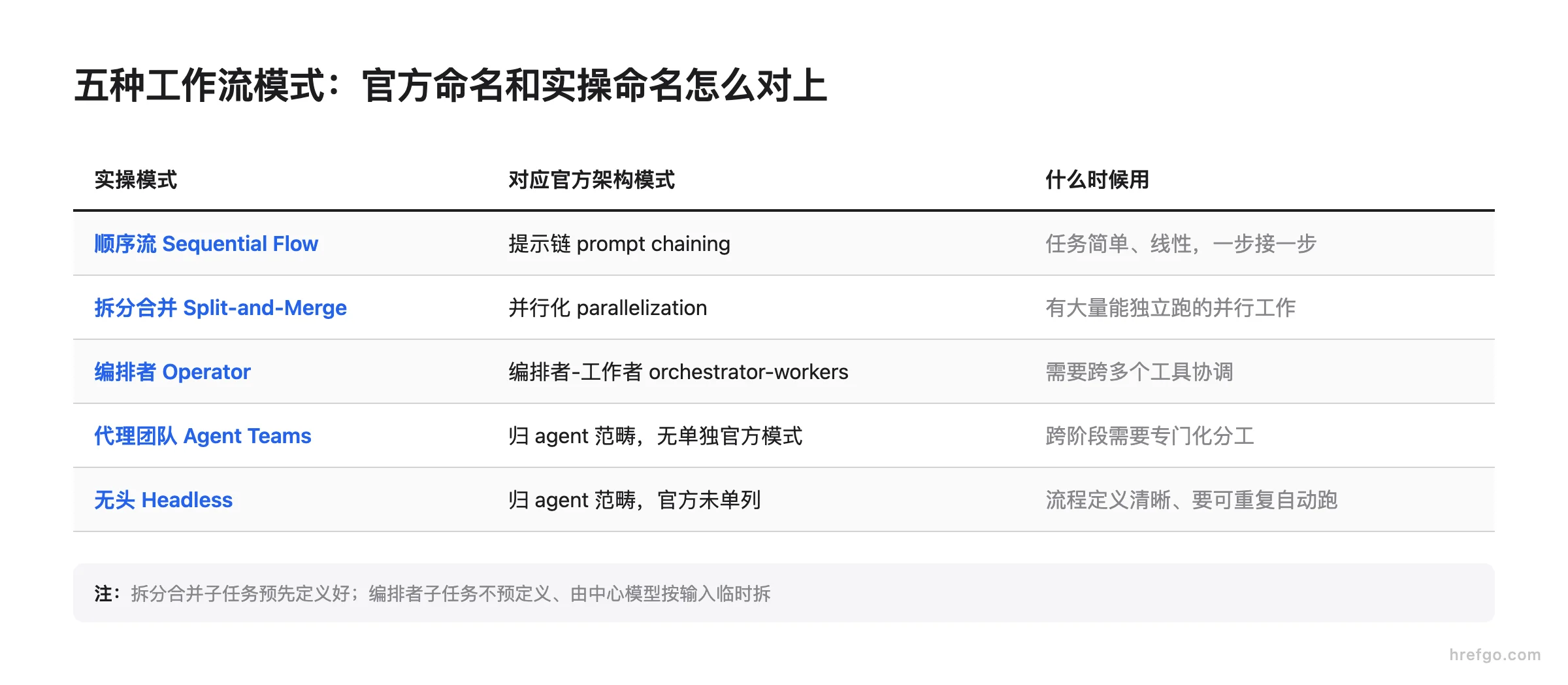
下面这张表把两套名对齐,再给每个模式一句"什么时候用"。
| 实操模式 | 对应官方架构模式 | 什么时候用 | 内部机制 |
|---|---|---|---|
| 顺序流 Sequential Flow | 提示链 prompt chaining | 任务简单、线性,一步接一步 | 每个调用处理上一步的输出,可审计、好调试 |
| 拆分合并 Split-and-Merge | 并行化 parallelization | 有大量能独立跑的并行工作 | 两个变体:sectioning 拆独立子任务并行,voting 同任务多跑取共识 |
| 编排者 Operator | 编排者-工作者 orchestrator-workers | 需要跨多个工具协调 | 中心模型动态拆解任务、派给工作者、再综合 |
| 代理团队 Agent Teams | (归 agent 范畴,无单独官方模式) | 跨阶段需要专门化分工 | 多个持久专门化成员,常嵌在更大的编排者系统里 |
| 无头 Headless | (归 agent 范畴,官方未单列) | 流程定义清晰、要可重复自动跑 | 用 CLI 的 --print 标志,或脚本管道喂输入捕获输出 |
官方那套里的评估者-优化者在 MindStudio 的实操五模式里没有单独对应项——它是"一个模型出结果、另一个模型评估并要求改进"的循环,落到实操层往往被并进编排者或代理团队里实现,不单算一种。这也说明两套命名不是一一对齐的,对照表只能解决大部分撞名,不能强行凑满五对五。
顺序流是合理的默认选择:简单、可审计、出问题时容易定位。但它有明确的失效边界——当任务结构会变(下一步取决于刚发现什么)、或某些步骤其实能安全并行时,硬用顺序流就是浪费。这两种情况分别是编排者和拆分合并的主场。
需要分清拆分合并和编排者这两个最容易混的:拆分合并的子任务是预先定义好的,你已经知道要并行跑哪几块;编排者-工作者里子任务不预先定义,由中心模型根据具体输入临时拆解再分派——这是两者的关键区别。另外路由这个动作值得单提一句:它对输入先分类,再把简单常见的问题导向 Claude Haiku 4.5 这类更小更省钱的模型,把困难罕见的导向 Claude Sonnet 4.5 这类更强的,本身就是一种省成本的编排手段(截至 2026 年 6 月的模型分层)。
**这些模式不互斥,复杂项目几乎都是组合用的。**顶层挂一个编排者,某个阶段跑拆分合并并行,另一个阶段走顺序流水线,代理团队常常嵌在更大的编排者系统里当其中一环。别把"选一种模式"理解成单选题。代理团队目前是实验性功能、默认禁用(启用方式前文已说明),用之前确认它开着。
代理团队最能说明问题的落地是 dbt 仓库迁移:一位用户用 Agent Teams 把一个 500 多个文件的 dbt 仓库整合进现有仓库,原本估计 6 个月的活,几周内完成了大部分。能这么快是因为每个迁移任务虽然繁琐但相当重复——分析源仓库代码、对比目标仓库、重构两边产出相同数据模型,再重复。重复且可拆正是代理团队/拆分合并的甜区,任务越是这种形状,并行编排的收益越大。
反过来,别一上来就堆复杂度。Anthropic 自己的建议是先找最简单的方案、只在需要时才加复杂度——很多场景一次大语言模型调用配上检索和几个上下文示例就够了,根本不必搭代理式系统。模式表是给"确实需要编排"的任务用的,不是让你给每个任务都套一层。
不动用完整 workflow 的日常配方
大多数日子里你用不到一段几百行的脚本。一个跨几个文件的功能、一次依赖升级、一段得先摸清楚再改的代码,靠几条命令加一套固定打法就能搭出一条靠谱的工作流。下面这组可以直接照敲,对应官方在 Common workflows 里列的日常做法:用 @ 引用文件和目录、写之前先走计划模式、把探索委派给子代理、用 worktree 跑并行会话、把 Claude 接进脚本。
# 计划模式:Claude 只读文件、提出计划,批准前不动手
claude --permission-mode plan
# 会话中途也能切——按 Shift+Tab 切入计划模式
# worktree 并行:在隔离的 git worktree、独立分支上开会话,互不冲突
claude --worktree feature-auth
# 第二个终端换个名字跑同样命令,就是一个并行会话
claude --worktree fix-billing
# 恢复会话
claude --continue # 恢复当前目录最近一次会话
claude --resume # 打开交互式选择器,自己挑
委派研究是这套配方里最容易被低估的一条。在 prompt 里写「use a subagent to investigate how our auth system handles token refresh」,子代理在它自己的上下文窗口里读文件,只把一段摘要带回来——主上下文不会被一大堆源码塞满。VS Code 扩展还提供检查点:把鼠标悬停在任意一条消息上会冒出 rewind 按钮,可以 fork 对话、只回退代码、或者 fork 加回退一起来,相当于给改动加了个后悔药。
plan mode 拦的是哪一类错
这里要把两个容易混的东西分开。计划模式拦的错,和工作流跑起来后那些逐次弹出的审批提示拦的错,根本不在同一层。
计划模式在你动手前把整套行动计划摆出来,全程只读不改。它拦的是架构层和范围层的错——选错了依赖、改动范围比你预期的大、和现有接口对不上。这些是写下第一行代码前就该改方向的事。工作流的审批提示是逐次运行(per-run)或逐个动作级的:它展示规划好的各阶段,运行中的代理再就具体操作弹权限提示,拦的是执行层的事,比如白名单外的 shell 命令、网络抓取、MCP 调用。
判断标准很直接:非琐碎的任务先走计划模式,只有范围一目了然的小改动,才直接靠审批提示往前走。这是多数有经验用户的共识。
三条从一线攒出来的实战配方
下面这三条不在官方文档里,来自具名开发者在真实项目里的复盘,比上面的命令清单更值得照着改自己的习惯。
构建前先做一段架构对话。 iQuantumDigital 的做法是:动手写任何新功能前,花 10 到 15 分钟用纯自然语言把「要做什么、有哪些约束、已有什么条件」讲给 Claude 听。在他的工作流里,这个习惯比任何其他单一实践都更能在问题变贵之前把它抓住——问题留到代码里再发现,返工成本是另一个量级。
在 CLAUDE.md 里给子代理设一条扩容规则。 比如写「根据任务最少 2 个、最多 5 个子代理」(dev.to 上的实战记录)。这条规则显著改善了任务拆解和并行化,每个子代理也能更专注在更小、更专门的子任务上。
投入的 /plan 阶段配测试驱动开发(TDD)。 一位主任级工程师的经验是:把计划阶段当真来回打磨、把假设都暴露出来,再用测试驱动开发的方式实现,多数情况下能拿到 100% 可用、符合预期的代码,复杂功能甚至重写都能一次跑通。前面那条「先做架构对话」其实是这条的前置——计划阶段越扎实,实现阶段越省事。
上下文管理是这套配方的可靠性底座
工作流跑得稳不稳,很大程度取决于你怎么管上下文。三条铁律:用 /context 把上下文占用可视化出来,看清楚还剩多少;在里程碑处刻意 /compact,别等它自动压缩;一个会话只聚焦一个大目标。一个经验阈值是,超过约两个 compact 周期后,模型容易开始给含糊回答和幻觉——到这个点就该开新会话了。
这条铁律也是判断「日常配方什么时候该升级成完整 workflow」的信号。一位 HN 用户的看法是:对任何比一次性拉取请求(PR)更大的工作,光为了更好的自动上下文管理,就值得起一个工作流——更多工作发生在上下文前 20% 的「甜区」里。换句话说,当你发现一个会话里不停 /compact、还是压不住上下文漂移,那就不是再加一条日常命令能解决的,该让 Claude 把这套流程写成脚本(怎么写、怎么存,前面已经讲过)。
workflow 翻车都翻在安静的地方
workflow 出问题,几乎从不是「报错红了一片」那种好认的失败。TrueFoundry 在生产环境里总结得很直白:Claude Code 通常不会写出一眼能看出烂的代码,它是安静地失败——编辑看着合理但有个微妙的错、改动能通过测试却偏离了你真正的意图、推理在运行途中悄悄漂移而没有任何明显信号。正因为没报错,才危险。
往下还有几个连环的坑,越往后越难发现:
- 上下文丢了,但模型不告诉你。 随着工具输出和补丁不断累积,上下文窗口被填满,有东西被悄悄丢掉,模型继续往下推理——只是依据的已经是另一幅内部图景了(TrueFoundry)。
- 幻觉式改动溜过评审。 生成的补丁里调用了不存在的对象、引入了根本不需要的依赖,而这种 diff 偏偏读起来太干净、格式像正确代码,所以反而最容易被评审放过。
- 同一任务跑两次,结果会发散。 两次运行之间上下文和工具输出略有不同,模型走了不同路径,可重复性差是个被低估的运营问题——一旦工作流触及承重代码(load-bearing code,被很多地方依赖、改坏了波及一大片的核心代码),这点就很要命。
- 劣质代码债(slop debt)越攒越多。 HN 上多位有经验的开发者的观察:大语言模型会累积劣质代码债,每多过一遍代理只是放大它、不是修复它,所以在承重代码上不加质量门就让它自主跑,很冒险。
成本也是一种翻车,而且翻得更响。Anthropic 自己的工程师都承认,动态工作流消耗的用量明显高于典型会话。社区里有人单个 prompt 烧掉 70 万到 120 万 token,干脆把它叫成「ultra-token-consumption mode」(超级烧 token 模式)。更具体的一例:一位 Max 5x 计划用户起了 62 个 Opus 4.8 子代理,约 18 分钟就把大约 5 小时的用量上限跑满了,下一次只能想办法改用 Haiku 或 Sonnet(HN 用户自述,截至 2026 年 6 月)。
想拿这个例子对照自己的任务规模,先泼一盆冷水:这位用户只报了代理数(62 个)、耗时(18 分钟)和打满的额度(约 5 小时),没说对应多少文件、多少行改动——这个换算关系他没公开,社区也没人补出来,所以别拿一个编出来的「62 个代理≈多少文件」去套自己的活,那个数没有出处。能拿来对照的是另一头:决定花销的是代理数和每个代理用的模型,不是文件数本身。同样 62 个代理,全用 Opus 跑和换 Haiku 跑,账单能差出一个量级(前面说过 N 个并行约等于 N 倍 token,再叠加单个代理的模型单价)。所以与其猜「我这 40 个文件会不会也烧这么多」,不如直接照前面运行机制那节的办法:先在一个目录的小切片上跑一遍,盯住 /workflows 里每个代理的实际 token 用量,用真实数字往全量上线性外推,比拿别人没头没尾的代理数硬套靠谱得多。这里只强调一句:把成本当成翻车的一种,没估过就别放它跑整个仓库。
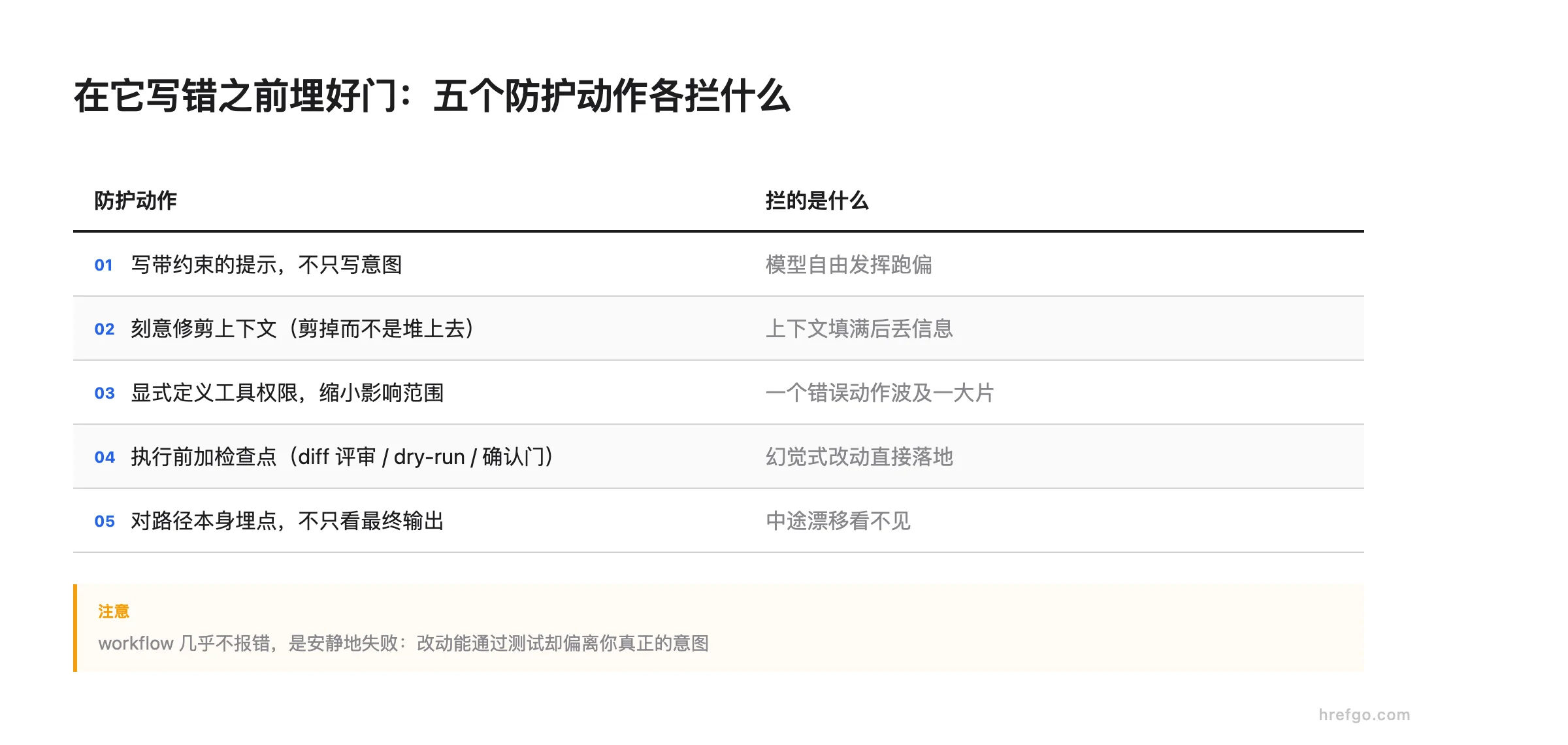
在它写错之前埋好门
防护的核心思路是:别指望事后看出问题,要在执行前和交接处设卡。TrueFoundry 给的五条生产实践可以照搬——
| 防护动作 | 拦的是什么 |
|---|---|
| 写带约束的提示,不只写意图 | 模型自由发挥跑偏 |
| 刻意修剪上下文(剪掉而不是堆上去) | 上下文填满后丢信息 |
| 显式定义工具权限,缩小影响范围 | 一个错误动作波及一大片 |
| 执行前加检查点(diff 评审 / dry-run / 确认门) | 幻觉式改动直接落地 |
| 对路径本身埋点,不只看最终输出 | 中途漂移看不见 |
官方文档还提到一招能堵住最隐蔽的崩溃点:用 schema(约定好的数据结构)强制每个代理返回校验过的 JSON。多步运行里最容易出事的地方就是代理之间用自由文本交接,schema 把这个口子焊死,避免一步悄悄崩了、后面全跟着错还看不出来。
更实战的几条来自一线。HN 上的开发者的常用手法是让 Claude 派生三个评审子代理,每个都带着「刚才发生了什么」的上下文,用更新鲜的视角把所有改过的代码再查一遍、专挑严重问题;官方也支持把这做成可重复的质量模式——让独立代理在汇报前对彼此的发现做对抗式评审,或从多个角度起草计划再相互权衡,结果比单遍可信得多。想更彻底,就把质量门固化成技能:架构规则技能(配静态分析、架构测试、linting)、测试规范技能、从代码生成验收标准的技能、核对工单目标和实际交付是否一致的技能——一套写好,每次流水线都自动跑。lint 也别只当格式工具用,通过 hook 在每次编辑后跑一遍 linter 把反馈喂回模型,并在规则里写清「为什么这是问题」,相当于给模型设了约束。面向更自主的运行,MindStudio 总结的四层是底线:限工具权限、不可逆操作前加确认、构建会大声失败的显式错误状态、生产前先在沙盒里充分测。
一条比所有技巧都重要的铁律
永远不要在你无法批判性阅读的领域里直接落地 AI 产出——先用它学这个领域,理解之后再实现,这是 iQuantumDigital 那条规则的核心。
为什么这条压过所有防护技巧,被官方当样板的那个 Bun-to-Rust 移植就是反面教材。它在社区被严厉批评:连最基本的 Rust miri 检查都没过、允许未定义行为,一位 Rust 开发者直接称它是见过的最不可靠(unsound)的代码库之一,整个改写涉及约 13255 行带 unsafe、且没有注释的 Rust 代码。量级很唬人,但如果你读不懂这些 unsafe 在做什么,再多评审子代理也只是在用你看不懂的视角审你看不懂的代码。
所以真要上手,顺序别反:先挑一个你自己能批判性读懂产出的任务,在小切片上跑一遍,盯住 /workflows 里每个代理的 token,确认产出你读得懂、认得对,再决定要不要放它跑大的。workflow 能把计划搬进代码,但判断对错搬不进去,先确认你看得懂手上这一份产出,再去放大规模。
现在就跑一个最小的试试
打开 Claude Code(确认版本不低于 v2.1.154,Pro 计划先去 /config 把 Dynamic workflows 这一行开起来),挑一个你手头跨多个文件、一轮对话搞不定的真实任务,但先别拿整个仓库上:在 prompt 里描述任务并加上 ultracode 关键词,让 Claude 只在一个目录这个小切片上规划并跑一遍 workflow;运行时打开 /workflows 盯住每个代理的 token 用量,用这一次小规模运行先摸清它在你的代码库上花多少钱、产出能不能批判性读懂,再决定要不要放它跑整个任务。
FAQ
Does Claude do workflows?Claude 支持工作流吗?
支持,原生内置。Claude Code 的动态工作流功能通过在提示里加 ultracode 关键词或 /effort ultracode 触发,Claude 会为你的任务写一段 JavaScript 脚本、在后台编排多个子代理去执行。要求 Claude Code v2.1.154 或更高,Pro 计划用户还需在 /config 里手动开启 Dynamic workflows 这一行。
How to make a Claude workflow?怎么创建一个 Claude workflow?
描述任务时加上 ultracode 关键词,Claude 就会写一个工作流脚本,展示规划好的阶段并要求你显式批准后才开始执行。跑完一次满意的运行之后,在 /workflows 里选中它按 s 保存成 /<名字> 命令,之后反复调用。脚本结构是 meta 块 + parallel / agent 调用,具体骨架上面代码块里有展示。
Claude 能生成流程图吗(create a flowchart)?
能,但这和本文的「workflow(工作流脚本)」是两码事。让 Claude 用 Mermaid 语法写一段文本,再粘到任意支持 Mermaid 的渲染工具里就能出图——Claude 官方资源里也用 Mermaid Chart 连接器把图转成可编辑格式(这类渲染工具是通用兼容方案,不是 Claude 官方指定的某一个)。Claude Code 本身的 /workflows 功能是用来编排代码任务的,和可视化绘图无关。
Claude workflow 用什么计划、要花多少钱?
所有付费计划都可用(Pro $20/月、Max $100/月起)。Pro 需在 /config 手动开启,Max 的用量上限明显更高,适合要跑大型工作流的场景。这些计划覆盖你通过 Claude Code 构建时产生的大语言模型用量——这是和按调用付费的工具相比的主要优势。作为对照,n8n cloud 起步每月 24 美元含 2500 次执行,但大语言模型 API 调用费另算;Claude Code 订阅价里已经把模型成本包进去了。工作流单次运行 token 消耗明显高于普通对话,高用量场景下 Max 20x($200/月)才是更合适的档位(具体消耗量级和怎么控,详见上方 §token 怎么算、怎么控)。
动态工作流为什么会在我不知情时自动启动、怎么彻底关掉?
/effort ultracode 开启后,Claude 对当前会话里的每个实质性请求都会先做一轮内部预评估,达到一定条件就静默接管、自动走工作流,不单独弹出询问。有用户观察到上下文超过约 50% 时会触发这种切换,但官方并没有把它写成一个固定阈值,实际表现可能因版本而异。
要彻底关掉,有以下几种方式(用完一次大任务后用 /effort high 退回常规模式是最轻量的临时做法,不用改配置):
- 在
/config里关掉 Dynamic workflows 这一行 - 在用户级
~/.claude/settings.json里设disableWorkflows: true(管你所有项目),或在项目级.claude/settings.json里设(只管这个项目) - 设置环境变量
CLAUDE_CODE_DISABLE_WORKFLOWS=1 - 组织级管理员可在 managed settings 里设
disableWorkflows: true,在组织范围内统一关闭
这几种关法冲突时有明确的先后。官方规则是同一项行为环境变量盖过 settings 字段——所以你在项目里设了 disableWorkflows: false、环境变量又设了 1,最终以环境变量为准,工作流是关的。只想这一个项目关、别的项目照常用,就把 disableWorkflows: true 写进这个项目的 .claude/settings.json,别用环境变量(环境变量跟着 shell 走,会一刀切影响你所有会话)。
现成的工作流工具和社区配方库在哪找?
官方内置的 /deep-research 工作流开箱可用,给它一个问题就能并行搜网、交叉核对来源、过滤未经核实的结论,不需要任何配置。社区工具方面,shinpr/claude-code-workflows 是覆盖需求、设计、实现、质检全流程的端到端插件,通过 /plugin marketplace add shinpr/claude-code-workflows 安装;awesome-claude-code-workflows 是社区整理的配方库,收录了钩子、MCP 服务器、技能和 CLAUDE.md 组合。想从更多角度理解工作流原理,alexop.dev 的文章从确定性控制流的视角把通用形态总结成「扇出→聚合→综合」,读完更容易看懂各个工具在做什么。
同样是大规模迁移,凭什么 286 行那个用 workflow、500 文件 dbt 那个用 agent team?
判据不是文件多少,是任务形状。286 行那个实测要落地 20 个已批准的规格,每个规格做什么、彼此怎么依赖在动手前并不完全清楚,下一步取决于上一步发现了什么——这种「边走边定」正是工作流的主场,把分阶段的探索固化进脚本最划算。500 文件的 dbt 仓库迁移不一样:每个迁移任务繁琐但高度重复(分析源仓库、对比目标仓库、重构成相同数据模型,再重复),角色固定、可以拆成持久专门化的工作者长期协作,这是代理团队的甜区。还有个量级因素:据 Anthropic 工程师的说法,工作流能撑的代理数比子代理团队多 1 到 2 个数量级,纯批量、可并行的活更适合走工作流。你那 40 多个文件的框架迁移该照哪个,先问一句:每个文件的改法是不是基本同构、动手前就清楚?是,按规模和并行需求起一个 workflow(顺带拿到更好的自动上下文管理);如果改法因文件而异、需要不同角色长期专门化盯着,才值得搭代理团队(注意它默认禁用,得先开实验开关)。
工作流脚本里 schema 怎么写、绑在 agent() 的哪个参数上?
绑在 agent() 的第二个参数(选项对象)上,签名是 agent(prompt, { schema, ... })。传进去之后,子代理被强制调用结构化输出工具、在工具调用层做校验,返回的不匹配就自动重试,最后 agent() 直接返回一个符合该 schema 的已校验对象,省掉你手动解析自由文本。一个最小例子:
const ITEM_SCHEMA = {
type: "object",
properties: {
file: { type: "string" },
migrated: { type: "boolean" },
notes: { type: "string" },
},
required: ["file", "migrated"],
};
const results = await parallel(
files.map((file) =>
agent(`迁移 ${file} 到新接口,跑测试确认通过`, {
phase: "build",
schema: ITEM_SCHEMA,
})
)
);
注意上面正文那个脚本骨架为了讲清结构用了简化的 agent({ task }) 写法,真要绑 schema 时按这里的 agent(prompt, { schema }) 形式来。多步运行最容易在代理之间用自由文本交接的地方悄悄崩,schema 把这个口子焊死。