
HTML的编写方式决定了用户看到什么以及搜索引擎如何解释网页。一个有效、格式良好的HTML页面还可以减少搜索引擎对结构化数据、元数据、语言或编码的误解。
本文的数据基于从排名前20的谷歌结果中收集的大约800万个页面和这些页面包含3000多万个关键词,我们将讨论谷歌如何理解的元标签、JSON-LD结构化数据、语言检测、标题使用、社交链接、AMP等。
谷歌理解的元标签
当谈到作为流量来源的主要搜索引擎时,主要指谷歌,Duckduckgo最近获得了关注,Bing则几乎可以忽略。
因此,在本节中,我们将只关注谷歌在搜索控制台帮助中心列出的元标签。
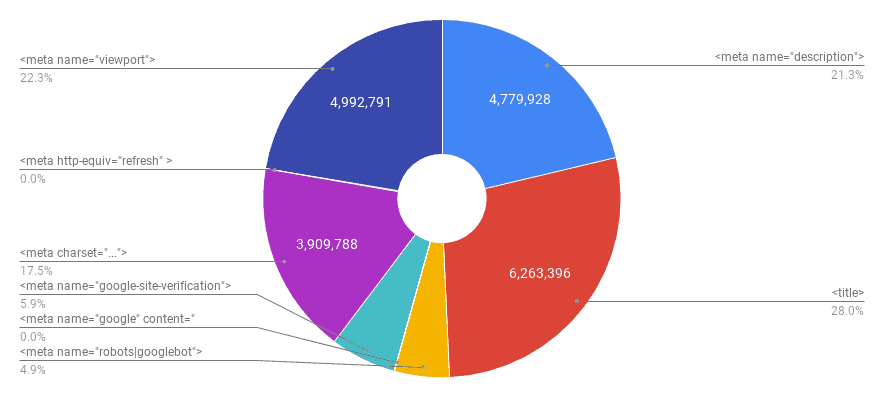
描述标签是一个约150个字符的片段,用来总结页面的内容。当搜索短语包含在描述中时,搜索引擎会在搜索结果中显示元描述。
| 选择器 | 总数 |
|---|---|
<meta name="description" content="*"> (任意描述) | 4,391,448 |
<meta name="description" content=""> (描述为空) | 374,649 |
<meta name="description"> (无描述) | 13,831 |
在极端情况下,我们发现内容小于30个字符的元元素有685,341个,内容文本大于160个字符的元元素有1,293,842个。
这是搜索引擎优化方面最重要的两个HTML标签之一。根据W3C,这也是必须的,这意味着缺少标题标签的页面是无效的。
研究表明,如果您将标题保持在合理的60个字符以内,那么您可以期望在SERP中正确地呈现标题。过去,有迹象表明谷歌的搜索结果标题长度延长了,但这不是永久性的改变。
考虑到上述所有因素,在我们发现的完整6,263,396个标题中,有1,846,642个标题标签似乎太长(超过60个字符),1,985,020个标题的长度被认为太短(30个字符以下)。
[caption id="attachment_1452" align="aligncenter" width="884"]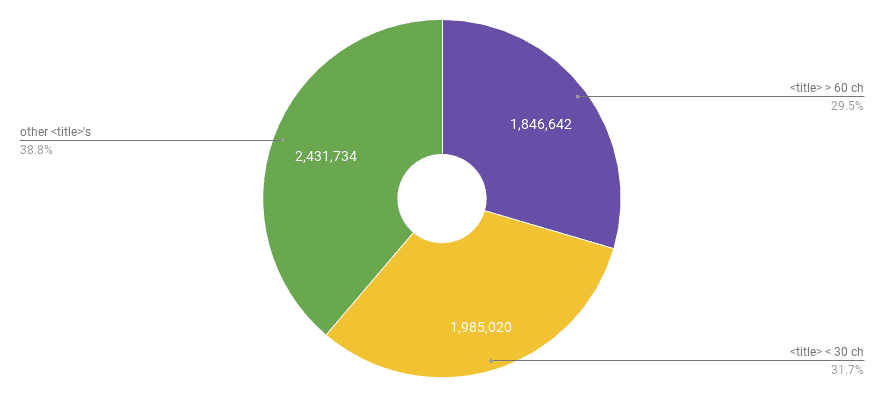 显示标题标签长度分布的饼图,长度小于30个字符为31.7%,长度大于60个字符约为29.5%[/caption]
标题太短应该不成问题——毕竟,这是一件主观的事情,取决于网站业务。意义可以用更少的单词来表达,但这绝对是浪费优化机会。
显示标题标签长度分布的饼图,长度小于30个字符为31.7%,长度大于60个字符约为29.5%[/caption]
标题太短应该不成问题——毕竟,这是一件主观的事情,取决于网站业务。意义可以用更少的单词来表达,但这绝对是浪费优化机会。
| 选择器 | 总数 |
|---|---|
<title>*</title> | 6,263,396 |
缺少<title>标签 | 1,285,738 |
另一个有趣的事情是,在谷歌第1-2页排名的网站中,351,516个(约占总数750万的5%)在索引页面上使用相同的标题文本和h1。
此外,您是否知道使用HTML5,您只需要指定HTML5文档类型和标题,即可拥有一个完全有效的页面?
<!DOCTYPE html> <title>red</title>
<meta name="robots|googlebot">
这些元标签可以控制搜索引擎爬行和索引的行为。robots元标签适用于所有搜索引擎,而“Googlebot”元标签特定于谷歌。
| 选择器 | 总数 |
|---|---|
<meta name="robots" content="..., ..."> | 1,577,202 |
<meta name="googlebot" content="..., ..."> | 139,458 |

带有元机器人及其内容参数的HTML片段。
因此,robots元指令为搜索引擎提供了如何爬行和索引页面内容的说明。撇开Googlebot元计数有点低不谈,我们很想知道最常见的robots参数,因为一个巨大的误解是你必须在HTML的中添加机器人元标签。以下是前5名:
| 选择器 | 总数 |
|---|---|
<meta name="robots" content="index,follow"> | 632,822 |
<meta name="robots" content="index"> | 180,226 |
<meta name="robots" content="noodp"> | 115,128 |
<meta name="robots" content="all"> | 111,777 |
<meta name="robots" content="nofollow"> | 83,639 |
<meta name="google" content="nositelinkssearchbox">
当用户搜索您的网站时,谷歌搜索结果有时会显示特定于您网站的搜索框,以及指向您网站的其他直接链接。这个元标签告诉谷歌不要显示网站链接搜索框。
| 选择器 | 总数 |
|---|---|
<meta name="google" content="nositelinkssearchbox"> | 1,263 |
不出所料,当网站出现在搜索结果中时,没有多少网站选择明确告诉谷歌不要显示网站链接搜索框。
<meta name="google" content="notranslate">
当用户搜索您的网站时,谷歌搜索结果有时会显示特定于您网站的搜索框,以及指向您网站的其他直接链接。这个元标签告诉谷歌不要显示网站链接搜索框。
在某些情况下,可能不希望将您的内容提供给更大的用户群体。正如上面谷歌支持答案中所说,这个元标签告诉谷歌,你不希望他们为这个页面提供翻译。
| 选择器 | 总数 |
|---|---|
<meta name="google" content="notranslate"> | 7,569 |
<meta name="google-site-verification" content="...">
您可以在网站的顶层页面上使用此标签来验证搜索控制台的所有权。
| 选择器 | 总数 |
|---|---|
<meta name="google-site-verification" content="..."> | 1,327,616 |
在我们讨论这个问题时,您是否知道,如果您是Google Analytics属性的已验证所有者,Google现在将在搜索控制台中自动验证。
这定义了页面的内容类型和字符集。
这基本上是好的元标签之一。它定义了页面的内容类型和字符集。考虑到下表,我们注意到,我们分析的索引页面中只有大约一半定义了元字符集。
| 选择器 | 总数 |
|---|---|
<meta charset="..."> | 3,909,788 |
<meta http-equiv="refresh" content="...;url=...">
此元标签在一段时间后将用户发送到新的URL,有时用作简单的重定向形式。
最好使用301重定向而不是元刷新来重定向您的网站,特别是当我们假设30次重定向不会丢失PageRank时,W3C建议不要使用此标签。谷歌也不喜欢,建议您改用服务器端301重定向。
| 选择器 | 总数 |
|---|---|
<meta http-equiv="refresh" content="...;url=..."> | 7,167 |
在我们解析的750万个索引页面中,我们发现了有7,167页使用了上述重定向方法。作者并不总是能控制服务器端技术,显然他们使用这种技术是为了在客户端启用重定向。
<meta name="viewport" content="...">
此标签告诉浏览器如何在移动设备上渲染页面。出现此标签向谷歌表明,该页面对移动设备友好。
| 选择器 | 总数 |
|---|---|
<meta name="viewport" content="..."> | 4,992,791 |
从2019年7月1日开始,所有网站都开始使用谷歌的移动优先索引。Lighthouse检查文档顶部是否有元名称="viewport"标签,因此无论您使用什么框架或CMS,此元都应出现在每个网页上。
考虑到上述情况,我们预计会有更多的网站在标题部分使用有效的meta name="viewport",而不是被分析的750万个索引页面中的4,992,791个。
设计移动端友好型网站可确保您的页面在所有设备上运行良好,因此请确保您的网页对移动设备友好。
<meta name="rating" content="..."/>
将页面标签为包含成人内容,表明该页面已被安全搜索结果过滤。
| 选择器 | 总数 |
|---|---|
<meta name="rating" content="..."/> | 133,387 |
此标签用于表示内容的成熟度评级。直到最近,它才添加到谷歌理解的元标签列表中。查看凯特·莫里斯关于如何标记成人内容的文章。
JSON-LD结构化数据
结构化数据是一种标准化格式,用于提供有关页面的信息并对页面内容进行分类。结构化数据的格式可以是Microdata、RDFa和JSON-LD——所有这些都有助于谷歌了解您的网站内容,并为您的页面触发特殊的搜索结果功能。
在本节中,我们将仅使用JSON-LD(链接数据的JavaScript对象符号)来收集结构化数据信息。无论如何,这是谷歌建议的,以提供有关网页含义的线索。
关于这一点的一些有用部分:
- 在谷歌I/O 2019上,宣布结构化数据测试工具将被富结果测试工具取代。
- 现在,Googlebot使用最新的Chromium而不是旧的Chrome 42索引网页,这意味着您还可以通过结构化数据支持来缓解过去可能遇到的SEO问题。
- Jason Barnard在2019年伦敦SMX上就谷歌搜索排名的工作原理进行了有趣的演讲,根据他的理论,我们可以依靠七个排名因素;结构化数据绝对是其中之一。
- Builtvisible的Microdata、JSON-LD和Schema.org指南包含您需要了解的关于在网站上使用结构化数据的所有信息。
- 这是亚历克西斯·桑德斯为初学者编写的JSON-LD指南。
- 最后一点也很重要,在官方JSON for Linking Data网站上有很多文章、演示文稿和帖子可以深入探讨。
高级Web排名的HTML研究仅依赖于分析索引页面。有趣的是,尽管指南中没有说明,但谷歌似乎并不关心索引页面上的结构化数据,正如几年前加里·伊利埃斯在Stack Overflow中所述。而在谷歌理解的JSON-LD结构化数据类型上,我们总共发现了2,727,045个特性:
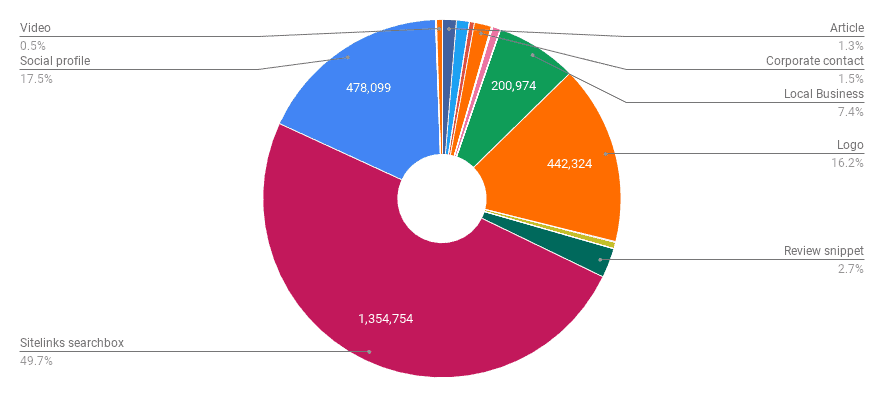
饼图显示谷歌理解的结构化数据类型,Sitelinks搜索框为49.7%——最高值。
| Article | 35,961 |
|---|---|
| Breadcrumb | 30,306 |
| Book | 143 |
| Carousel | 13,884 |
| Corporate contact | 41,588 |
| Course | 676 |
| Critic review | 2,740 |
| Dataset | 28 |
| Employer aggregate rating | 7 |
| Event | 18,385 |
| Fact check | 7 |
| FAQ page | 16 |
| How-to | 8 |
| Job posting | 355 |
| Livestream | 232 |
| Local business | 200,974 |
| Logo | 442,324 |
| Media | 1,274 |
| Occupation | 0 |
| Product | 16,090 |
| Q&A page | 20 |
| Recipe | 434 |
| Review snippet | 72,732 |
| Sitelinks searchbox | 1,354,754 |
| Social profile | 478,099 |
| Software app | 780 |
| Speakable | 516 |
| Subscription and paywalled content | 363 |
| Video | 14,349 |
rel=canonical
rel=canonical元素,通常被称为“canonical link”,是一个帮助网站管理员防止重复内容问题的HTML元素。它通过指定“规范URL”,即网页的“首选”版本来做到这一点。
| 选择器 | 总数 |
|---|---|
<link rel=canonical href="*"> | 3,183,575 |
<meta name="keywords">
已经过时,谷歌不再使用它,这并不新鲜。对于大多数搜索引擎来说,<meta name="keywords">似乎也是一个垃圾邮件信号。
虽然主要搜索引擎不使用元关键字进行排名,但它们对Solr等现场搜索引擎非常有用。
| 选择器 | 总数 |
|---|---|
<meta name="keywords" content="*"> | 2,577,850 |
<meta name="keywords" content=""> | 256,220 |
<meta name="keywords"> | 14,127 |
标题
在750万页数内,h1(59.6%)和h2(58.9%)是使用最多的28个元素之一。尽管如此,在收集了所有的标题后,我们发现h3是出现次数最多的标题——在70,428,376个标题中,有29,565,562个h3s出现。
随机事实:
- h1-h6元素代表了章节标题的六个级别。以下是标题使用的完整统计数据,但我们发现h7s为23,116个,h8为7,276个。这是一件有趣的事情,因为很多人甚至不经常使用h6。
- 有3,046,879页缺少h1标签,在4,502,255页的其余部分,h1使用频率为2.6,共有11,675,565个h1元素。
- 如上所述,虽然有6,263,396页具有有效标题,但其中只有4,502,255页在其内容正文中使用h1。
缺少alt属性
在分析这组数据后,这个永恒的搜索引擎优化和可访问性问题似乎仍然很常见。在总共669,591,743张图像中,近90%的图片缺少alt属性或直接使用空白值。
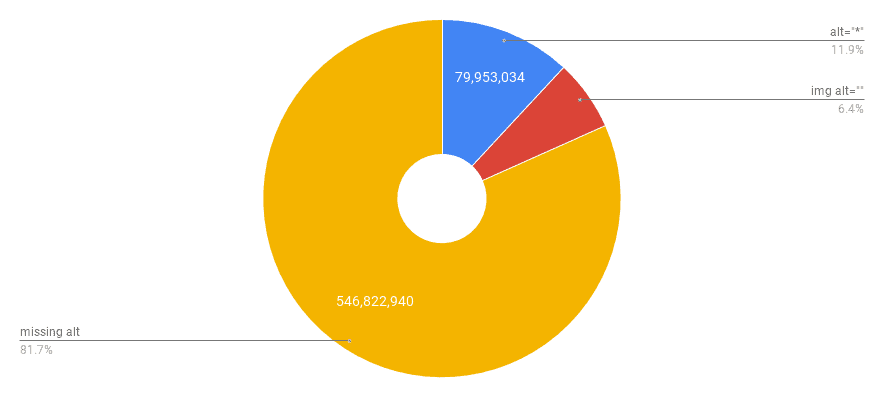
饼状图显示了img标签alt属性的分布,其中alt缺失占主导地位——我们发现的大约6.7亿张图片中,缺失alt占81.7%。
| 选择器 | 总数 |
|---|---|
| img | 669,591,743 |
| img alt="*" | 79,953,034 |
| img alt="" | 42,815,769 |
| img w/缺少alt | 546,822,940 |
语言检测
根据规范,用户代理可以使用通过lang属性指定的语言信息以多种方式控制渲染。
我们在这里感兴趣的部分是关于“协助搜索引擎”。
HTML lang属性用于识别网络上文本内容的语言。这些信息有助于搜索引擎返回特定语言的结果,切换语言配置文件的屏幕阅读器也使用它来提供正确的重音和发音。
不久前,John Mueller说,谷歌忽略了HTML lang属性,并建议改用链接hreflang。谷歌搜索控制台文档指出,谷歌使用hreflang标签将用户的语言偏好与您页面的正确变体相匹配。
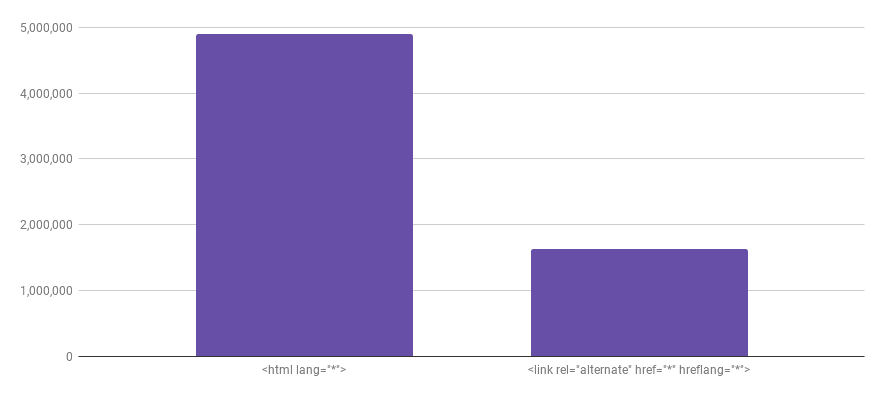 条形图显示,在750万个索引页面中,65%使用html元素上的lang属性,同时21.6%至少使用了hreflang链接。
在我们能够查看的7万个索引页面中,4,903,665个使用html元素上的lang属性。那大约是65%!
条形图显示,在750万个索引页面中,65%使用html元素上的lang属性,同时21.6%至少使用了hreflang链接。
在我们能够查看的7万个索引页面中,4,903,665个使用html元素上的lang属性。那大约是65%!
当谈到hreflang属性时,这表明存在多语言网站,我们发现了大约1,631,602页——这意味着大约21.6%的索引页面至少使用链接rel="alternate" href="*" hreflang="*"元素。
Google Tag Manager
从一开始,Google Analytics的主要任务就是生成有关您网站的报告和统计数据。但是,如果您想将某些页面分组在一起,看看人们是如何通过这个漏斗(funnel),您需要一个独特的Google Analytics标签。这就是事情变得复杂的地方。
谷歌标签管理器使以下操作变得更容易:
- 通过允许您定义标签应该触发的时间和用户操作的自定义规则来管理这些混乱的标签
- 随时更改标签,而无需实际更改网站的源代码,这有时会因为发布周期缓慢而令人头疼
- 在GTM上使用其他分析/营销工具,同样不要触及网站的源代码
我们搜索了*googletagmanager.com/gtm.js的参考文献,发现大约345,979页正在使用谷歌标签管理器。
rel="nofollow"
“Nofollow”为网站管理员告诉搜索引擎“不要关注此页面上的链接”或“不要关注此特定链接”提供了一种方式。
谷歌不遵循这些链接,同样也不会转让股权。考虑到这一点,我们对rel="nofollow"数字感到好奇。我们在750万个索引页面中总共发现了12,828,286个rel="nofollow"链接,计算平均值为每页1.69 rel="nofollow"。
上个月,谷歌宣布了两个新的链接属性值,用于标记链接的nofollow属性:rel="sponsored"和rel="ugc"。我建议您去阅读赛勒斯·谢泼德关于谷歌的nofollow、sponsored和ugc链接如何影响SEO的文章,了解谷歌更改nofollow的原因、nofollow链接的排名影响等。
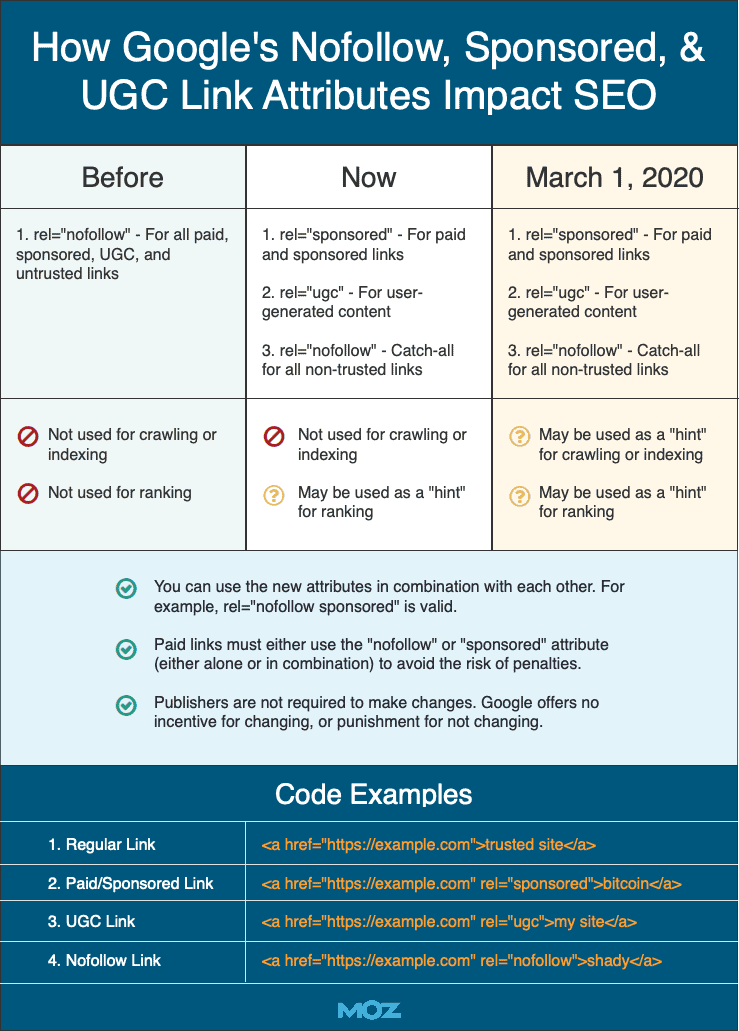
来自赛勒斯·谢泼德文章的表格显示了谷歌的nofollow、赞助和UGC链接属性如何影响SEO。
我们进一步查找了这些新的链接属性值,发现了278 rel="sponsored"和123 rel="ugc"。为了确保我们有这些查询的相关数据,我们在谷歌宣布此事两周后专门更新了索引页面数据集。然后,使用Moz权威指标,我们整理了发现使用至少一个rel="sponsored"或rel="ugc"对的顶级URL:
https://www.seroundtable.com/https://letsencrypt.org/https://www.newsbomb.gr/https://thehackernews.com/https://www.ccn.com/https://www.chip.pl/https://www.gamereactor.se/https://www.tribes.co.uk/
加速移动网站(AMP)
加速移动页面(AMP)是谷歌的一项计划,旨在加快移动网页的速度。许多出版商正在使其内容与AMP格式并行。
要让谷歌和其他平台知道这一点,您需要将AMP和非AMP页面链接在一起。
在我们查看的数百万页中,我们发现只有24,807个非AMP页面使用rel=amphtml引用其AMP版本。
社交
我们想知道一个网站现在的可共享性或社交性如何,所以知道Josh Buchea在你的网页标题中列出了一个很棒的列表,我们从那里提取了社交性的部分,并获得了以下数字:
Facebook 开放图谱
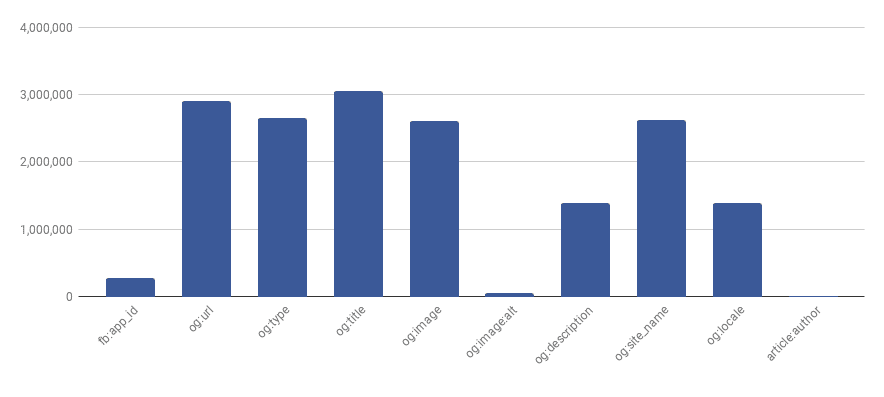
条形图描述了Facebook Open Graph元标签分布,详细描述在下表中,
| 选择器 | 总数 |
|---|---|
meta property="fb:app_id" content="*" | 277,406 |
meta property="og:url" content="*" | 2,909,878 |
meta property="og:type" content="*" | 2,660,215 |
meta property="og:title" content="*" | 3,050,462 |
meta property="og:image" content="*" | 2,603,057 |
meta property="og:image:alt" content="*" | 54,513 |
meta property="og:description" content="*" | 1,384,658 |
meta property="og:site_name" content="*" | 2,618,713 |
meta property="og:locale" content="*" | 1,384,658 |
meta property="article:author" content="*" | 14,289 |
推特开放谱图(Twitter Card)
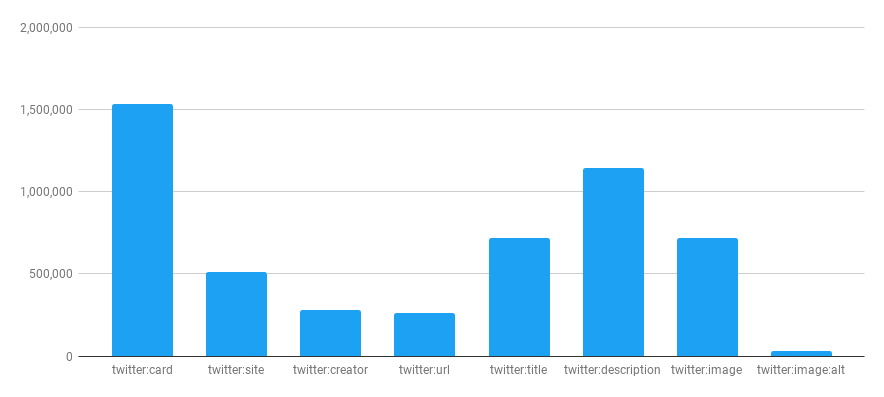
下表详细描述了Twitter Card元标签分布的条形图。
| 选择器 | 总数 |
|---|---|
meta name="twitter:card" content="*" | 1,535,733 |
meta name="twitter:site" content="*" | 512,907 |
meta name="twitter:creator" content="*" | 283,533 |
meta name="twitter:url" content="*" | 265,478 |
meta name="twitter:title" content="*" | 716,577 |
meta name="twitter:description" content="*" | 1,145,413 |
meta name="twitter:image" content="*" | 716,577 |
meta name="twitter:image:alt" content="*" | 30,339 |
说到链接,我们收集了所有指向最受欢迎的社交网络的链接。
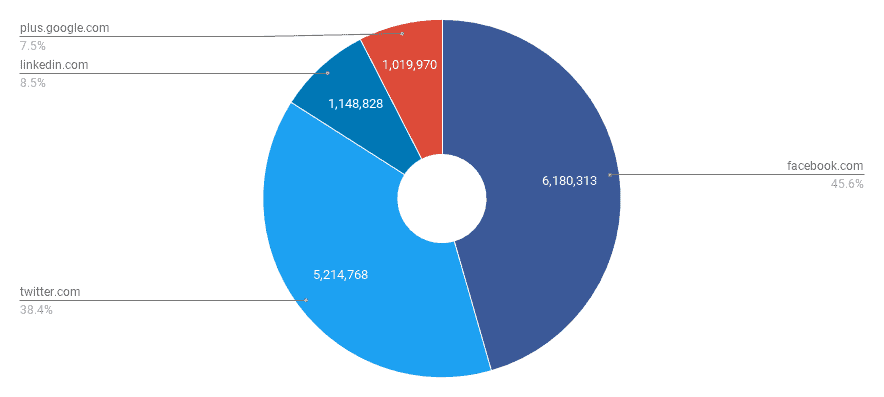
饼状图显示了外部社会联系的分布,详细描述在下表中。
| 选择器 | 总数 |
|---|---|
<a href*="facebook.com"> | 6,180,313 |
<a href*="twitter.com"> | 5,214,768 |
<a href*="linkedin.com"> | 1,148,828 |
<a href*="plus.google.com"> | 1,019,970 |
显然,许多网站仍然链接到他们的Google+配置文件,考虑到最近的Google+关闭,这可能是一个疏忽。
rel=prev/next
根据谷歌,使用rel=prev/next不再是索引信号,正如今年早些时候宣布的:
当我们评估索引信号时,我们决定取消rel=prev/next。研究表明,用户喜欢单页内容,尽可能做到这一点,但对于谷歌搜索来说,多部分搜索也不错。
然而,如果这对你很重要,Bing表示他们以此作为页面发现和网站结构理解的提示。
我们使用这些(像大多数标记一样)作为页面发现和网站结构理解的提示。此时,我们不会根据这些页面在索引中合并页面,也不会在排名模型中使用prev/next。
尽管如此,以下是我们在查看数百万个索引页面时发现的使用情况统计信息:
| 选择器 | 总数 |
|---|---|
<link rel="prev" href="*" | 20,160 |
<link rel="next" href="*" | 242,387 |
差不多就是这样!
使用来自大约800万个索引页面的数据了解平均网页,可以给我们一个清晰的趋势,并帮助我们掌握在搜索引擎优化现代和新兴技术方面可视化HTML的常用方法。但这也许是一个永无休止的分布式事务——虽然有很多数据和统计数据有待探索,但目前仍然有很多问题需要回答:
- 我们现在知道结构化数据在自然状态下是如何使用的。它将如何演变,多少结构化数据被认为是足够的?
- 我们是否应该预计AMP的使用在未来某个地方会增加?
- rel="sponsored"和rel="ugc"将如何改变我们每天编写HTML的方式?在编码外部链接时,除了target="_blank"和rel=“noopener”组合外,我们现在还必须考虑rel="sponsored"和rel="ugc"组合。
- 我们会学会始终为具有装饰以外的目的的图像添加alt属性值吗?
- 为了取悦搜索引擎,我们还需要向网页添加多少额外的元标签或属性?我们真的需要新宣布的数据片段(data-nosnippet)HTML属性吗?接下来是什么,数据允许片段(data-allowsniooet)?
还有其他我们要解决的问题,例如“到第一个字节的时间”(TTFB)值,它与排名高度相关;我强烈推荐HTTP存档。他们定期爬行网络上的顶级网站,并记录几乎所有事情的详细信息。根据最新信息,他们分析了4,565,694个独特的网站,拥有完整的Lighthouse评分,并存储了整个数据集的特定技术,如jQuery或WordPress。