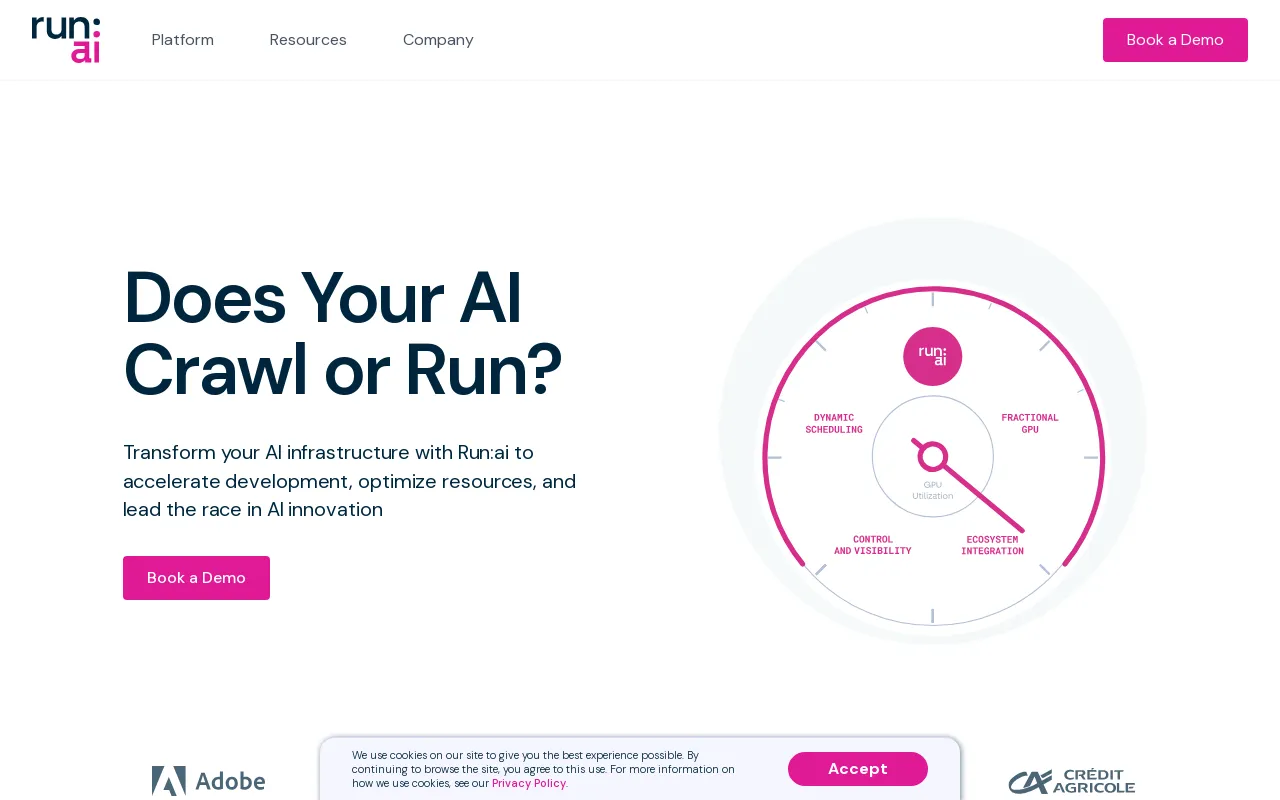
Run:ai Detaljer
Produktinformation
Produktbeskrivning
Kör:ai Dev
Accelerera AI-utveckling och time-to-market
- Starta anpassade arbetsytor med dina favoritverktyg och ramverk.
- Kö batchjobb och kör distribuerad utbildning med en enda kommandorad.
- Distribuera och hantera dina slutledningsmodeller från ett ställe.
Ekosystem
Öka GPU-tillgängligheten och multiplicera avkastningen på din AI-investering
- Arbetsbelastningar
- Tillgångar
- Mätvärden
- Admin
- Autentisering och auktorisering
Kör:ai API
- Arbetsbelastningar
- Tillgångar
- Mätvärden
- Admin
- Autentisering och auktorisering
Kör:ai kontrollplan
Implementera på din egen infrastruktur; Moln. On-Prem. Air-Gapped.
- Multi-klusterhantering
- Dashboards och rapportering
- Arbetsbelastningshantering
- Resursåtkomstpolicy
- Arbetsbelastningspolicy
- Auktorisering och åtkomstkontroll
Kör:ai Cluster Engine
Möt ditt nya AI-kluster; Används. Skalbar. Under kontroll.
- AI Workload Scheduler
- Nodpoolning
- Behållarorkestrering
- GPU-fraktionering
- GPU-noder
- CPU-noder
- Lagring
- Nätverk
CLI & GUI
Run:ai tillhandahåller ett användarvänligt kommandoradsgränssnitt (CLI) och ett omfattande grafiskt användargränssnitt (GUI) för att hantera dina AI-arbetsbelastningar och infrastruktur. CLI erbjuder avancerade kontroll- och skriptfunktioner, medan GUI ger en intuitiv visuell upplevelse för övervakning, konfigurering och interaktion med plattformen.
Arbetsytor
Arbetsytor är isolerade miljöer där AI-utövare kan arbeta med sina projekt. Dessa arbetsytor är förkonfigurerade med nödvändiga verktyg, bibliotek och beroenden, vilket förenklar installationsprocessen och säkerställer konsistens mellan teamen. Arbetsytor kan anpassas för att möta specifika projektkrav och kan enkelt klonas eller delas med medarbetare.
Verktyg
Run:ai tillhandahåller en uppsättning verktyg utformade för att förbättra effektiviteten och produktiviteten hos AI-utveckling. Verktygen erbjuder funktioner som Jupyter Notebook-integration, TensorBoard-visualisering och modellspårning. Dessa verktyg effektiviserar arbetsflöden, förenklar dataanalys och förbättrar samarbetet mellan teammedlemmar.
Open Source Frameworks
Run:ai stöder ett brett utbud av populära AI-ramverk med öppen källkod, inklusive TensorFlow , PyTorch, JAX och Keras. Detta gör att utvecklare kan utnyttja sina föredragna verktyg och bibliotek utan att behöva anpassa sin befintliga kodbas till en specialiserad plattform.
LLM Catalog
Run:ai erbjuder en LLM Catalog, en kurerad samling av populära stora språkmodeller (LLM) och deras motsvarande konfigurationer. Den här katalogen gör det enklare att distribuera och experimentera med toppmoderna LLM:er, vilket påskyndar utvecklingen av AI-applikationer som utnyttjar avancerade språkbearbetningsmöjligheter.
Arbetsbelastningar
The Run: ai-plattformen möjliggör effektiv hantering av olika AI-arbetsbelastningar, inklusive:
* **Träning:** Run:ai optimerar distribuerade träningsjobb, så att du effektivt kan träna modeller på stora datamängder över flera GPU:er.
* **Inferens:** Run:ai effektiviserar modelldistribution och slutledning, vilket gör att du kan distribuera modeller för realtidsförutsägelser eller batchbearbetning.
* **Notebook Farms:** Run:ai stöder skapandet och hanteringen av skalbara notebookfarmar, vilket ger en samarbetsmiljö för datautforskning och modellprototyper.
* **Forskningsprojekt:** Run:ai är utformad för att underlätta forskningsaktiviteter och erbjuder en plattform för experiment med nya modeller, algoritmer och tekniker.
Tillgångar
Run:ai låter användare hantera och dela AI-tillgångar, inklusive:
* **Modeller:** Lagra och versionsutbildade modeller för enkel åtkomst och distribution.
* **Datauppsättningar:** Lagra och hantera stora datamängder för effektiv användning i utbildningsjobb.
* **Kod:** Dela och samarbeta om kod relaterad till AI-projekt.
* **Experiment:** Spåra och jämför resultaten av olika AI-experiment.
Mätvärden
Run:ai tillhandahåller omfattande övervaknings- och rapporteringsfunktioner, så att användare kan spåra nyckeltal relaterade till deras AI-arbetsbelastningar och infrastruktur. Detta inkluderar:
* **GPU-användning:** Övervaka användningen av GPU:er över hela klustret, vilket säkerställer effektiv resursallokering.
* **Arbetsbelastningsprestanda:** Spåra prestanda för utbildnings- och slutledningsjobb, identifiera flaskhalsar och möjligheter till optimering.
* **Resursförbrukning:** Övervaka CPU-, minnes- och nätverksanvändning och ge insikter om resursanvändning och potentiella optimeringsstrategier.
Admin
Run:ai erbjuder administrativa verktyg för att hantera plattformen och dess användare, inklusive:
* **Användarhantering:** Kontrollera åtkomsträttigheter och behörigheter för olika användare eller grupper.
* **Klusterkonfiguration:** Konfigurera hårdvaru- och mjukvaruresurserna inom AI-klustret.
* **Policytillämpning:** Definiera och tillämpa policyer för resursallokering för att säkerställa rättvisa och effektivitet.
Autentisering och auktorisering
Run:ai tillhandahåller säkra autentiserings- och auktoriseringsmekanismer för att kontrollera åtkomst till resurser och känslig data. Detta inkluderar:
* **Enkel inloggning (SSO):** Integrera med befintliga identitetsleverantörer för sömlös användarautentisering.
* **Rollbaserad åtkomstkontroll (RBAC):** Definiera roller med specifika behörigheter, vilket säkerställer granulär kontroll över åtkomst till resurser.
* **Multi-factor authentication (MFA):** Förbättra säkerheten genom att kräva flera faktorer för användarinloggning.
Multi-Cluster Management
Run:ai möjliggör hantering av flera AI-kluster från ett centralt kontrollplan. Detta tillåter organisationer att:
* **Konsolidera resurser:** Aggregera resurser över olika kluster, vilket ger en enhetlig bild av tillgänglig kapacitet.
* **Standardisera arbetsflöden:** Tillämpa konsekventa policyer och konfigurationer över flera kluster.
* **Optimera utnyttjandet:** Balansera arbetsbelastningsfördelning över kluster för optimal resursallokering.
Dashboards och rapportering
Run:ai tillhandahåller kraftfulla instrumentpaneler och rapportverktyg för att visualisera nyckeltal, spåra arbetsbelastningsprestanda och få insikter om resursanvändning. Dessa funktioner inkluderar:
* **Realtidsövervakning:** Spåra GPU-användning, arbetsbelastningsförlopp och resursanvändning i realtid.
* **Historisk analys:** Analysera historisk data för att identifiera trender, optimera resursallokering och förbättra arbetsbelastningsprestanda.
* **Anpassningsbara instrumentpaneler:** Skapa anpassade instrumentpaneler skräddarsydda för specifika behov och perspektiv.
Workload Management
Run:ai förenklar hanteringen av AI-arbetsbelastningar, inklusive:
* **Schemaläggning:** Automatisera schemaläggning och genomförande av utbildnings- och slutledningsjobb.
* **Prioritering:** Tilldela prioriteringar till arbetsbelastningar för att säkerställa att viktiga uppgifter slutförs först.
* **Resursallokering:** Allokera resurser (GPU, CPU, minne) till arbetsbelastningar baserat på deras behov och prioriteringar.
Resursåtkomstpolicy
Run:ai erbjuder en flexibel motor för resursåtkomstpolicy som tillåter organisationer att definiera och genomdriva regler som styr hur användare kan komma åt och använda klusterresurser. Detta möjliggör:
* **Fair-share allokering:** Se till att resurser fördelas rättvist mellan användare och team.
* **Kvothantering:** Sätt gränser för resursanvändning för att förhindra överkonsumtion och säkerställa effektiv tilldelning.
* **Prioritetstillämpning:** Prioritera åtkomst till resurser baserat på användarroller eller vikt av arbetsbelastning.
Arbetsbelastningspolicy
Run:ai stöder skapandet av arbetsbelastningspolicyer, definierar regler och riktlinjer för hantering av AI-arbetsbelastningar. Detta gör det möjligt för organisationer att:
* **Standardisera arbetsflöden:** Upprätta konsekventa arbetsflöden och bästa praxis för att köra AI-arbetsbelastningar.
* **Automatisera uppgifter:** Automatisera vanliga arbetsbelastningshanteringsoperationer, såsom resursallokering och schemaläggning.
* **Förbättra säkerheten:** Genomför policyer för att säkerställa efterlevnad av säkerhetsstandarder och föreskrifter.
Auktorisering och åtkomstkontroll
Run:ai använder robusta auktoriserings- och åtkomstkontrollmekanismer för att säkra åtkomst till resurser och data, inklusive:
* **Finkorniga behörigheter:* * Ge specifika behörigheter till användare eller grupper, vilket ger detaljerad kontroll över åtkomst till resurser.
* **Revision och loggning:** Spåra användaråtgärder och åtkomstmönster, vilket ger en revisionsspår för säkerhets- och efterlevnadsändamål.
* **Integration med befintliga säkerhetsverktyg:** Integrera Run:ai med befintliga säkerhetssystem för centraliserad hantering och kontroll.
AI Workload Scheduler
Run:ai:s AI Workload Scheduler är speciellt utformad för att optimera resurshantering för hela AI-livscykeln, vilket gör att du kan:
* **Dynamisk schemaläggning:* * Tilldela resurser dynamiskt till arbetsbelastningar baserat på aktuella behov och prioriteringar.
* **GPU-pooling:** Konsolidera GPU-resurser i pooler, vilket möjliggör flexibel allokering till olika arbetsbelastningar.
* **Prioritetsschemaläggning:** Se till att kritiska uppgifter tilldelas resurser först, vilket optimerar den totala genomströmningen av AI-klustret.
Node Pooling
Run:ai introducerar konceptet Node Pooling, vilket gör det möjligt för organisationer att hantera heterogena AI-kluster med lätthet. Den här funktionen tillhandahåller:
* **Klusterkonfiguration:** Definiera kvoter, prioriteringar och policyer på nodpoolnivå för att hantera resursallokering.
* **Resurshantering:** Säkerställ rättvis och effektiv allokering av resurser inom klustret, med hänsyn till faktorer som GPU-typ, minne och CPU-kärnor.
* **Arbetsbelastningsfördelning:** Tilldela arbetsbelastningar till lämpliga nodpooler baserat på deras resurskrav.
Container Orchestration
Run:ai integreras sömlöst med containerorkestreringsplattformar som Kubernetes, vilket möjliggör distribution och hantering av distribuerade containeriserade AI-arbetsbelastningar. Detta ger:
* **Automatisk skalning:** Skala AI-arbetsbelastningar upp eller ner sömlöst baserat på efterfrågan.
* **Hög tillgänglighet:** Se till att AI-arbetsbelastningar förblir tillgängliga även om enskilda noder misslyckas.
* **Förenklad implementering:** Distribuera och hantera AI-arbetsbelastningar med hjälp av containeriserade bilder, vilket främjar portabilitet och reproducerbarhet.
GPU Fractioning
Run:ai:s GPU Fractioning-teknik låter dig dela upp en enda GPU i flera fraktioner, vilket ger ett kostnadseffektivt sätt att köra arbetsbelastningar som bara kräver en del av en GPU:s resurser. Den här funktionen:
* **Ökar kostnadseffektiviteten:** Gör att du kan köra fler arbetsbelastningar på samma infrastruktur genom att dela GPU-resurser.
* **Förenklar resurshantering:** Effektiviserar allokeringen av GPU-resurser till olika arbetsbelastningar med varierande krav.
* **Förbättrar användningen:** Maximerar utnyttjandet av GPU:er, minskar vilotiden och ökar effektiviteten.
GPU-noder
Run:ai stöder ett brett utbud av GPU-noder från ledande leverantörer, inklusive NVIDIA, AMD och Intel. Detta säkerställer kompatibilitet med en mängd olika hårdvarukonfigurationer och gör det möjligt för organisationer att använda befintlig infrastruktur eller välja de mest lämpliga GPU:erna för deras specifika behov.
CPU-noder
Förutom GPU-noder, Kör :ai stöder även CPU-noder för uppgifter som inte kräver GPU-acceleration. Detta gör att organisationer kan utnyttja befintlig CPU-infrastruktur eller använda mer kostnadseffektiva CPU-resurser för specifika uppgifter.
Lagring
Run:ai integreras med olika lagringslösningar, inklusive NFS, GlusterFS, ceph , och lokala diskar. Denna flexibilitet gör det möjligt för organisationer att välja en lagringslösning som bäst uppfyller deras krav på prestanda, skalbarhet och kostnad.
Nätverk
Run:ai är utformad för att fungera effektivt i nätverk med hög bandbredd, möjliggör effektiv överföring av data mellan noder och exekvering av distribuerade AI-arbetsbelastningar. Run:ai kan också distribueras i luftglappade miljöer, där det inte finns någon internetanslutning, vilket säkerställer säkerheten och isoleringen av känslig data.
Anteckningsböcker på begäran
Run:ai's Notebooks on Demand-funktionen gör det möjligt för användare att starta förkonfigurerade arbetsytor med sina favoritverktyg och ramverk, inklusive Jupyter Notebook, PyCharm och VS Code. Detta:
* **Förenklar installationen:** Starta snabbt arbetsytor utan att behöva installera beroenden manuellt.
* **Säkerställer konsekvens:** Ger konsekventa miljöer över team och projekt.
* **Förbättrar samarbetet:** Dela och samarbeta på arbetsytor sömlöst med teammedlemmar.
Träning och finjustering
Run:ai förenklar processen med att träna och finjustera AI-modeller:
* **Kö batchjobb:** Schemalägg och kör batch utbildningsjobb med en enda kommandorad.
* **Distribuerad utbildning:** Träna effektivt modeller på stora datamängder över flera GPU:er.
* **Modelloptimering:** Optimera träningsparametrar och hyperparametrar för förbättrad prestanda.
Privata LLM:er
Run:ai låter användare distribuera och hantera sina egna privata LLM:er, specialutbildade modeller som kan användas för specifika applikationer. Detta möjliggör:
* **Modellimplementering:** Distribuera LLM-modeller för slutledning och generera personliga svar.
* **Modelhantering:** Lagra, versionera och hantera LLM-modeller för enkel åtkomst och uppdateringar.
* **Dataintegritet:** Håll användardata konfidentiell och säker inom organisationens infrastruktur.
NVIDIA & Run:ai Bundle
Run:ai och NVIDIA har samarbetat för att erbjuda en helt integrerad lösning för DGX Systems, som levererar den mest presterande fullstacklösningen för AI-arbetsbelastningar. Detta paket:
* **Optimerar DGX-prestanda:** Utnyttjar Run:ai:s kapacitet för att maximera utnyttjandet och prestanda hos DGX-hårdvaran.
* **Förenklar hanteringen:** Tillhandahåller en enda plattform för att hantera DGX-resurser och AI-arbetsbelastningar.
* **Accelererar AI-utveckling:** Ger organisationer möjlighet att accelerera sina AI-initiativ med en sammanhållen lösning.
Distribuera på din egen infrastruktur; Moln. On-Prem. Air-Gapped.
Run:ai stöder ett brett utbud av distributionsmiljöer och erbjuder flexibla alternativ för organisationer med olika infrastrukturkrav. Detta inkluderar:
* **Molndistributioner:** Implementera Run:ai på stora molnleverantörer, som AWS, Azure och Google Cloud, så att du kan utnyttja deras tjänster och resurser.
* **Placering på plats:** Implementera Run:ai på din egen hårdvaruinfrastruktur, vilket ger fullständig kontroll över din AI-miljö.
* **Utplaceringar med luftglapp:** Implementera Run:ai i isolerade miljöer utan internetanslutning, vilket säkerställer säkerheten och integriteten för dina data.
Alla ML-verktyg och ramverk
Run:ai är utformad för att fungera med ett brett utbud av maskininlärningsverktyg och ramverk, inklusive:
* **TensorFlow:** Run och hantera TensorFlow-arbetsbelastningar effektivt.
* **PyTorch:** Distribuera och optimera PyTorch-modeller för träning och slutledning.
* **JAX:** Använd JAX för högpresterande AI-beräkningar.
* **Keras:** Bygg och träna Keras-modeller sömlöst.
* **Scikit-learn:** Använd Scikit-learn för maskininlärningsuppgifter.
* **XGBoost:** Utnyttja XGBoost för gradientförstärkande algoritmer.
* **LightGBM:** Implementera LightGBM för effektiv gradientförstärkning.
* **CatBoost:** Använd CatBoost för robust gradientförstärkning.
Alla Kubernetes
Run:ai integreras sömlöst med Kubernetes, den ledande containerorkestreringsplattformen. Detta säkerställer kompatibilitet med befintliga Kubernetes-miljöer och tillåter organisationer att dra nytta av dess fördelar, inklusive:
* **Automatisk skalning:** Skala AI-arbetsbelastningar dynamiskt baserat på efterfrågan.
* **Hög tillgänglighet:** Se till att AI-arbetsbelastningar förblir tillgängliga även om enskilda noder misslyckas.
* **Containeriserade distributioner:** Distribuera AI-arbetsbelastningar som containrar, främja portabilitet och reproducerbarhet.
Var som helst
Run:ai är utformad för att distribueras var som helst, vilket ger flexibilitet till organisationer med olika infrastrukturbehov. Detta inkluderar:
* **Datacenter:** Distribuera Run:ai i dina egna datacenter för maximal kontroll och säkerhet.
* **Molnleverantörer:** Implementera Run:ai på stora molnleverantörer för skalbarhet och flexibilitet.
* **Edge-enheter:** Implementera Run:ai på edge-enheter för AI-applikationer i realtid.
All infrastruktur
Run:ai stöder ett brett utbud av infrastrukturkomponenter, så att du kan bygga din ideala AI-miljö:
* **GPU:** Utnyttja högpresterande GPU:er från ledande leverantörer, som NVIDIA, AMD och Intel.
* **CPU:er:** Använd processorer för uppgifter som inte kräver GPU-acceleration.
* **ASIC:** Integrera ASIC:er för specialiserade uppgifter, till exempel maskininlärning.
* **Lagring:** Välj lagringslösningar som bäst uppfyller dina krav på prestanda, skalbarhet och kostnad.
* **Nätverk:** Implementera Run:ai på nätverk med hög bandbredd för effektiv dataöverföring och distribuerade arbetsbelastningar.
FAQFAQ
// * **Cloud:** Run:ai kan distribueras på alla större molnleverantörer inklusive AWS, Azure , och GCP.
// * **On-Prem:** Run:ai kan också distribueras på plats, vilket gör att organisationer kan hålla sina data och arbetsbelastningar säkra inom sina egna datacenter.
// * **Air-Gapped:** Run:ai kan också distribueras i air-gapped miljöer, vilket är miljöer som inte är anslutna till internet. Detta tillåter organisationer att distribuera AI-arbetsbelastningar i miljöer där det finns strikta säkerhetskrav.//
// * **Inferens:** Kör: ai kan användas för att köra inferensarbetsbelastningar på GPU:er, vilket kan hjälpa till att förbättra prestanda för AI-applikationer.//
// * **Forskning och utveckling:** Run:ai kan användas för att stödja forsknings- och utvecklingsinsatser genom att tillhandahålla en kraftfull plattform för att hantera och distribuera AI-arbetsbelastningar.//
// * **Deep learning:** Run:ai kan användas för att träna och distribuera modeller för djupinlärning, som blir allt mer populära för ett brett spektrum av applikationer.//
//
För mer information, vänligen kontakta vårt team [email protected] Vi svarar gärna på dina frågor och hjälper dig att få började med Run:ai.//
Webbplatstrafik
Ingen data
Alternativa produkter
AI改写
Blogg- och artikel skrivande
Välkommen till Aigaixie, ett AI-drivet verktyg för att skapa innehåll
Monica AI
Konversationell Chatbot
Allt-i-ett AI-assistent Personlig, snabb och gratis

Imagen AI
Text till Bild Konvertering
Bild: Oöverträffad fotorealism × djup språkförståelse

AI Art
Bilddgenerering
AI Graphic Creation Platform
6pen Art
Bilddgenerering
Förvandla din fantasi till konst

MoDao AI
Designassistent
Mockingbot AI: Dubbla din prototypeffektivitet