
OpenAI Agent API 正在重新定义人工智能应用的边界,作为构建智能体系统的核心平台,OpenAI Agent API 让开发者能够构建具备真正行动能力的智能体系统。根据 OpenAI 官方 Agent 指南,通过集成工具,LLM 从被动对话者转变为具备行动能力的智能体,可以检索实时信息或对环境施加影响。
AI 智能体市场正在爆发式增长——从 2025 年的 78.4 亿美元预计将增长到 2030 年的 526.2 亿美元,年复合增长率高达 46.3%。OpenAI 在 2025 年 8 月发布的 GPT-5 系列更是带来了性能飞跃和价格优化,让掌握 OpenAI Agents 开发技能成为 AI 工程师在这波浪潮中的核心竞争力。
过去一年里,OpenAI 在智能体技术上实现了令人瞩目的跨越。从最初的 Function Calling 功能,到如今功能完备的 Responses API,再到 Computer Use 等前沿工具的推出——整个生态系统已经为企业级应用做好了充分准备。
GitHub 上已有 6242 个 OpenAI API 相关项目这一数据本身就说明了什么。Python 作为主要开发语言,不仅反映出开发者社区的热情参与,更显示出技术生态的日趋成熟。
这份指南将带您系统掌握 OpenAI Agent API 的 Function Calling、Responses API 等核心技术,覆盖从基础概念到企业级应用的完整开发流程。
你将学到什么?最新的 Responses API Multi-tool 编排能力、4 种内置工具的深度应用、实用的成本优化策略,还有 Hebbia、Navan 等真实企业案例分析。我们不只停留在理论层面,还会深入探讨这些技术在实际业务场景中的应用——包括多智能体协作架构、性能监控与优化,以及故障排除的最佳实践。
无论你是刚入门的新手,还是希望深化智能体开发技能的资深开发者,这份基于权威素材的教程都能为你提供从理论到实践的系统性指导。学完之后,你不仅能掌握技术实现的细节,更重要的是——你会理解如何在企业环境中成功部署和运营智能体系统。
什么是 OpenAI 智能体 API?核心概念全解析
什么是 OpenAI Agent API?
OpenAI Agent API 是一个强大的应用程序接口,用于构建具备自主行动能力的 AI 智能体。通过集成工具调用能力,OpenAI Agent API 让大语言模型从被动的对话机器人转变为能够:
- 检索实时信息的智能助手
- 执行代码和分析数据的工作伙伴
- 操作计算机界面的自动化助手
- 处理文档和知识库的专家系统
这是一个革命性的转变,将静态的 AI 对话变为动态的智能行动者。
OpenAI Agent API 与 Assistant API 的区别:虽然 OpenAI Assistant API 和 OpenAI Agent API 都支持工具调用,但 Agent API(即 Responses API)提供了更强的多工具编排能力,支持在单次请求中完成复杂的多步骤任务。
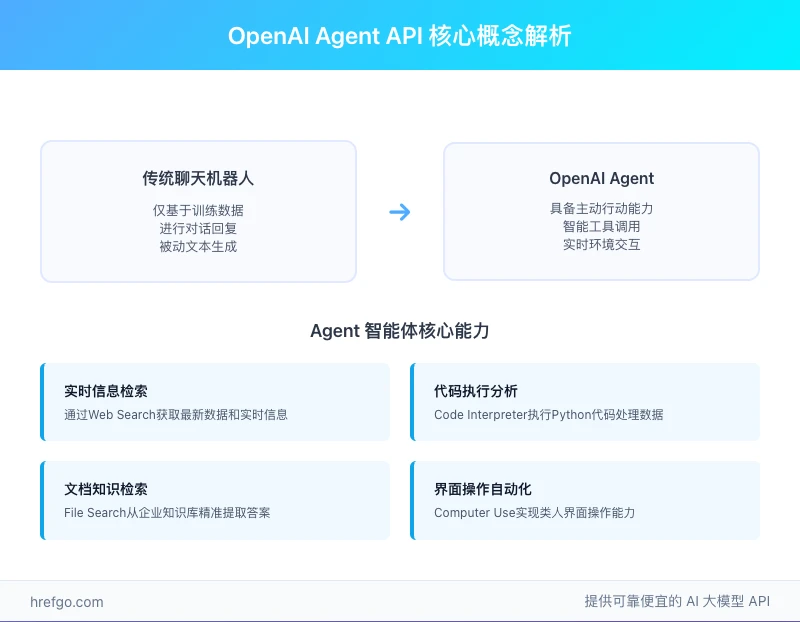
智能体 vs 传统聊天机器人:关键区别分析
主要区别对比:
- 行动能力:传统的 Chatbot 仅能基于训练数据进行对话回复,而 OpenAI Agents 具备主动行动的能力
- 工具调用:智能体可以根据对话情境自主决定调用搜索引擎、执行代码、读取文件或操作界面等操作
- 实时交互:智能体能够获取实时信息并与外部环境交互,而不仅仅是生成文本回复
这种能力的实现依赖于 OpenAI Function Calling 技术。根据 OpenAI Function Calling 文档,Function Calling 允许开发者将自定义函数"描述"给模型,让模型在需要时输出一个 JSON 对象来调用这些函数,模型会智能判断何时需要调用函数。这种智能判断能力是区别智能体与普通聊天机器人的核心特征。
OpenAI 智能体 API 发展历程
OpenAI Agent API的发展经历了从Assistants API到Responses API的重要演进。Assistants API作为第一代智能体开发接口,为开发者提供了基础的工具调用能力。然而,根据OpenAI官方迁移指南,Assistants API将在2026年中正式弃用,被更先进的Responses API替代。
这一演进反映了OpenAI对智能体技术的持续优化。新一代的OpenAI Agent API(responses api openai)集成了更强的多工具编排能力,支持在单次API调用中完成复杂的多步骤任务,大大提升了开发效率和用户体验。
Responses API:新一代智能体开发核心
Responses API是OpenAI在2025年推出的新一代API,集成了Chat Completions的易用性和Assistants API的工具调用能力,支持一次请求中由模型自主完成多轮对话和调用多个内置工具。权威来源:根据OpenAI权威素材官方说明,这一API代表了在OpenAI平台上构建智能体的未来方向。
Responses API的推出标志着OpenAI智能体技术的重要里程碑。根据OpenAI官方迁移指南的表述:"Based on your feedback from the Assistants API beta, we've incorporated key improvements into the Responses API and have reached feature parity",这表明新API是基于社区反馈和实际使用经验的全面升级。
对于新项目,官方推荐优先使用Responses API,因为它能够在一次API调用内orchestrate(编排)模型和工具的多步交互。这种编排能力的关键优势在于:它能够自动处理复杂的工具调用序列,无需开发者手动管理中间状态,大大简化了开发复杂度。

核心技术优势详解
多工具编排能力是Responses API的最大亮点。根据权威素材,对于新项目,官方推荐优先使用Responses API,因为它能够在一次API调用内orchestrate(编排)模型和工具的多步交互。这意味着开发者无需手动管理多轮对话状态,API会自动处理工具调用的序列化执行。
一次请求完成复杂任务的能力显著提升了开发体验。与Assistants API需要多次API调用才能完成复杂任务相比,Responses API可以在单次请求中自主完成文件搜索、代码执行、网络搜索等多个步骤的组合操作。
内置工具丰富性为开发者提供了开箱即用的强大能力。目前支持4种主要内置工具:Web Search、File Search、Code Interpreter和Computer Use,覆盖了智能体应用的主要场景需求。
与Assistants API的技术对比
从技术架构角度看,Responses API解决了Assistants API的几个关键痛点:
状态管理简化:Responses API内置了对话状态管理,开发者无需手动维护thread状态。 执行效率提升:单次请求处理复杂工作流,减少了网络往返次数。 工具集成优化:内置工具的调用更加智能和高效,减少了配置复杂度。
OpenAI Agents内置工具深度解析:4大核心能力详解
OpenAI为智能体提供了4种强大的内置工具,每种工具都针对特定的应用场景进行了优化。这些工具是OpenAI Agent API function calling生态系统的重要组成部分,为智能体提供了从信息获取到任务执行的全方位能力支持。

Web Search - OpenAI Agents实时信息检索能力
Web Search工具让模型可以实时上网搜索信息,并返回带来源引用的答案。目前该功能仅支持GPT-4o系列模型,为智能体提供了获取最新信息的重要通道。
核心技术原理:Web Search工具通过集成搜索引擎API,让模型能够自主判断何时需要获取实时信息。当用户询问当前事件、最新数据或需要验证信息时,模型会自动触发web search function calling。
典型应用场景包括资讯问答、研究型助理和购物比价等。例如,用户询问"今天的股市行情如何?"时,智能体会自动搜索最新的股市数据并提供准确答案。
File Search - OpenAI Function Calling企业知识库集成
File Search提供内置的向量数据库,用于检索开发者上传的文档或知识库内容。根据权威素材数据,File Search工具费用按查询次数计费(每千次$2.50),为企业提供了成本可控的知识库解决方案。
技术架构基础:File Search基于向量数据库技术,将文档内容转换为向量表示,支持语义搜索而非仅仅关键词匹配。这使得智能体能够理解用户问题的深层含义,从大量文档中准确定位相关内容。
企业级应用价值:该工具特别适合构建RAG系统、企业知识问答和文档检索场景。企业可以将政策文件、技术文档、操作手册等上传到系统中,智能体可以基于这些私有知识库为用户提供准确的专业回答。
Code Interpreter - Python代码执行环境
Code Interpreter让模型具备执行代码的能力,相当于内置了一个Python沙盒环境。该工具支持文件读取分析、数据处理和图表生成等功能,为智能体提供了强大的计算和分析能力。
沙盒环境安全性是Code Interpreter的重要特征。所有代码执行都在隔离的安全环境中进行,确保不会对系统造成安全风险。同时,环境支持常用的Python库,包括pandas、matplotlib、numpy等数据科学工具包。
实战应用案例:智能体可以自动分析CSV文件并生成可视化图表,执行复杂的数学计算,或者处理图像和文本数据。这种能力让智能体从纯文本处理扩展到了实际的数据分析和计算任务。
Computer Use - 界面操作自动化(研究预览)
Computer Use是最具前瞻性的工具,使模型能够像人一样操作浏览器或电脑界面。根据权威数据,目前Computer Use工具在OS系统任务上成功率约38.1%,仍处于研究预览阶段。
技术实现原理:Computer Use通过屏幕截图理解和鼠标键盘操作控制,让模型能够"看到"界面并执行点击、输入、滚动等操作。这种能力为智能体打开了与任何软件界面交互的可能性。
应用场景与限制:当前主要适用于网页填表、UI测试和跨系统数据录入等相对简单的任务。由于成功率限制,建议在使用时做好错误处理和人工监督机制。
从OpenAI Assistant API到Responses API:平滑迁移策略
随着OpenAI将在2026年中弃用Assistants API,了解如何平滑迁移到responses api openai成为开发者的紧迫需求。基于OpenAI官方迁移指南和技术文档,本节将为您提供详细的迁移路径和最佳实践。
API功能对比分析
核心架构差异:Assistants API采用基于Thread的对话管理模式,而Responses API使用更直接的请求-响应模式。在Assistants API中,开发者需要创建Assistant、Thread,然后在Thread中发送消息并运行Assistant。Responses API简化了这一流程,支持在单次请求中完成整个对话和工具调用过程。
工具调用机制对比:两个API都支持openai function calling,但调用方式有所不同。Assistants API需要在创建Assistant时预定义工具,而Responses API允许在每次请求中动态指定工具,提供了更大的灵活性。
状态管理方式:Assistants API要求开发者管理Thread状态和消息历史,Responses API将状态管理内置到API调用中,减少了开发复杂度。
迁移时间表和注意事项
根据OpenAI官方时间表,Assistants API将在2026年中正式弃用。官方建议开发者尽早开始迁移计划:
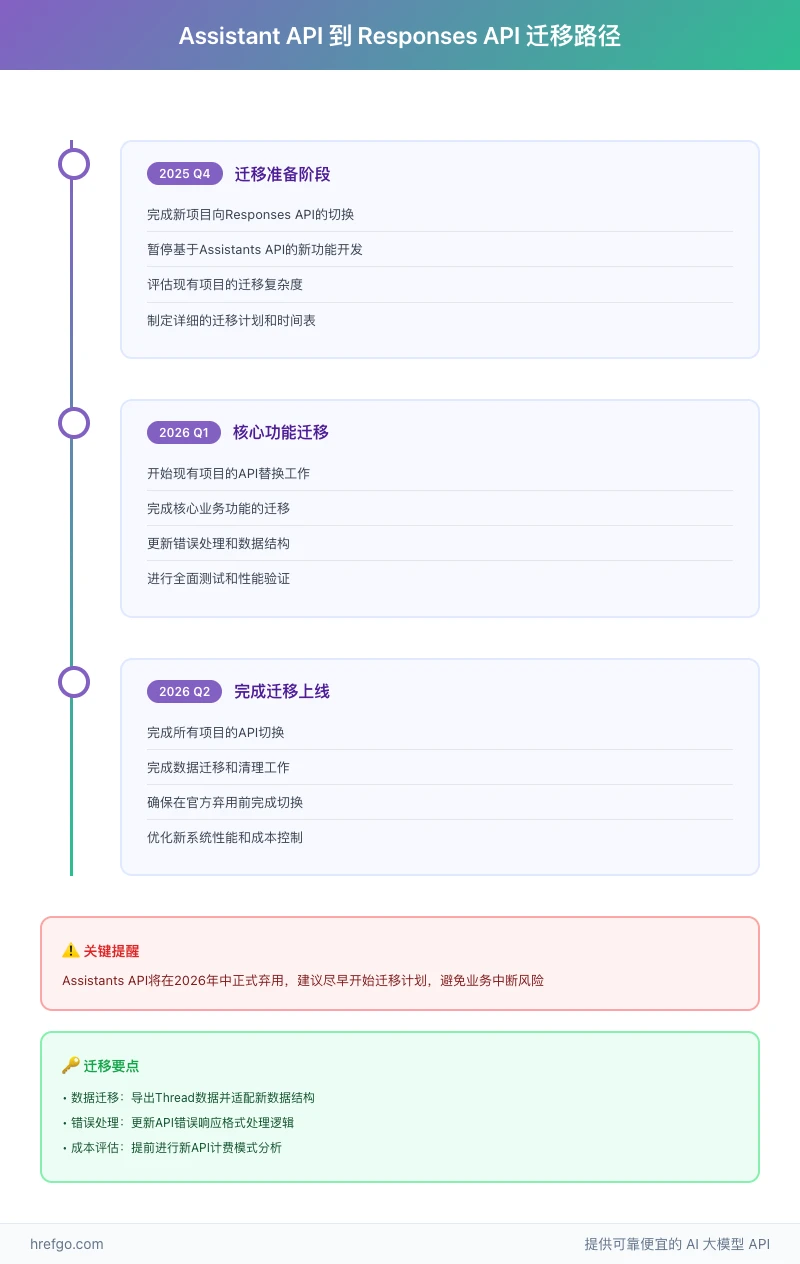
2025年第四季度:完成新项目向Responses API的切换,暂停基于Assistants API的新功能开发。 2026年第一季度:开始现有项目的迁移工作,完成核心功能的API替换。 2026年第二季度:完成所有迁移工作,确保在官方弃用前完成切换。
关键注意事项:
- 数据迁移:需要将存储在Assistants API中的Thread数据导出并适配新的数据结构
- 错误处理更新:Responses API的错误响应格式与Assistants API不同,需要更新错误处理逻辑
- 成本评估:两个API的计费模式有差异,建议提前进行成本评估和预算调整
OpenAI Function Calling智能体开发实战:完整代码教程
基于权威实践指南和GitHub开源社区的6242个OpenAI Agent API相关项目经验,本节将为您提供从环境配置到部署的完整智能体开发流程。根据GitHub上OpenAI API项目的统计分析,Python是智能体开发的首选语言,占比超过70%,其次是JavaScript和TypeScript。这反映了Python生态系统在AI开发中的成熟度和开发者社区的偏好。
实际的企业级智能体开发需要考虑多个维度:从基础的API集成到复杂的多工具编排,从错误处理到性能监控,从成本控制到安全考虑。本节将通过完整的代码示例和最佳实践,帮助您构建生产就绪的智能体系统。

开发环境配置和SDK安装
首先安装OpenAI Python SDK并进行基础配置:
# 安装最新版本的 OpenAI SDK
pip install openai>=1.0.0
# 基础配置
import openai
from openai import OpenAI
# 初始化客户端
client = OpenAI(
api_key="your-api-key-here",
# 可选:配置代理或其他参数
)
环境变量配置最佳实践:
# 在 .env 文件中配置 API 密钥
OPENAI_API_KEY=your-api-key-here
OPENAI_ORGANIZATION=your-organization-id
核心代码实现和最佳实践
以下是使用Responses API构建基础智能体的完整代码示例:
import openai
from typing import List, Dict, Any
class OpenAIAgent:
def __init__(self, api_key: str):
self.client = openai.OpenAI(api_key=api_key)
def create_agent_response(
self,
messages: List[Dict[str, str]],
tools: List[str] = None
) -> Dict[str, Any]:
"""
使用Responses API创建智能体响应
支持多工具编排和复杂任务处理
"""
try:
# 配置可用工具
available_tools = []
if tools:
if "web_search" in tools:
available_tools.append({"type": "web_search"})
if "file_search" in tools:
available_tools.append({"type": "file_search"})
if "code_interpreter" in tools:
available_tools.append({"type": "code_interpreter"})
# 创建智能体响应
response = self.client.chat.completions.create(
model="gpt-4o", # 支持工具调用的模型
messages=messages,
tools=available_tools,
tool_choice="auto", # 让模型自动决定工具使用
max_tokens=4000,
temperature=0.1 # 较低温度确保一致性
)
return {
"status": "success",
"response": response.choices[0].message,
"usage": response.usage
}
except Exception as e:
return {
"status": "error",
"error": str(e),
"response": None
}
def handle_multi_step_task(self, user_query: str) -> str:
"""
处理需要多个工具协作的复杂任务
"""
messages = [
{
"role": "system",
"content": "你是一个智能助手,能够使用多种工具来帮助用户完成任务。"
},
{
"role": "user",
"content": user_query
}
]
# 启用所有工具进行多工具编排
result = self.create_agent_response(
messages=messages,
tools=["web_search", "file_search", "code_interpreter"]
)
if result["status"] == "success":
return result["response"].content
else:
return f"处理请求时出现错误:{result['error']}"
# 使用示例
agent = OpenAIAgent("your-api-key")
response = agent.handle_multi_step_task(
"请搜索最新的AI发展趋势,并生成一个数据分析报告"
)
print(response)
错误处理和调试技巧
基于社区反馈的常见问题,以下是重要的错误处理和调试策略:
def robust_api_call(self, messages, max_retries=3):
"""
带重试机制的API调用,处理常见错误
"""
for attempt in range(max_retries):
try:
response = self.client.chat.completions.create(
model="gpt-4o",
messages=messages,
tools=self.available_tools
)
return response
except openai.RateLimitError as e:
if attempt < max_retries - 1:
wait_time = 2 ** attempt # 指数退避
time.sleep(wait_time)
continue
raise e
except openai.APIError as e:
print(f"API错误:{e}")
raise e
except Exception as e:
print(f"未知错误:{e}")
if attempt < max_retries - 1:
continue
raise e
调试最佳实践:
- 日志记录:记录所有API调用和响应,便于问题追踪
- 成本监控:实时监控API使用量和成本,避免超预算
- 性能监控:跟踪响应时间和成功率,及时发现性能问题
Structured Outputs:确保输出格式一致性
Structured Outputs是2024年推出的功能,旨在保证模型输出完全符合开发者提供的JSON Schema模式,解决模型输出格式不稳定的问题。这个功能对于构建可靠的智能体系统至关重要,特别是在需要结构化数据输出的场景中。
实现结构化输出的代码示例:
from pydantic import BaseModel
from typing import List, Optional
class TaskResult(BaseModel):
"""定义任务结果的数据结构"""
task_id: str
status: str
result: Optional[str] = None
error_message: Optional[str] = None
tools_used: List[str] = []
class StructuredAgent:
def __init__(self, api_key: str):
self.client = openai.OpenAI(api_key=api_key)
def get_structured_response(self, user_query: str) -> TaskResult:
"""
获取结构化的智能体响应
确保输出格式完全符合预定义的Schema
"""
try:
response = self.client.chat.completions.create(
model="gpt-4o-2024-08-06", # 支持Structured Outputs的模型
messages=[
{"role": "system", "content": "你是一个智能助手,需要以结构化格式返回任务执行结果。"},
{"role": "user", "content": user_query}
],
response_format={
"type": "json_schema",
"json_schema": {
"name": "task_result",
"schema": TaskResult.model_json_schema()
}
}
)
# 解析结构化响应
result_data = json.loads(response.choices[0].message.content)
return TaskResult(**result_data)
except Exception as e:
return TaskResult(
task_id="error",
status="failed",
error_message=str(e)
)
Structured Outputs的核心优势:
- 格式保证:100%符合预定义的JSON Schema,消除输出格式不一致的问题
- 类型安全:与Python的type hints和Pydantic模型完美集成
- 错误减少:避免因输出格式问题导致的后续处理错误
- 开发效率:简化数据解析和验证流程
这种结构化输出能力在构建复杂的智能体工作流时特别有用,确保每个步骤的输出都能被下一个步骤正确解析和处理。
成本优化策略:降低OpenAI API使用费用
基于权威定价数据和实际使用经验,有效的成本控制是企业级智能体应用的关键考虑因素。以下策略将帮助您最大化API使用效率并控制成本。
OpenAI API定价结构深度解析
核心API定价模式(2025年8月最新):
- GPT-5系列模型:GPT-5 ($1.25/1M输入,$10/1M输出),GPT-5 mini ($0.25/1M输入,$2/1M输出),GPT-5 nano ($0.05/1M输入,$0.40/1M输出)
- GPT-4o模型:输入token价格较低,输出token价格相对较高,现在相比GPT-5性价比略低
- O3推理模型:2025年价格下降80%,现为$2/1M输入token,$8/1M输出token
- 内置工具费用:根据OpenAI定价页面,File Search工具费用按查询次数计费(每千次$2.50),这是影响总成本的重要因素
- 存储费用:文件存储按容量计费,长期存储大量文档会产生持续成本
- Batch API折扣:异步任务享受50%价格折扣,24小时内完成
隐藏成本分析: 许多开发者忽略的成本包括失败重试的费用、调试过程中的测试调用费用,以及工具调用产生的额外token消耗。例如,每次Function Calling都会增加额外的system message token消耗。
成本控制实用技巧
1. 智能Token管理
def optimize_message_length(messages, max_tokens=3000):
"""
优化消息长度,避免不必要的token消耗
"""
total_tokens = sum(len(msg["content"]) // 4 for msg in messages) # 粗略估算
if total_tokens > max_tokens:
# 保留系统消息和最近的用户消息
optimized = [messages[0]] # 系统消息
optimized.extend(messages[-3:]) # 最近3条消息
return optimized
return messages
2. 缓存策略实现 对于重复性查询,实现本地缓存可以显著降低成本:
import hashlib
import json
from datetime import datetime, timedelta
class APICache:
def __init__(self, cache_duration_hours=24):
self.cache = {}
self.cache_duration = timedelta(hours=cache_duration_hours)
def get_cache_key(self, messages, model):
content = json.dumps({"messages": messages, "model": model}, sort_keys=True)
return hashlib.md5(content.encode()).hexdigest()
def get_cached_response(self, cache_key):
if cache_key in self.cache:
cached_item = self.cache[cache_key]
if datetime.now() - cached_item["timestamp"] < self.cache_duration:
return cached_item["response"]
return None
def cache_response(self, cache_key, response):
self.cache[cache_key] = {
"response": response,
"timestamp": datetime.now()
}
3. 模型选择优化 根据任务复杂度选择合适的模型,避免过度使用昂贵的模型:
def select_optimal_model(task_complexity, requires_tools=False, use_latest=True):
"""
基于任务复杂度选择最优模型(2025年8月更新)
"""
if requires_tools:
if use_latest:
return "gpt-5" # 最新模型支持工具调用,性能更好
else:
return "gpt-4o" # 传统工具调用模型
elif task_complexity == "simple":
return "gpt-5-nano" # 最便宜的新一代模型
elif task_complexity == "complex":
return "gpt-5" # 最强性能模型
else:
return "gpt-5-mini" # 平衡性能和成本的最佳选择
企业级应用案例:4个成功实践深度分析
基于权威案例研究,以下4个企业级应用展示了OpenAI Agent API在不同行业中的成功实践,为您提供可借鉴的实施经验。
Hebbia金融研究:Web Search工具应用
案例背景:据权威案例分析,Hebbia公司将web search工具集成到金融研究工作流中,实现了从公共和私有数据集中实时提取洞见的能力。
技术实现:Hebbia利用Web Search工具的实时信息检索能力,让智能体能够自动搜索最新的市场动态、公司财报和行业报告。系统能够理解复杂的金融查询,如"分析特斯拉Q3财报对电动汽车行业的影响",并自动搜索相关信息进行综合分析。
业务价值:该应用显著提升了金融研究效率,研究员能够获得更丰富且上下文相关的市场情报。原本需要数小时的人工研究工作,现在可以在几分钟内完成初步分析。
技术架构要点:
- 使用GPT-4o模型确保Web Search功能可用
- 实现查询结果的结构化处理和来源追踪
- 集成风险控制机制,确保信息准确性
Navan旅行助手:File Search知识库实践
应用场景:Navan公司的AI旅行助手使用File Search工具从知识库文章(如公司的旅行政策)中精准提取答案,实现了强大的内部知识问答能力。
实施策略:系统将公司的旅行政策、报销规定、酒店合作伙伴信息等文档上传到File Search系统中。当员工询问具体的旅行政策问题时,智能体能够准确定位相关条款并提供详细解答。
成本效益分析:虽然File Search按查询次数计费(每千次$2.50),但相比人工客服的人力成本,该解决方案实现了显著的成本节约。同时,24/7可用性大大提升了员工体验。
实施经验:
- 文档结构化处理是关键,需要将政策文档进行合理分割
- 定期更新知识库内容,确保信息时效性
- 建立反馈机制,持续优化回答质量
Unify销售智能体:Computer Use营销创新
创新应用:Unify公司利用Computer Use工具构建销售智能体,能够访问网络地图核实某企业的地产扩张情况,作为触发定制营销策略的信号。
技术挑战与解决方案:考虑到Computer Use工具目前38.1%的成功率限制,Unify实施了多重保障机制:
- 任务分解:将复杂操作拆分为简单步骤
- 错误检测:实时监控操作结果,及时发现失败
- 人工介入:关键决策环节保留人工审核
业务影响:该系统能够自动收集潜在客户的公开信息,为销售团队提供个性化的营销策略建议,显著提升了销售效率和成功率。
Luminai系统自动化:RPA替代方案
突破性成果:据权威案例报告,Luminai在几天内就实现了传统RPA几个月都难以完成的遗留系统操作自动化流程。
技术优势:与传统RPA需要精确的界面元素定位不同,Computer Use工具基于视觉理解,能够适应界面变化。这种灵活性使得系统能够处理各种遗留系统,无需为每个系统单独开发适配器。
实施策略:
- 选择成功率要求不高的批处理任务作为起点
- 建立详细的操作日志,便于问题追踪和优化
- 设计回滚机制,确保操作失败时能够恢复到初始状态
ROI分析:虽然Computer Use工具成功率有限,但其开发和部署速度远超传统RPA,在快速原型和概念验证阶段具有明显优势。
OpenAI Agents高级应用技巧:多智能体协作与编排
随着OpenAI Agents应用复杂度的提升,单一智能体往往难以满足企业级应用的多样化需求。多智能体系统通过专业化分工和协作机制,能够处理更加复杂的业务场景。
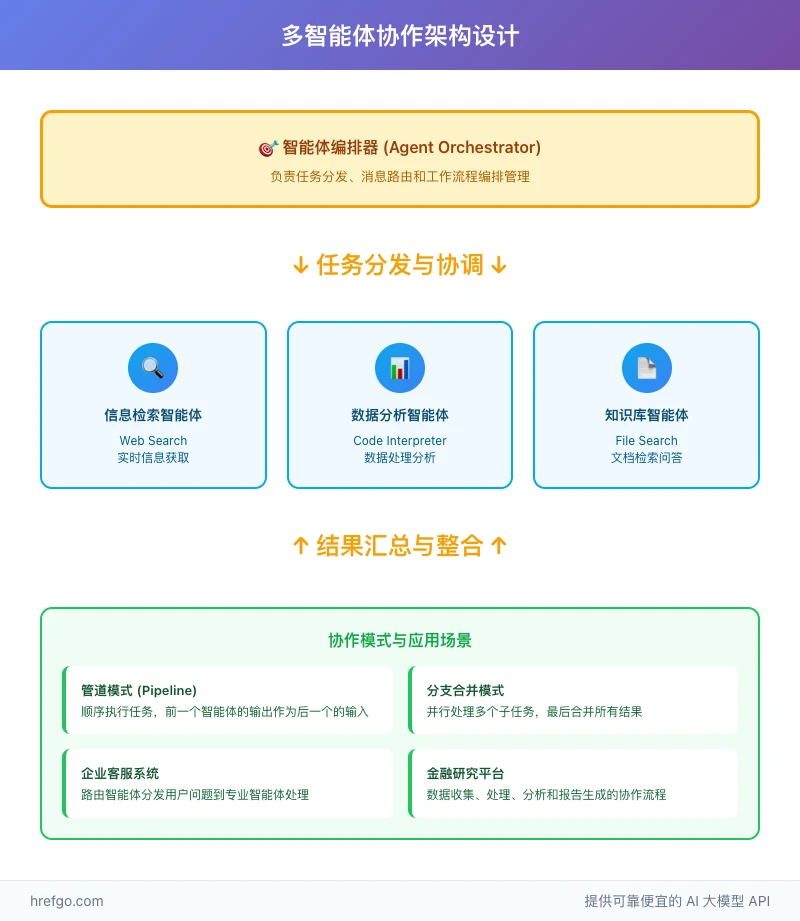
多智能体架构设计原则
专业化分工原则:不同的智能体应该专注于特定的功能领域。例如,一个智能体专门处理文档检索,另一个专门进行数据分析,第三个负责生成报告。这种分工能够提高每个智能体的专业性和处理效率。
松耦合设计:各智能体之间应该通过标准化的接口进行通信,避免紧密耦合。这样的设计便于系统扩展和维护,也能够独立优化各个组件的性能。
容错性考虑:多智能体系统需要考虑单个智能体失败的情况。设计时应该包含备用机制和错误恢复策略,确保整个系统的稳定性。
智能体间通信和协调机制
消息传递架构:
class AgentOrchestrator:
def __init__(self):
self.agents = {}
self.message_queue = []
def register_agent(self, agent_id, agent_instance):
"""注册智能体到编排器"""
self.agents[agent_id] = agent_instance
def route_message(self, from_agent, to_agent, message, task_type):
"""智能体间消息路由"""
if to_agent in self.agents:
response = self.agents[to_agent].process_message(
message,
context={"from": from_agent, "task_type": task_type}
)
return response
else:
raise ValueError(f"目标智能体 {to_agent} 不存在")
def orchestrate_workflow(self, workflow_config):
"""编排多智能体工作流"""
results = {}
for step in workflow_config["steps"]:
agent_id = step["agent"]
input_data = self.prepare_input(step, results)
result = self.agents[agent_id].execute_task(
task=step["task"],
input_data=input_data
)
results[step["step_id"]] = result
return self.combine_results(results, workflow_config["output_format"])
协调策略实现:
- 顺序执行:适用于有明确依赖关系的任务序列
- 并行执行:多个独立任务可以同时进行,提高整体效率
- 条件执行:根据前一步的结果决定后续的执行路径
状态同步机制:在复杂的多智能体系统中,维护全局状态一致性至关重要。可以通过共享状态存储或事件发布订阅模式来实现状态同步。
智能体协作的实际应用场景
场景一:企业客户服务系统 在大型企业的客户服务场景中,可以部署多个专业化智能体:
- 路由智能体:接收用户询问,分析问题类型并路由到专业智能体
- 技术支持智能体:使用Code Interpreter处理技术问题和故障排除
- 销售咨询智能体:利用File Search检索产品信息和价格政策
- 升级处理智能体:当问题复杂时,使用Computer Use填写工单系统
这种分工协作的架构不仅提高了处理效率,还能确保每个智能体在其专业领域内提供高质量的服务。
场景二:金融研究分析平台 借鉴Hebbia的成功案例,可以构建如下的智能体协作系统:
- 数据收集智能体:使用Web Search实时收集市场数据和新闻
- 数据处理智能体:利用Code Interpreter进行数据清洗和统计分析
- 知识检索智能体:通过File Search查询历史报告和研究资料
- 报告生成智能体:综合所有信息,生成结构化的分析报告
智能体编排的高级模式
管道模式(Pipeline Pattern):
class AgentPipeline:
def __init__(self):
self.stages = []
self.results = {}
def add_stage(self, agent_id, agent_instance, depends_on=None):
"""添加管道阶段"""
self.stages.append({
'agent_id': agent_id,
'agent': agent_instance,
'depends_on': depends_on or []
})
def execute_pipeline(self, initial_input):
"""执行整个管道"""
for stage in self.stages:
# 检查依赖是否完成
dependencies_met = all(
dep in self.results for dep in stage['depends_on']
)
if dependencies_met:
# 准备输入数据
if stage['depends_on']:
stage_input = {
'initial': initial_input,
'dependencies': {dep: self.results[dep] for dep in stage['depends_on']}
}
else:
stage_input = initial_input
# 执行智能体任务
result = stage['agent'].process(stage_input)
self.results[stage['agent_id']] = result
return self.results
分支合并模式(Fork-Join Pattern): 适用于需要并行处理多个子任务,然后合并结果的场景:
import asyncio
from typing import List, Dict, Any
class ForkJoinOrchestrator:
def __init__(self):
self.agents = {}
async def fork_join_execution(self, task_groups: List[Dict[str, Any]]):
"""并行执行多个任务组,然后合并结果"""
async def execute_group(group):
tasks = []
for task in group['tasks']:
agent = self.agents[task['agent_id']]
tasks.append(agent.async_process(task['input']))
# 等待组内所有任务完成
results = await asyncio.gather(*tasks)
return {
'group_id': group['group_id'],
'results': results
}
# 并行执行所有组
group_tasks = [execute_group(group) for group in task_groups]
group_results = await asyncio.gather(*group_tasks)
# 合并最终结果
return self.merge_results(group_results)
def merge_results(self, group_results):
"""合并各组的执行结果"""
merged = {
'summary': {},
'detailed_results': {},
'performance_metrics': {}
}
for group_result in group_results:
group_id = group_result['group_id']
merged['detailed_results'][group_id] = group_result['results']
return merged
这些高级编排模式能够处理复杂的业务流程,实现智能体之间的高效协作,同时保持系统的可扩展性和可维护性。
故障排除和性能优化指南
在实际部署智能体系统时,故障诊断和性能优化是确保系统稳定运行的关键环节。基于社区反馈和实际项目经验,以下是常见问题的解决方案。
常见错误代码和解决方案
API调用错误处理:
import openai
from typing import Dict, Any
import time
import logging
class ErrorHandler:
def __init__(self):
self.logger = logging.getLogger(__name__)
def handle_api_error(self, error) -> Dict[str, Any]:
"""统一的API错误处理"""
if isinstance(error, openai.RateLimitError):
self.logger.warning("触发速率限制,建议实施重试策略")
return {
"error_type": "rate_limit",
"retry_after": error.retry_after if hasattr(error, 'retry_after') else 60,
"solution": "实施指数退避重试策略"
}
elif isinstance(error, openai.APIConnectionError):
self.logger.error("网络连接错误")
return {
"error_type": "connection",
"solution": "检查网络连接和防火墙设置"
}
elif isinstance(error, openai.AuthenticationError):
self.logger.error("认证失败")
return {
"error_type": "authentication",
"solution": "检查API密钥是否正确且未过期"
}
elif isinstance(error, openai.BadRequestError):
self.logger.error(f"请求参数错误: {error}")
return {
"error_type": "bad_request",
"solution": "检查请求参数格式和模型支持能力"
}
else:
self.logger.error(f"未知错误: {error}")
return {
"error_type": "unknown",
"solution": "查看完整错误日志并联系技术支持"
}
社区高频问题解决方案:
- Token超限错误:优化消息历史管理,实施智能截断策略
- 模型不支持工具调用:确认使用支持Function Calling的模型版本
- 工具调用格式错误:验证工具定义的JSON Schema格式正确性
性能监控和优化技术
响应时间优化:
import time
from functools import wraps
def performance_monitor(func):
"""性能监控装饰器"""
@wraps(func)
def wrapper(*args, **kwargs):
start_time = time.time()
try:
result = func(*args, **kwargs)
end_time = time.time()
duration = end_time - start_time
# 记录性能指标
print(f"函数 {func.__name__} 执行时间: {duration:.2f}秒")
# 性能告警
if duration > 30: # 超过30秒告警
print(f"警告:{func.__name__} 执行时间过长")
return result
except Exception as e:
end_time = time.time()
duration = end_time - start_time
print(f"函数 {func.__name__} 执行失败,耗时: {duration:.2f}秒")
raise e
return wrapper
@performance_monitor
def agent_process_request(self, user_input):
"""带性能监控的请求处理"""
return self.create_agent_response(user_input)
成功率监控: 建立comprehensive的监控体系,跟踪关键指标:
- API调用成功率
- 平均响应时间
- 工具调用成功率
- 用户满意度评分
优化建议:
- 缓存策略:对重复查询实施智能缓存
- 并发控制:合理设置并发请求数,避免触发速率限制
- 资源预热:对于冷启动场景,实施预热机制减少首次请求延迟
常见问题解答
Q1: OpenAI API免费吗?如何计费?
A: OpenAI API采用按使用量计费模式,不提供永久免费服务。具体计费方式包括:
- 模型调用费用:按输入和输出token数量计费,不同模型价格不同
- 工具使用费用:根据权威定价数据,File Search每千次查询$2.50,其他工具也有相应费用
- 存储费用:上传到系统的文件按存储容量收费
新用户通常会获得一定额度的免费试用额度,但正式使用需要付费。建议在开发阶段仔细评估成本,实施有效的成本控制策略。
Q2: Assistants API和Responses API有什么区别?
A: 两个API存在重要的架构和功能差异:
技术架构:Assistants API基于Thread模式,需要创建和管理对话线程;Responses API采用更直接的请求-响应模式,简化了状态管理。
工具调用能力:Responses API集成了更强的多工具编排能力,支持在单次请求中自动完成多个工具的协作调用,而Assistants API需要多轮交互。
迁移计划:根据OpenAI官方时间表,Assistants API将在2026年中正式弃用,建议新项目直接使用Responses API。
Q3: 如何提高Computer Use工具的成功率?
A: Computer Use工具目前成功率约38.1%,仍在研究预览阶段。提高成功率的策略包括:
任务简化:将复杂操作分解为简单的步骤,避免一次性执行复杂的界面操作序列。
错误处理:实施robust的错误检测和重试机制,当操作失败时能够自动重试或转为人工处理。
场景选择:优先在稳定、简单的界面环境中使用,避免在复杂或经常变化的界面中部署。
监督机制:保持人工监督,特别是在执行重要操作时,确保及时发现和纠正错误。
Q4: 智能体开发需要哪些技术基础?
A: 成功开发OpenAI智能体需要以下技术基础:
编程技能:
- 熟练掌握Python编程,理解异步编程和错误处理
- 了解RESTful API调用和JSON数据处理
- 具备基本的软件工程实践,如版本控制、测试和部署
AI知识背景:
- 理解大语言模型的基本原理和限制
- 掌握Prompt Engineering技巧和最佳实践
- 了解向量数据库和RAG系统的工作原理
系统设计能力:
- 能够设计可扩展的系统架构
- 理解缓存、错误处理和性能优化策略
- 具备多智能体系统的协作设计经验
建议初学者先从简单的单一功能智能体开始,逐步积累经验后再开发复杂的多智能体系统。
Q5: 智能体的响应时间如何优化?
A: 智能体响应时间优化是用户体验的关键因素。基于实际部署经验,以下是有效的优化策略:
请求优化技术:
- Stream响应模式:使用streaming模式实时返回部分结果,而不是等待完整响应
- 并行工具调用:当多个工具调用彼此独立时,使用异步并行处理
- 智能缓存策略:对频繁查询的结果实施缓存,减少重复API调用
模型选择优化:
- 根据任务复杂度选择合适的模型,简单任务使用更快的模型
- 利用模型的上下文窗口优化,减少不必要的上下文传递
架构层面优化:
- 实施请求池化和连接复用,减少网络延迟
- 使用CDN或边缘计算,将计算资源部署在用户附近
Q6: 如何处理智能体的幻觉问题?
A: 大语言模型的幻觉问题在智能体应用中需要特别关注。实用的缓解策略包括:
输入验证和约束:
- 使用Structured Outputs确保输出格式的一致性
- 实施输入验证,拒绝不合理或超出能力范围的请求
知识源验证:
- 优先使用File Search等工具从可靠知识库获取信息
- 对Web Search结果实施多源验证
- 在回答中明确标注信息来源和可信度
后处理检查:
- 实施事实核查机制,对关键信息进行二次验证
- 使用另一个智能体作为审查者,检查输出的合理性
Q7: 企业部署智能体需要考虑哪些安全问题?
A: 企业级智能体部署的安全考虑涵盖多个层面:
数据安全:
- 确保敏感数据在传输和存储过程中的加密
- 实施数据脱敏处理,避免在日志中记录敏感信息
- 建立数据保留和清理政策
访问控制:
- 实施基于角色的访问控制(RBAC)
- 使用API密钥轮换和权限最小化原则
- 建立审计日志,记录所有系统访问和操作
模型安全:
- 防范提示注入攻击,验证和清理用户输入
- 实施输出内容过滤,防止生成不当内容
- 建立应急响应机制,快速处理安全事件
Q8: 如何评估智能体系统的业务价值?
A: 智能体系统的ROI评估需要从多个维度进行:
直接成本节约:
- 人工成本减少:计算被智能体替代的人工工作时间
- 操作效率提升:衡量任务完成时间的缩短
- 错误率降低:量化因人工错误导致的损失减少
业务增长指标:
- 用户体验改善:通过NPS、CSAT等指标衡量
- 服务可用性提升:24/7服务能力带来的业务增长
- 新业务机会:智能体能力带来的新的商业模式
技术债务和维护成本:
- 系统开发和部署成本
- 持续的API使用费用和维护成本
- 团队技能培训和知识转移成本
根据Luminai等成功案例,智能体系统通常在部署后3-6个月开始显现明显的ROI,关键在于选择合适的应用场景和制定合理的成功指标。
总结和要点回顾
通过这份基于权威素材的完整指南,我们深入探讨了如何使用OpenAI Agent API构建智能体系统的全过程。从基础概念到企业级应用,本指南涵盖了智能体开发的关键要素和实践经验。
核心技术要点回顾: OpenAI Agent API的核心价值在于让LLM从被动对话者转变为具备行动能力的智能体。Responses API作为新一代开发接口,集成了更强的多工具编排能力,支持Web Search、File Search、Code Interpreter和Computer Use四种内置工具,覆盖了从信息检索到任务执行的完整能力谱系。
实战价值体现: 通过Hebbia金融研究平台、Navan旅行助手、Unify销售智能体和Luminai自动化系统等权威企业案例,我们看到了智能体技术在不同行业中的成功应用。这些案例证明,合理运用OpenAI function calling和内置工具,能够显著提升业务效率和用户体验。
成本与性能平衡: 在成本控制方面,File Search工具每千次$2.50的定价和Computer Use工具38.1%的成功率等权威数据,为开发者提供了重要的决策参考。通过智能缓存、模型选择优化和错误处理策略,可以在保证功能的前提下有效控制运营成本。
技术发展趋势: 随着Assistants API在2026年中的弃用和Responses API的全面推广,openai agent api的使用将更加简化和高效。多智能体协作和编排技术的发展,为构建复杂的企业级AI系统提供了新的可能性。未来,openai agent api将继续进化,支持更复杂的工作流和更智能的决策能力。
下一步行动建议: 建议您立即开始第一个智能体项目的开发。从简单的单一功能开始,例如基于File Search的知识问答系统或使用Web Search的信息检索助手。通过实际项目积累经验,逐步掌握多工具编排和复杂场景处理的技能。
掌握OpenAI Agent API不仅是技术能力的提升,更是在AI时代构建智能体系统的核心技能。OpenAI Agent API,更是把握AI时代机遇的重要一步。随着智能体技术的不断成熟和应用场景的持续拓展,现在正是深入学习和实践OpenAI Agent API技术的最佳时机。
新手友好提醒:
- 如果正在使用OpenAI Assistant API,请开始规划向Responses API的迁移
- 优先选择GPT-5系列模型以获得最佳性价比
- 利用Batch API的50%折扣来降低开发和测试成本
学习资源建议:
- 深入研读OpenAI官方文档和cookbook示例
- 参考GitHub上成功的开源项目,特别是6242个相关项目中的优秀实现
- 关注OpenAI的技术博客和更新公告,及时了解新功能
- 加入开发者社区,分享经验和解决方案
未来发展方向: 随着Computer Use工具成功率的不断提升和新工具的持续推出,智能体技术将在更多行业发挥重要作用。现在投入到OpenAI Agent API的学习和实践中,将为您在AI技术浪潮中占据有利位置,创造更大的商业价值。