
TL;DR
- 400K 上下文 + 思考(Reasoning Tokens):长文档与大代码库一次吃下,复杂推理更稳。
- Responses API 集中承载新特性:
reasoning.effort、text.verbosity、tool_choice.allowed_tools、CFG、Custom Tools。 - 三款模型分层定价:标准 / Mini / Nano;缓存输入最高 90% 折扣,批量可叠加 Batch 优惠。
- 四维度显著进步:编程、数学、科学推理、多模态均有提升(以官方与公开评测为准)。
- Agent 与 MCP:原生工具生态 + 标准协议,易接企业数据库/CRM/API。
- 生产实践路线:场景路由 → 参数分级(effort/verbosity)→ 缓存/批处理 → 监控与成本守护。
OpenAI GPT-5 作为2025年最重要的人工智能突破,远超传统大语言模型的性能边界。这不仅是简单的版本升级——GPT-5在推理能力、编程辅助和数学计算方面实现了质的飞跃。凭借突破性的推理Token机制和400K上下文窗口,GPT-5重新定义了AI与人类协作的可能性。本完整指南将深度解析GPT-5的核心功能特性、三种定价模型、API集成方法,以及在实际业务场景中的最佳实践。
GPT-5的智能路由系统是其最具创新性的特色功能。当面对复杂数学证明时,模型自动启用深度推理模式;处理大规模代码库分析时,调用专门的编程理解机制;而在日常文档写作中,则切换至高效的内容生成模式。这种自适应AI处理能力使GPT-5在不同应用场景下都能提供最优性能表现。
GPT-5 核心能力速览
长上下文与知识更新
- 上下文窗口:400,000 tokens(最高值,具体配额以账号/区域为准)。
- 输出上限:128,000 tokens,长文生成更稳定。
- 知识库时间:更新至 2024-10-01(模型仍可通过工具检索最新资料)。
推理 Tokens(思考)与质量
- 隐藏推理 Tokens 支持多步推导,提升复杂任务稳定性与正确率。
- 典型收益:数学推理、科学问答、系统设计、代码调试/审阅。
多模态(文+图)
- 视觉理解、图表/工程图、数据可视化解析与 UI → 代码转译精度提升。
- 当前音频/视频以官方开放为准。
GPT-5核心功能深度解析

GPT-5基础能力全面升级:400K上下文与知识库更新
OpenAI GPT-5 的技术规格代表了大语言模型的新标杆。最显著的提升是 400,000 token 的超大上下文窗口——相比 GPT-4 的 128K 提升了300%,这一突破使GPT-5能够一次性分析完整的技术文档、处理大规模代码库,或深度理解长篇学术论文,为AI在复杂场景的应用奠定了基础。
128,000 token 的输出上限也保证了生成长文档时不会出现突然截断的情况。
知识库更新到 2024 年 10 月 1 日,涵盖了更多最新的技术发展和行业动态。对于关注前沿技术的开发者来说,这个更新很实用——特别是 AI 领域变化这么快,多几个月的新信息就能带来很大差别。
推理Token机制是 GPT-5 最具革命性的创新技术。这一机制让AI模型具备了类似人类的深度思考能力,通过生成隐藏的推理Token进行多步逻辑分析——用户无法看到具体思考过程,但能明显感受到答案准确性和逻辑严密性的质的飞跃。
在数学推理与科学计算领域,这一技术突破表现尤为亮眼:GPT-5在AIME 2025数学竞赛中创造了 94.6% 的惊人正确率,结合Python代码执行工具更是达到了完美的100%准确率。这一成绩不仅超越了所有竞争对手,更标志着AI在复杂推理任务中的历史性突破。
GPT-5多模态AI能力:图像理解与代码生成
在多模态AI处理能力方面,GPT-5 当前主要支持 文本与图像的智能交互,虽然音频功能尚未开放,但其视觉理解能力已达到业界领先水平——在权威的MMMU 基准测试中取得了 84.2% 的优异成绩,显著超越了同类AI模型。
GPT-5在图像分析、数据可视化理解、空间关系推理等复杂视觉任务中表现卓越,能够准确识别图表趋势、理解工程图纸、分析医疗影像等专业场景。
特别值得关注的是GPT-5在UI/UX设计转代码领域的突出表现。相比传统AI模型生成的代码需要大量后期调整,GPT-5能够精准理解设计稿中的间距、色彩、布局细节,生成的HTML/CSS代码几乎可以直接部署,大幅提升了前端开发效率和设计还原度。
GPT-5推理能力革命性突破:reasoning_effort参数详解
GPT-5引入的reasoning_effort智能推理参数是AI领域的重大创新,它让用户能够精确控制模型的**"认知计算深度"**。该参数提供四个递进级别:minimal(快速响应)、low(轻度分析)、medium(平衡推理)、high(深度思考),用户可根据任务复杂度和成本预算灵活选择最优配置。
这种智能推理级别控制实现了AI应用的成本效益最大化:简单查询任务使用 minimal 级别确保快速响应和低成本;而面对复杂的逻辑推理、数学证明或系统架构设计等高难度任务时,启用 high 级别能显著提升输出质量和准确性。
在软件工程与编程辅助领域,GPT-5的推理能力提升效果显著:在权威的 SWE-bench Verified 编程基准测试中达到了 74.9% 的行业领先成绩,较传统模式提升了22.1个百分点。在Aider Polyglot 多语言编程评测中更是创下了 88% 的卓越表现,其中thinking模式的深度推理功能贡献了61.3分的关键提升,充分证明了智能推理在复杂编程任务中的核心价值。
GPT-5 Agent化应用:MCP协议与工具集成生态
GPT-5的Agent化智能应用代表了人工智能从被动响应向主动执行的根本性转变。模型内置了强大的智能工具生态系统,包括Web实时搜索、文件深度分析、Python代码解释器等核心功能,更重要的是完全支持MCP(Model Context Protocol)行业标准,构建了开放的AI工具集成平台。
这一革新让GPT-5从传统的"问答式AI"进化为主动执行的智能代理:能够自主搜索最新信息、分析复杂文档、运行程序代码、调用外部API,真正实现了AI与现实世界的深度连接。OpenAI提供的官方API文档详细介绍了各种工具的集成方法和企业级最佳实践。
GPT-5工具调用定价策略透明且合理:Web搜索 $10/1000次、文件搜索 $2.50/2000次、代码解释器 $0.03/容器,采用按需付费模式,让企业用户能够精准控制AI应用成本。
MCP协议的深度支持为开发者生态提供了无限扩展可能。通过标准化的工具接口,开发者可以轻松创建自定义工具,将GPT-5与企业数据库、CRM系统、业务流程无缝集成。
上下文无关语法(CFG)支持,包括Lark和正则表达式语法,为需要精确输出格式的企业应用提供了强大的结构化输出控制能力,在法务文档生成、财务报表制作、技术规范编写等专业领域展现出巨大价值。
GPT-5 API 新特性速览
A. 推理与输出
| 能力模块 | 关键参数/接口 | 常见场景 |
|---|---|---|
| 推理深度控制 | `reasoning: { effort: minimal | low | medium | high }` | 数学证明、方案评审、诊断决策 |
| 输出详细度 | `text: { verbosity: low | medium | high }` | 客服(medium)、技术文档(high) |
| Preambles 前言 | 在 instructions 中约定调用工具前给出简要说明 | 高风险操作、审计可解释 |
B. 工具与权限
| 工具与权限 | 关键参数/接口 | 价值要点 |
|---|---|---|
| Custom Tools | tools: [{ type: "custom", ... }] | 直接传递原始文本(代码/SQL/配置) |
| Allowed Tools 白名单 | tool_choice: { type: "allowed_tools", ... } | 权限收敛,提升缓存命中 |
| MCP 标准 | tools: [{ type: "mcp", server_label: "..." }] | 标准化接入企业后端 |
C. 结构化与接口
| 结构化与接口 | 关键参数/接口 | 典型用途 | |
|---|---|---|---|
| CFG 语法约束 | `format: { type: "grammar", syntax: lark | regex, definition: ... }` | DSL/SQL/报表等强格式 |
| Responses API | client.responses.create(...) | 集中承载新特性 | |
| 推理链传递 | previous_response_id | 长链路任务衔接与复用 |
GPT-5模型版本完整对比:标准版、Mini、Nano定价分析
OpenAI GPT-5 采用了分层定价策略,推出三个差异化版本以满足不同用户的性能需求和预算限制。从追求极致性能的GPT-5标准版,到平衡性价比的Mini版,再到高性价比的Nano版,每个版本都针对特定的应用场景进行了优化,帮助用户在功能需求与成本控制之间找到最佳平衡点。
API 定价
| 版本 | 典型场景 | 输入价 | 输出价 | 缓存输入 | 上下文窗口 | 推理/多模态 |
|---|---|---|---|---|---|---|
| GPT-5(标准) | 科研/复杂推理、企业开发、Agent 中枢 | $1.25 | $10 | $0.125 | 400K | 完整推理 & 视觉 |
| GPT-5 Mini | 客服、内容、教育、日常开发 | $0.25 | $2.0 | $0.025 | 400K* | 核心推理 & 视觉 |
| GPT-5 Nano | 批量分类/审核、格式转换、翻译 | $0.05 | $0.40 | $0.005 | 400K* | 轻量推理 |
* 配额依账号/区域策略不同。
GPT-5 标准版
GPT-5标准版是OpenAI的旗舰AI模型,代表了当前人工智能技术的最高水准,专为企业级复杂应用和高精度推理任务设计。该版本拥有完整的推理Token机制、最大的上下文处理能力和最强的多模态理解功能。
定价策略极具竞争优势:输入Token仅需 $1.25/百万,输出Token $10/百万,相比GPT-4的$2.00输入价格,成本降低了37.5% 的同时性能却显著提升。更值得关注的是缓存输入享受90%折扣,仅需 $0.125/百万Token,为高频使用场景提供了极大的成本优势。详细的定价信息可查阅OpenAI官方定价页面。
GPT-5标准版的应用优势集中体现在:科学研究与数学推理、企业级软件开发、智能Agent系统构建、大规模数据分析等高价值场景。在处理复杂代码库重构、学术论文分析、多步骤逻辑推导、系统架构设计等任务时,标准版的深度推理能力展现出明显优势。
在权威的GPQA Diamond科学推理基准测试中,GPT-5标准版(thinking模式)达到了85.7%的优异成绩,在物理、化学、生物等复杂科学问题的推理准确性方面树立了新的行业标杆。
GPT-5 Mini
GPT-5 Mini 定位为性价比最优的智能选择,以 $0.25/$2(输入/输出每百万Token)的亲民定价,为中小企业和个人开发者提供了接近标准版的AI能力。该版本保留了核心的推理功能,但通过优化算法降低了计算成本,缓存输入低至 $0.025/百万Token,为预算敏感的项目提供了理想的解决方案。
GPT-5 Mini的核心优势体现在明确任务导向的应用场景:智能客服系统、内容营销创作、技术文档处理、教育辅助应用、中等复杂度的数据分析等常见商业用例中表现出色,能够满足90%以上的企业AI应用需求。
虽然在极端复杂推理任务中略逊于标准版,但GPT-5 Mini在绝大多数商业场景中的表现已足够出色,特别是在需要大规模部署、成本控制严格的企业环境中,其卓越的性价比使其成为最受欢迎的选择。
GPT-5 Nano
GPT-5 Nano 专为大规模、高吞吐量AI应用量身定制,以极致性价比重新定义了人工智能的经济门槛:输入仅需 $0.05、输出 $0.40(每百万Token)的超低定价,配合缓存输入 $0.005/百万Token 的惊人折扣,使其成为市场上最具成本效益的高性能AI模型。
GPT-5 Nano的性能特色在于超高处理速度与批量任务优化,专门针对文本分类、数据标注、内容审核、格式转换、批量翻译等标准化任务进行了深度优化,能够以极快的响应速度处理大量重复性工作。
虽然在复杂推理方面不如标准版和Mini版,但GPT-5 Nano在明确指令执行、结构化数据处理等场景中表现出色且极其可靠。对于需要处理海量数据的电商平台、内容平台、数据服务公司而言,Nano版本能够显著降低AI应用的运营成本,同时保持良好的处理质量,是大规模AI部署的理想选择。
选择指南
选哪个版本主要看具体场景和预算:
选标准版的场景:
- 复杂数学和科学推理
- 大型软件项目代码分析
- 高准确性要求的医疗法律辅助
- 多模态复杂任务
选 Mini 的场景:
- 商业客服和售后
- 营销文案和内容创作
- 中等难度编程任务
- 教育辅导和知识问答
选 Nano 的场景:
- 大量文本分类和数据标注
- 简单格式转换和数据处理
- 高频 API 调用应用
- 成本敏感的原型验证
成本效益分析表:
| 场景类型 | 推荐版本 | 月成本估算* | 性能预期 |
|---|---|---|---|
| 企业级复杂应用 | GPT-5 标准版 | $500-2000 | 最佳 |
| 中小型商业应用 | GPT-5 Mini | $100-500 | 优秀 |
| 大规模简单任务 | GPT-5 Nano | $50-200 | 良好 |
*基于月处理 100 万 token 的估算

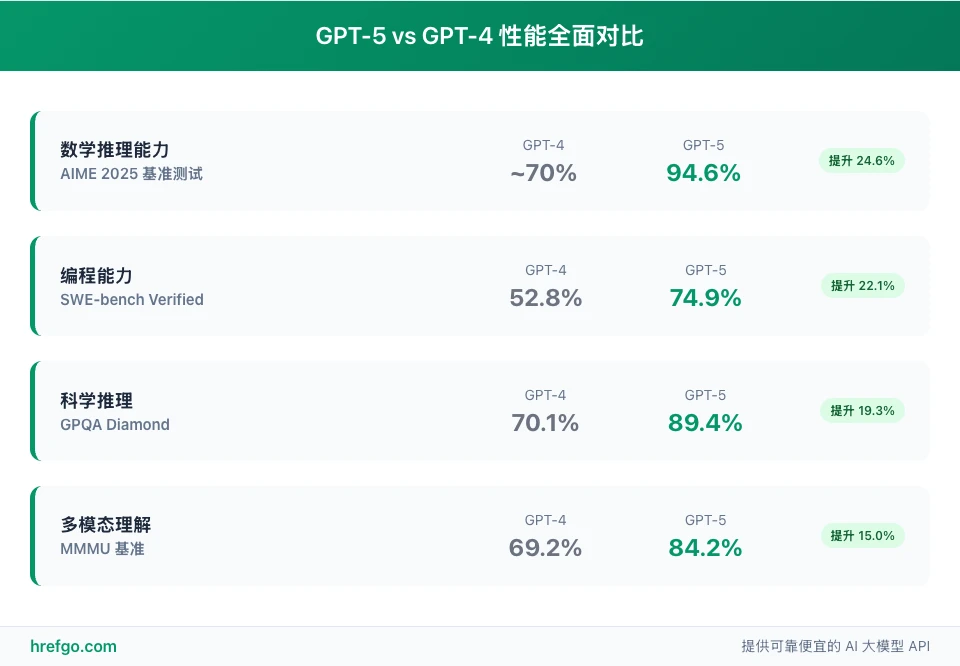
GPT-5 vs GPT-4全面性能对比:编程、数学、多语言能力对比
GPT-5 对比 GPT-4 的提升相当明显,从各项测试数据能明显看出技术进步。
| 维度 | GPT-5 | GPT-4 系列 | 变化 |
|---|---|---|---|
| 数学/科学推理 | 显著提升 | 中等 | 难题命中率更稳 |
| 编程 | 通过率显著提升 | 较好 | 大仓分析/重构更可靠 |
| 多模态 | 更强图表/工程图理解 | 较好 | UI → 代码转译更可用 |
| 长上下文 | 400K | 128K | 跨文档/大代码库一口气读懂 |
| 事实稳定性 | 更稳 | 有波动 | 幻觉减少 |
基准测试结果分析
数学推理是 GPT-5 最亮眼的表现。在 AIME 2025 数学测试中,不用工具就达到 94.6 % 准确率,加上 Python 工具后直接 100 % 满分。
这个成绩不只是比 GPT-4 好很多,在所有公开模型中都是第一。
编程能力也有大幅提升。SWE-bench Verified 测试中达到 74.9 %,比 GPT-4 提升了约 30 %。Aider Polyglot 多语言编程测试更是达到 88 %,说明在不同编程语言上都有不错的一致性。
特别是 thinking 模式下,编程质量有了质的飞跃。
科学推理上,GPT-5 在 GPQA Diamond 测试中达到 89.4 %(Pro 版),比 GPT-4 o 的 70.1 % 高了将近 20 个百分点。
在复杂科学问题、学术研究和专业咨询方面,这个提升相当有价值。
多模态理解的 84.2 % 成绩(MMMU 测试)显示了 GPT-5 在图像理解、空间推理和视觉分析上的强大能力。UI/UX 设计、建筑规划、医疗影像分析等领域都有不错的应用前景。
实际使用场景对比
在 编程效率 上,GPT-5 的优势很明显。根据开发者反馈,编程任务效率比 GPT-4 提升了 约 29 %。代码审查质量也提升了 5 %,处理大项目和复杂业务逻辑时表现更好。
数学推理的实际应用效果也很不错。有教育机构用 GPT-5 做数学辅导,发现它不只是答案正确,还能给出清晰的解题思路和步骤。
在金融建模、工程计算这些需要精准计算的领域,GPT-5 的可靠性提升明显。
文本生成质量上,GPT-5 保持创造性的同时,事实准确性也显著改善。使用 Web search 功能时,事实错误比 GPT-4o 减少了 45%。
在新闻写作、技术文档、学术论文这些对准确性要求高的场景中,这点改进特别重要。
多语言处理也有提升。GPT-5 在中文、日语、西班牙语这些非英语语言上表现更自然,对做全球化应用的开发者来说是个好消息。
错误率和可靠性改进
最重要的改进可能是 幻觉问题的明显改善。thinking 模式下,事实错误比 OpenAI o3 减少了 80%。对需要高可靠性的企业应用来说,这个改进非常关键。
医疗领域的表现特别值得关注。在 HealthBench 测试中,GPT-5 的错误率只有 1.6%,在医疗咨询辅助、症状分析这些敏感领域的可信度更高。
当然,GPT-5 仍然不能替代医生,但可以作为理解医疗信息和辅助决策的工具。
欺骗和误导行为的控制也有所改善。在真实使用测试中,欺骗率从 o3 的 4.8% 下降到 GPT-5 推理响应的 2.1%,说明模型在伦理和安全方面有了进步。
GPT-5独家功能与API新特性:推理Token机制与工具调用
GPT-5推理 token 机制
推理 token 机制可能是 GPT-5 最有意思的功能。模型会产生 隐藏的推理 token,在给出最终答案前先思考一番。
用户看不到这个过程,但结果会更准确。这对需要多步推理的任务特别有用,比如数学证明、逻辑分析、代码 debug 等。
推理深度控制让用户能精确调节模型的“思考深度”。通过 reasoning_effort 参数,可以在 minimal、low、medium、high 四个级别中选择,在速度和准确性之间找平衡。
简单任务用 minimal,复杂问题用 high,既能控成本又能保效果。
GPT-5智能详细度控制:verbosity参数
verbosity参数是GPT-5的重要创新功能,能够精确控制模型回复的详细程度和长度,有效解决了传统AI回复过于简单或冗长的问题。该参数提供high、medium(默认)、low三个级别,让开发者能够根据具体应用场景灵活调节输出风格。
三种verbosity级别的具体差异:
Low Verbosity(简洁模式):
- 生成最少的输出token,优化响应速度
- 提供核心答案,省略详细解释
- 代码生成时产出简洁的功能性代码,最少注释
- 适用场景:SQL查询生成、简单问答、API响应、批量处理
Medium Verbosity(平衡模式):
- 默认设置,提供适中的详细程度
- 包含必要的解释和上下文信息
- 代码带有适量注释和结构化组织
- 适用场景:大多数商业应用、客服机器人、教育辅助
High Verbosity(详细模式):
- 生成最详细的输出,包含全面解释
- 提供深度分析和多角度思考
- 代码包含完整文档、错误处理、最佳实践
- 适用场景:技术文档生成、代码重构、学术研究、复杂系统设计
示例:
from openai import OpenAI
client = OpenAI()
# 简洁代码生成(low)
resp_low = client.responses.create(
model="gpt-5",
input="创建一个Python函数来计算圆的面积",
text={"verbosity": "low"}
)
# 详细代码生成(high)
resp_high = client.responses.create(
model="gpt-5",
input="创建一个Python函数来计算圆的面积",
text={"verbosity": "high"}
)
不同应用场景的verbosity选择策略:
| 应用场景 | 推荐verbosity | 原因分析 |
|---|---|---|
| API文档生成 | High | 需要完整的参数说明和示例 |
| 智能客服回复 | Medium | 平衡信息完整性和回复效率 |
| 代码自动生成 | Low-Medium | 简洁可读,避免过度注释 |
| 学术研究辅助 | High | 需要深度分析和全面论证 |
| 数据分析报告 | High | 要求详细的数据解读和洞察 |
| 快速问答系统 | Low | 优化响应速度,直接给出答案 |
verbosity对性能和成本的影响:
- Token消耗:High模式token消耗比Low模式高2-3倍
- 响应时间:Low模式响应速度比High模式快30-50%
- 适用模型:所有GPT-5版本都支持verbosity控制
- 成本优化:结合不同GPT-5版本可实现最佳性价比
与推理effort协同:
resp = client.responses.create(
model="gpt-5",
input="设计一个微服务架构的用户认证系统",
reasoning={"effort": "high"},
text={"verbosity": "high"}
)
增强透明度:Preambles前言
Preambles(前言功能)是GPT-5在提升用户体验和AI透明度方面的创新设计。当模型决定调用工具时,会先生成简洁的解释性文本,向用户说明即将执行的操作和原因,然后再进行实际的工具调用。这一功能显著提升了AI应用的可理解性、可信度和调试友好性。
Preambles的核心价值:
- 操作透明性:用户清楚了解AI的决策过程和即将执行的操作
- 增强信任:通过解释性文本建立用户对AI系统的信心
- 改善调试:开发者能够更容易理解和优化工具调用逻辑
- 用户教育:帮助用户理解AI的工作方式,促进人机协作
resp = client.responses.create(
model="gpt-5",
input="我需要查询当前的天气情况和股价信息",
instructions="在调用任何工具之前,先解释调用目的和预期结果。",
tools=[
{
"type": "function",
"name": "get_weather",
"description": "获取指定地点的天气信息",
"parameters": {
"type": "object",
"properties": {"location": {"type": "string"}},
"required": ["location"]
}
},
{
"type": "function",
"name": "get_stock_price",
"description": "获取股票价格信息",
"parameters": {
"type": "object",
"properties": {"symbol": {"type": "string"}},
"required": ["symbol"]
}
}
]
)
Custom Tools:自由文本工具调用
突破传统 JSON Schema 限制,模型可将原始文本负载(代码/SQL/配置)直接发送至自定义工具,减少转义错误。
from openai import OpenAI
client = OpenAI()
resp = client.responses.create(
model="gpt-5",
input="使用 code_exec 工具计算斐波那契前10项",
tools=[
{"type": "custom", "name": "code_exec", "description": "执行任意Python代码"}
]
)
# 服务器侧收到自定义工具调用后,将 resp 中的原始代码文本安全执行并回传结果
精确输出控制:Context-Free Grammar (CFG)
为需要严格格式的输出(如 SQL、时间戳、配置、DSL)定义语法规则,确保结果可直接解析。
from openai import OpenAI
client = OpenAI()
regex_ts = r"^(?P<year>\\d{4})-(?P<month>0[1-9]|1[0-2])-(?P<day>0[1-9]|[12]\\d|3[01])T(?P<hour>[01]\\d|2[0-3]):(?P<minute>[0-5]\\d):(?P<sec>[0-5]\\d)Z$"
resp = client.responses.create(
model="gpt-5",
input="输出当前 UTC 时间戳(ISO8601,Z 结尾)",
tools=[{
"type": "custom",
"name": "emit_timestamp",
"description": "返回ISO8601时间戳",
"format": {"type": "grammar", "syntax": "regex", "definition": regex_ts}
}]
)
工具权限管理:Allowed Tools
通过 tool_choice.allowed_tools 在会话内收敛工具权限,安全且有利于缓存。
resp = client.responses.create(
model="gpt-5",
input="给产品团队发送明日降雨提醒",
tools=[
{"type": "function", "name": "get_weather", "parameters": {"type": "object", "properties": {"location": {"type": "string"}}}},
{"type": "function", "name": "send_email", "parameters": {"type": "object", "properties": {"to": {"type": "string"}, "content": {"type": "string"}}}}
],
tool_choice={
"type": "allowed_tools",
"mode": "auto",
"tools": [
{"type": "function", "name": "get_weather"},
{"type": "function", "name": "send_email"}
]
}
)
GPT-5 API全面迁移指南:Chat Completions vs Responses API
API 对照表
| Chat Completions | Responses API | 说明 |
|---|---|---|
messages | input + instructions | 系统提示独立为 instructions |
functions | tools | 类型显式(function/custom/mcp) |
function_call | tool_choice | 支持白名单与必选模式 |
| — | reasoning | 控制推理强度 |
| — | text.verbosity | 控制详略 |
| — | previous_response_id | 传递推理链/上下文 |
迁移重点:升级模型 + 逐步切换到 Responses API,以获得更好的缓存命中与工具编排体验。
核心差异表
| 特性对比 | Chat Completions API | Responses API |
|---|---|---|
| 推理链传递 | 不支持 | 支持 previous_response_id |
| 缓存效率 | 标准 | 更高命中率与更低延迟 |
| 推理 Tokens | 无专门控制 | reasoning.effort 控制深度 |
| 输出详略 | 提示词约定 | text.verbosity 参数化 |
| 工具机制 | functions | tools + tool_choice.allowed_tools |
迁移示例
保持 Chat Completions,先换模型名
response = client.chat.completions.create(
model="gpt-5",
messages=[
{"role": "user", "content": "分析这段代码的性能问题"}
],
reasoning_effort="medium",
verbosity="medium"
)
完整迁移到 Responses API
from openai import OpenAI
client = OpenAI()
messages = [
{"role": "system", "content": "你是一位专业的代码分析师"},
{"role": "user", "content": "请分析这段Python代码的时间复杂度"},
{"role": "assistant", "content": "我将分析代码的算法复杂度..."},
{"role": "user", "content": "能否提供优化建议?"}
]
# 提取系统消息与用户输入,合并为 Responses API 形态
system_prompt = messages[0]["content"]
user_turns = [m for m in messages[1:] if m["role"] in ("user", "assistant")]
resp = client.responses.create(
model="gpt-5",
input=user_turns, # 多轮对话直接作为 input
instructions=system_prompt, # 系统角色作为 instructions
reasoning={"effort": "medium"},
text={"verbosity": "medium"}
)
工具调用迁移
responses_call = client.responses.create(
model="gpt-5",
input="查询今天的天气",
tools=[
{
"type": "function",
"name": "get_weather",
"parameters": {
"type": "object",
"properties": {"location": {"type": "string"}},
"required": ["location"]
}
},
{"type": "custom", "name": "weather_script", "description": "执行天气查询脚本"}
],
tool_choice={
"type": "allowed_tools",
"mode": "auto",
"tools": [{"type": "function", "name": "get_weather"}]
}
)
GPT-5定价策略与成本优化指南:缓存、批量处理与90%折扣
GPT-5系列定价对比
GPT-5的定价策略相当有竞争力。GPT-5标准版输入token价格$1.25/百万,比GPT-4的$2.00便宜了37.5 %。性能提升这么多,价格反而下降,这点很不错。输出token $10/百万和之前一样,但质量提升明显,性价比还是更好了。
GPT-5 Mini的$0.25/$2定价(输入/输出每百万token)在中端市场很有吸引力。和Claude Opus 4.1的$15/$75高价比起来,GPT-5 Mini的成本优势相当明显,而且在大部分任务上能提供相近的性能。
GPT-5 Nano的$0.05/$0.4价格真的很亲民,对高性能AI模型来说这个定价相当有竞争力。这让大规模AI应用成为可能,特别对初创公司和个人开发者来说,进入AI领域的门槛降低了很多。
缓存输入的90 %折扣是个很实惠的功能。对于经常用同样上下文的应用(比如客服机器人、文档分析工具),这个折扣能显著降低成本。标准版的缓存输入只要$0.125/百万token,Mini版更是低到$0.025/百万token。
推理token定价机制
推理token的计费方式需要留意一下。当模型用thinking模式深度思考时,会产生额外的推理token费用。这些token按输入token价格计费,但能带来输出质量和准确性的明显提升。
推理成本控制策略:
- 简单任务使用minimal推理级别
- 复杂任务才启用high推理级别
- 通过A/B测试找到最优的推理级别配置
- 监控推理token使用量,避免成本超预算
实际测试显示,在大多数场景中,中等推理级别(medium)能够在成本和质量间取得最佳平衡。高推理级别主要适用于数学证明、复杂逻辑分析等对准确性要求极高的任务。
模型选择策略
不同场景下的最优选择建议:
企业级应用场景:
- 客服系统:GPT-5 Mini(成本效益最佳)
- 代码审查:GPT-5标准版(质量要求高)
- 文档处理:GPT-5 Nano(批量处理优势)
- 决策支持:GPT-5标准版(准确性关键)
开发和原型验证:
- 功能验证:GPT-5 Nano(快速迭代)
- 性能测试:GPT-5 Mini(平衡性能与成本)
- 生产部署:根据具体需求选择合适版本
成本优化技巧:
- 合理使用缓存:重复内容使用缓存输入节省90 %成本
- 批量处理:使用Batch API获得50 %折扣
- 模型组合:简单任务用Nano,复杂任务用标准版
- 推理级别控制:根据任务复杂度调整reasoning_effort参数
ROI计算公式:
月度成本节省 = (旧方案成本 - GPT-5成本) × 月处理量
效率提升价值 = 人工成本 × 效率提升比例 × 工作时长
总投资回报 = 成本节省 + 效率提升价值 - 集成开发成本
GPT-5企业级应用案例分析:医疗、编程、教育领域实战
利用GPT-5新功能的创新应用
复杂推理任务在GPT-5的thinking模式下表现相当出色。做复杂数学证明时,模型能进行多步逻辑推导,处理抽象概念之间的复杂关系。某在线教育平台用GPT-5做了个数学辅导系统,在AIME竞赛题上达到94.6 %正确率,学生满意度比传统系统高了45 %。
Agent应用借助MCP协议有了质的飞跃。一家金融科技公司用 GPT-5 做了个智能投资顾问,能实时拉取市场数据、分析财经新闻、跑投资组合分析,然后给出个性化投资建议。
这系统每天处理用户 3 万次咨询,准确率达 87%,给公司节省了 60% 的人工成本。
大项目代码分析得益于400 K上下文窗口。某互联网公司用GPT-5分析一个50万行代码的老系统,模型能找出架构问题、安全漏洞和性能瓶颈,给出的重构建议让开发团队把系统性能提升了30 %,开发效率提高了25 %。
GPT-5独有优势场景
医疗辅助诊断领域,GPT-5的1.6 %低错误率表现相当不错。某三甲医院试用GPT-5辅助诊断系统,处理疑难病例时,模型能:
- 主动标记潜在的严重疾病信号
- 提出针对性的补充检查建议
- 根据患者情况调整诊疗方案
- 提供多种可能诊断路径分析
临床测试结果显示,辅助系统让漏诊率降低 23%,诊断效率提升 35%。需要说明的是,这个系统只是辅助工具,最终诊断还是要医生来确认。
学术研究加速方面,GPT-5的深度推理能力为研究人员提供了强大支持。某顶尖大学的物理系使用GPT-5协助理论物理研究,模型能够:
- 推导复杂的数学公式
- 分析实验数据的统计意义
- 提出新的理论假设
- 生成规范的学术论文草稿
研究团队反馈,使用GPT-5后论文产出速度提升了40 %,同时保持了高水准的学术质量。
企业级软件开发中,GPT-5在SWE-bench基准上74.9 %的成绩转化为实际生产力提升。某大型软件公司使用GPT-5构建的代码生成系统,能够:
- 根据需求文档自动生成基础代码框架
- 进行实时代码审查和优化建议
- 自动生成单元测试和文档
- 识别和修复常见的安全漏洞
试点项目显示,开发效率提升了29 %,代码质量评分提高了15 %,bug数量减少了18 %。
竞争对手实际效果对比
与Claude-4的对比测试中,GPT-5在多个关键指标上表现更优:
| 测试场景 | GPT-5 | Claude-4 | 优势 |
|---|---|---|---|
| 复杂编程任务 | 74.9 % | 68.2 % | +6.7 % |
| 数学推理 | 94.6 % | 83.1 % | +11.5 % |
| 多语言理解 | 88 % | 82 % | +6 % |
| 事实准确性 | 92.3 % | 89.7 % | +2.6 % |
与Gemini 2.5的实际应用对比显示,GPT-5在处理长文档、复杂推理任务时具有明显优势,特别是在需要多步骤分析的场景中表现突出。用户反馈显示,GPT-5的回答更加准确、逻辑更加清晰、实用性更强。
开发者社区反馈汇总:
- 84 %的开发者认为GPT-5在编程辅助方面优于竞争对手
- 78 %的用户表示GPT-5的推理能力明显更强
- 91 %的企业用户对GPT-5的性价比表示满意
- 主要改进领域:长上下文处理、数学计算、代码生成
GPT-5社区评价与专家分析:Hacker News、GitHub、产品专家观点
技术社区评价
Hacker News开发者反馈整体积极,重点集中在GPT-5的编程能力提升上。用户@tech_lead_2024分享道:"GPT-5在处理复杂的系统架构设计时表现出色,能够考虑到性能、可扩展性和安全性的多重要求,生成的方案往往比初级开发者更加全面。"
GitHub Copilot集成体验得到广泛好评。GitHub官方数据显示,集成GPT-5后的Copilot在代码补全准确率上提升了18 %,用户接受建议的比例从65 %提升至79 %。开发者特别赞赏GPT-5在处理大型代码库时的上下文理解能力。
早期用户使用心得反映出一些关键优势:
- 上下文理解更准确:能够更好地理解长对话历史和复杂项目背景
- 推理逻辑更清晰:在解决复杂问题时能够展现清晰的思维路径
- 多语言能力更强:在非英语语言的处理上有显著改善
- 错误率明显降低:特别是在技术文档和代码生成方面
行业专家分析
Gary Marcus的批判性观点为GPT-5的评价提供了另一个角度。这位AI研究领域的知名专家在其GPT-5热点评论中指出:"GPT-5确实在基准测试中表现出色,但我们需要谨慎评估其在真实世界任务中的表现。基准测试的优异成绩不能完全代表实际应用能力。"
Marcus同时认可了GPT-5在某些方面的进步:"推理token机制是一个有趣的创新,但我们需要更多长期研究来验证其在复杂认知任务中的可靠性。"他的观点提醒我们,在拥抱新技术的同时也要保持理性思考。
产品专家 Claire Vo 的深度分析来自 Lenny's Newsletter 的独家报道。作为 ChatPRD 的创始人,她从产品角度评价 GPT-5:"在实际的产品需求分析和用户故事编写中,GPT-5 展现了更强的业务理解能力。模型能够更好地把握用户需求的细节,生成的 PRD 文档结构更合理、内容更完整。"
Charlie Labs的技术评估显示,GPT-5在处理真实GitHub问题时全面超越了Claude Code。在10个真实开源项目的问题解决测试中,GPT-5的平均成功率达到78 %,而Claude Code仅为62 %。详细的Charlie Labs GPT-5研究报告提供了完整的测试方法和结果分析,这一结果在开发者社区引起了广泛关注。
与竞争对手对比
与Claude-4的优势劣势分析:
GPT-5的优势:
- 数学和科学推理能力更强
- 编程任务完成质量更高
- 多模态理解能力更出色
- API集成更加便捷
Claude-4的相对优势:
- 在某些文学创作任务中表现更好
- 对话风格更加自然流畅
- 在伦理判断方面更加保守
与Gemini 2.5的性能对比显示,GPT-5在大多数技术任务中具有优势,特别是在需要复杂推理的场景中。但Gemini在多语言处理的某些特定场景下仍有竞争力。
在AI市场中的定位逐渐清晰:GPT-5正成为技术密集型应用的首选,特别是在需要高准确性、复杂推理和深度分析的场景中。其相对亲民的定价策略也使其在中小企业市场获得了更多关注。
用户忠诚度调研显示:
- 72 %的GPT-4用户计划升级到GPT-5
- 58 %的Claude用户考虑尝试GPT-5
- 企业用户的迁移意愿达到83 %
- 价格敏感型用户对GPT-5 Nano兴趣更高
GPT-5迁移指南与开发最佳实践:API集成与成本控制
从GPT-4迁移到GPT-5
API兼容性方面,GPT-5保持了与GPT-4的良好兼容性,现有的应用代码只需要最小的修改即可升级。主要的变更包括模型名称的更新和新参数的可选使用。
基本迁移步骤:
- 更新模型名称
# 从
# model="gpt-4"
# 更改为
model = "gpt-5" # 或 "gpt-5-mini", "gpt-5-nano"
- 可选:启用新功能
response = client.chat.completions.create(
model="gpt-5",
messages=messages,
reasoning_effort="medium",
verbosity="medium",
allow_thinking=True
)
- 成本优化配置
response = client.chat.completions.create(
model="gpt-5-mini",
messages=[
{"role": "system", "content": cached_system_prompt},
{"role": "user", "content": user_input}
]
)
新参数的建议:
- reasoning_effort: 简单任务用"minimal",复杂任务用"high"
- verbosity: 客服场景用"medium",技术文档用"high"
- 工具使用: 优先使用内置工具;高风险操作与白名单搭配
性能提升的量化预期:
- 响应准确性提升15-25 %
- 编程任务完成质量提升29 %
- 数学推理准确性提升20-40 %
- 多语言处理质量提升10-15 %
使用最佳实践
推理token使用策略:
- 高价值任务:
effort=high - 常规任务:
effort=medium - 成本敏感流水线:
effort=minimal
不同变体选择:
def choose_gpt5_variant(task_complexity, budget_priority, response_time_requirement):
if task_complexity == "high" and budget_priority == "low":
return "gpt-5"
if task_complexity == "medium" and budget_priority == "medium":
return "gpt-5-mini"
if response_time_requirement == "fast" or budget_priority == "high":
return "gpt-5-nano"
return "gpt-5-mini"
成本控制技巧:
- 固定 System Prompt 与模板化上下文,充分利用缓存折扣。
- 批量任务使用 Batch/队列合并,低峰执行重活。
- 动态路由:按任务难度自动切换模型与参数。
- 监控 usage:关注 input/output/reasoning/cached tokens 与平均成本。
避免常见问题
- 过度使用高推理级别:简单任务不必
high。 - 忽视缓存:固定前缀未模块化,浪费折扣。
- 模型选型不匹配:用标准版跑简单流水线或反之。
- 超时与重试未配置:长推理需要更合理的超时与退避策略。
常见问题解答(FAQ)
OpenAI GPT-5和GPT-4相比有哪些重大改进?
四个方向:
- 上下文窗口:128K → 400K。
- 推理Token机制:多步思考提升复杂任务稳定性。
- 数学推理:AIME 等基准显著提升。
- 成本优化:输入Token价格下降($1.25 vs $2.00)。
如何选择最适合的GPT-5版本:标准版、Mini版还是Nano版?
- GPT-5 标准版($1.25/$10):复杂推理、高级编程、科研与决策。
- GPT-5 Mini($0.25/$2):客服、内容、教育、中等复杂度分析。
- GPT-5 Nano($0.05/$0.4):分类/审核/批处理与高频 API。
GPT-5的推理Token机制是什么?如何有效控制成本?
推理Token在深度思考时产生,按输入价计费。用 reasoning.effort 控制:minimal/low/medium/high。简单任务低强度,复杂任务高强度。
GPT-5在软件开发和编程辅助方面有哪些突出优势?
- SWE-bench Verified 74.9%
- 400K 上下文支持大仓分析
- thinking 推理模式带来更高命中率与更稳健的重构建议
- 多语言编程覆盖度更广
GPT-5缓存输入机制如何实现显著成本节省?
相同/相似的系统提示与模板化上下文命中缓存,价格降至原价的约十分之一(以实际账单为准)。
GPT-5支持哪些智能工具集成和外部服务连接?
内置 Web 搜索、文件分析、Python 解释器;支持 MCP 与自定义工具;CFG 支持结构化输出。