
AI 开发者在使用 ChatGPT API 时最大的痛点是什么?
当你满心期待地调用 API 获取结构化数据时,经常遇到 JSON 格式混乱、字段缺失、数据类型错误等问题,严重影响生产环境的稳定性。
ChatGPT API 结构化输出(Structured Outputs) 技术的推出,彻底改变了这一现状。
这项创新功能通过实时 JSON Schema 验证,确保 100% 的数据格式准确率——从此告别「大概正确」,迎来「绝对可靠」的 AI 数据交互时代。
本文将为你提供 ChatGPT API 结构化输出的完整实现指南,涵盖核心技术原理、Python/JavaScript 代码实战、生产环境部署最佳实践,以及常见问题的解决方案。
如果你是 ChatGPT API 新手,建议先阅读 ChatGPT API 核心概念完整指南 建立基础认知。
无论你是 AI 应用开发工程师、后端架构师,还是技术团队管理者,都能从这份专业指南中获得实用价值。
快速开始:5 分钟实现 ChatGPT 结构化输出
想要快速体验 ChatGPT API 结构化输出的强大能力?以下是最简单的实现步骤:
第一步:安装必要依赖
pip install openai pydantic # Python 方案
npm install openai zod # JavaScript 方案
第二步:定义数据结构
from pydantic import BaseModel
class UserProfile(BaseModel):
name: str
age: int
skills: list[str]
第三步:调用API
response = client.chat.completions.parse(
model="gpt-4o-2024-08-06",
messages=[{"role": "user", "content": "分析这个用户:张三,25岁,Python 开发工程师"}],
response_format=UserProfile
)
# 获得 100% 可靠的结构化数据
user_data = response.choices[0].message.parsed
这就是 ChatGPT 结构化输出的核心优势:零错误的数据格式保证。
ChatGPT API 结构化输出技术原理深度解析
OpenAI 结构化输出的核心技术机制
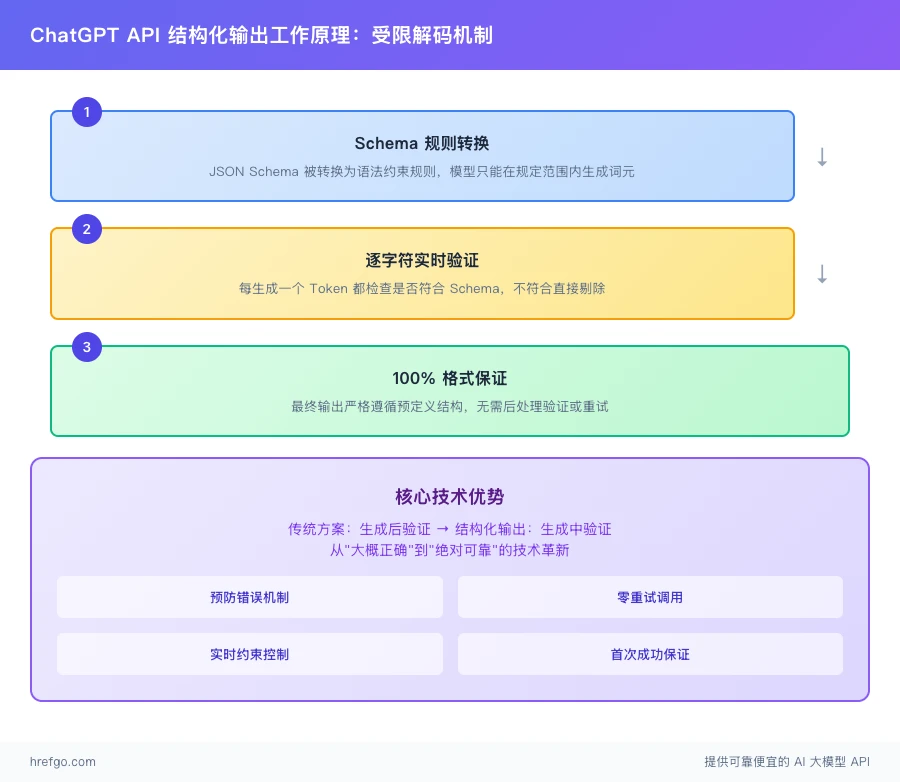
ChatGPT API 结构化输出采用 受限解码(Constrained Decoding) 技术,这是 OpenAI 在 AI 输出控制领域的重大突破。
该技术彻底改变了传统的「生成后验证」模式,实现了「生成中验证」的实时约束机制,确保每个生成步骤都严格遵循 JSON Schema 规范。
具体是这样工作的:
实时验证:模型每生成一个词元(token),都会检查这个词元是否会破坏 JSON Schema 的规则。
如果会导致格式错误,这个词元就被直接剔除,保证生成的内容始终在正确的轨道上。
语法约束:系统会把 JSON Schema 转换成语法规则,模型只能在这些规则允许的范围内生成内容。
就像给模型戴了个「紧箍咒」,让它只能说「正确的话」。
逐字验证:不是等整段内容生成完再检查,而是每个字符都要过关。
这种严格控制是实现 100% 准确率的关键所在。
结构化输出与传统 JSON Mode 的关键区别
要理解结构化输出的价值,得先搞清楚它和 JSON Mode 的区别:
| 特性对比 | 结构化输出 | JSON Mode | 无约束生成 |
|---|---|---|---|
| 验证时机 | 生成时验证 | 后处理验证 | 无验证 |
| Schema 遵循率 | 100% | ~85-90% | <40% |
| 错误处理 | 预防机制 | 重试机制 | 需要复杂处理 |
| 性能特点 | 单次成功 | 可能需要多次调用 | 需要验证和重试 |
| 首次延迟 | <10 秒(复杂 schema 可能至 1 分钟) | 无额外延迟 | 无额外延迟 |
| 后续请求 | 无额外延迟 | 无额外延迟 | 无额外延迟 |
两者的本质差别:
-
JSON Mode:让模型先「随意发挥」生成内容,然后试着解析成 JSON。 如果格式不对,就得重新来一遍,有时候要试好几次才能成功。
-
结构化输出:从第一个字符开始就按规矩来,每一步都确保不会出错。 就像有个严格的老师在旁边盯着,不给犯错的机会。

ChatGPT API 结构化输出支持模型列表
结构化输出不是所有模型都支持的,需要选对模型:
支持的模型:
gpt-4o-2024-08-06及更新版本gpt-4o-mini和gpt-4o-mini-2024-07-18- 后续的所有
gpt-4o系列 - 老版本的
gpt-4-turbo和gpt-3.5-turbo都不支持
想了解最新的 GPT-5 完整指南 及其结构化输出能力,可以看看那篇详细分析。
为什么有版本限制:新模型在底层架构上做了升级,能在推理时实时应用 JSON Schema 规则。
老模型没这个能力,只能先生成再验证,准确率自然差很多。
实际选择建议:生产环境里用支持结构化输出的新模型,API 调用成功率能大幅提升,也不用写那么多错误处理代码了。
JSON Schema 在 ChatGPT API 结构化输出中的应用
理解 JSON Schema:结构化输出的数据规范基础
在 ChatGPT API 结构化输出中,JSON Schema 是数据格式约束的核心标准。
掌握 JSON Schema 设计原则,是充分利用结构化输出功能的关键前提。
JSON Schema 的三个关键作用:
- 定规矩:提前告诉 API 要返回什么字段、什么类型、怎么嵌套
- 实时监督:生成过程中每个词元都要符合这些规矩
- 保证结果:确保最终得到的数据格式和预期完全一致
支持的数据类型:
常用类型:
string- 文本,可以加格式限制(邮箱、日期、UUID等)number- 数字,可以设置最大最小值integer- 整数,带数值限制boolean- 真假值array- 数组,可以控制元素个数和类型object- 对象(最多嵌套10层)enum- 枚举,从几个固定选项中选一个(最多1000个)anyOf- 多选一的联合类型
高级功能:
{
"type": "object",
"properties": {
"name": {
"type": "string",
"pattern": "^[A-Za-z\\s]+$"
},
"email": {
"type": "string",
"format": "email"
},
"age": {
"type": "integer",
"minimum": 0,
"maximum": 150
},
"tags": {
"type": "array",
"items": {"type": "string"},
"minItems": 1,
"maxItems": 10
},
"status": {
"type": "string",
"enum": ["active", "inactive", "pending"]
},
"metadata": {
"anyOf": [
{"type": "string"},
{"type": "null"}
]
}
},
"additionalProperties": false,
"required": ["name", "email", "age"]
}
ChatGPT API的特色支持:
- 对象和数组可以多层嵌套
- 枚举类型功能完整
- 字符串可以验证格式(邮箱、时间等)
- 数字可以设置范围和模式
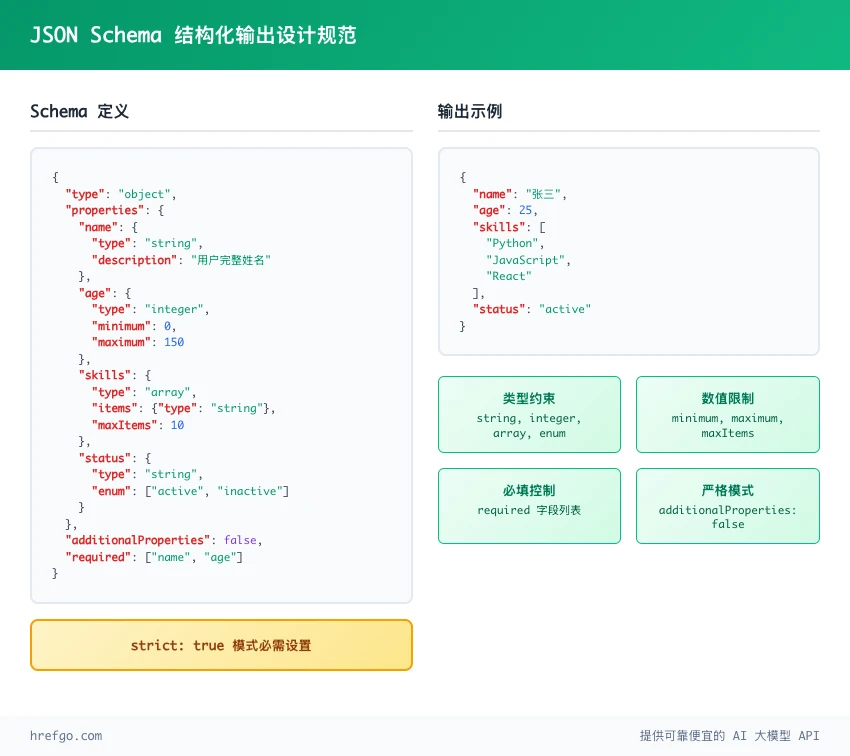
ChatGPT API Strict 模式:确保 100% 格式准确的技术规范
ChatGPT API的Strict模式是实现结构化输出100%准确率的核心机制。该模式通过严格的JSON Schema验证规则,确保AI生成的数据完全符合预定义格式要求。
additionalProperties: false 的必要性:
{
"type": "object",
"properties": {
"title": {"type": "string"},
"content": {"type": "string"}
},
"additionalProperties": false,
"required": ["title", "content"]
}
使用限制:
数量方面:
- 对象属性总数不能超过5000个
- 嵌套深度最多10层
- 枚举选项最多1000个
- 所有字符串长度加起来不能超过120,000字符
必须遵守的规则:
- 必须设置
additionalProperties: false- 不允许额外字段 - 所有字段都要标记为
required - 根对象必须是
object类型,不能用anyOf
不支持的功能:
- 复杂组合:
allOf、not、dependentRequired - 条件判断:
if、then、else - 微调模型还不支持:
minLength、maxLength、pattern、format
这些限制的目的:
- 划清界限:告诉模型只能生成定义好的字段,不能随意添加
- 杜绝胡编乱造:防止模型自己发明一些字段出来
- 提升效率:选择范围小了,生成速度和准确性都会提升
实现可选字段的技巧: 虽然所有字段都要标记为required,但可以用联合类型来实现"可选"效果:
{
"type": "object",
"properties": {
"required_field": {
"type": "string",
"description": "必选字段"
},
"optional_field": {
"anyOf": [
{"type": "string"},
{"type": "null"}
],
"description": "可选字段,使用anyOf实现"
},
"optional_with_default": {
"type": ["string", "null"],
"description": "可选字段,简化语法"
}
},
"additionalProperties": false,
"required": ["required_field", "optional_field", "optional_with_default"]
}
递归和定义支持:
支持使用 $defs 和 $ref 实现递归结构和代码复用:
{
"type": "object",
"properties": {
"tree": {"$ref": "#/$defs/node"}
},
"$defs": {
"node": {
"type": "object",
"properties": {
"value": {"type": "string"},
"children": {
"type": "array",
"items": {"$ref": "#/$defs/node"}
}
},
"additionalProperties": false,
"required": ["value", "children"]
}
},
"additionalProperties": false,
"required": ["tree"]
}
结构化输出 JSON Schema 设计最佳实践
字段命名和描述要清楚:
{
"user_profile": {
"type": "object",
"properties": {
"full_name": {
"type": "string",
"description": "用户的完整姓名"
},
"registration_date": {
"type": "string",
"format": "date-time",
"description": "用户注册的ISO时间戳"
}
}
}
}
嵌套结构设计建议:
- 控制深度:最好不要超过5层嵌套,太深了容易出问题
- 合理分组:把相关的字段放一起,这样schema看起来更清晰
- 数组统一:数组里的元素最好都是同一种结构
善用枚举类型: 当字段只有几个固定选项时,用enum能大幅提升数据质量:
{
"priority": {
"type": "string",
"enum": ["low", "medium", "high", "urgent"],
"description": "任务优先级"
}
}
ChatGPT API 结构化输出实现方案:Python 与 JavaScript 完整教程
Python Pydantic 集成:ChatGPT 结构化输出的类型安全实现
Pydantic在ChatGPT API结构化输出中的优势: Pydantic是Python生态系统中与ChatGPT API结构化输出完美契合的数据验证库。通过定义Pydantic数据模型,可以自动生成符合OpenAI标准的JSON Schema,并提供完整的类型安全保障。
最新API使用方式:
from openai import OpenAI
from pydantic import BaseModel
class TaskAnalysis(BaseModel):
priority: str
estimated_hours: int
required_skills: list[str]
client = OpenAI()
# 使用最新的chat.completions.parse方法
response = client.chat.completions.parse(
model="gpt-4o-2024-08-06",
messages=[
{"role": "system", "content": "分析给定任务的复杂度和需求"},
{"role": "user", "content": "开发一个用户认证系统"}
],
response_format=TaskAnalysis,
)
# 类型安全的访问方式
task_data = response.choices[0].message.parsed
# 或者使用传统的response_format方式
response = client.chat.completions.create(
model="gpt-4o-2024-08-06",
messages=[
{"role": "system", "content": "分析给定任务的复杂度和需求"},
{"role": "user", "content": "开发一个用户认证系统"}
],
response_format={
"type": "json_schema",
"json_schema": {
"name": "task_analysis",
"strict": True,
"schema": TaskAnalysis.model_json_schema()
}
}
)
几个关键特点:
- 自动转换:Pydantic会把Python的类型注解自动转成JSON Schema
- 类型安全:通过
.parsed属性能得到有类型保证的Python对象 - 错误友好:出错时Pydantic会给出详细的错误信息

JavaScript Zod 集成:TypeScript 友好的结构化输出实现
Zod在ChatGPT结构化输出中的应用价值: Zod作为TypeScript原生的运行时验证库,为JavaScript开发者提供了与ChatGPT API结构化输出无缝集成的解决方案,确保前端应用的数据类型安全。
JavaScript + Zod最新实现示例:
import { z } from "zod";
import { zodResponseFormat } from "openai/helpers/zod";
import OpenAI from "openai";
const TaskAnalysisSchema = z.object({
priority: z.string(),
estimated_hours: z.number(),
required_skills: z.array(z.string()),
});
const client = new OpenAI();
// 使用Zod辅助函数的推荐方式
const completion = await client.chat.completions.create({
model: "gpt-4o-2024-08-06",
messages: [
{ role: "system", content: "分析给定任务的复杂度和需求" },
{ role: "user", content: "开发一个用户认证系统" }
],
response_format: zodResponseFormat(TaskAnalysisSchema, "task_analysis"),
});
// 解析和验证响应
const taskData = TaskAnalysisSchema.parse(
JSON.parse(completion.choices[0].message.content)
);
// 或者使用原生JSON Schema格式
const completion2 = await client.chat.completions.create({
model: "gpt-4o-2024-08-06",
messages: [
{ role: "system", content: "分析给定任务的复杂度和需求" },
{ role: "user", content: "开发一个用户认证系统" }
],
response_format: {
type: "json_schema",
json_schema: {
name: "task_analysis",
strict: true,
schema: {
type: "object",
properties: {
priority: { type: "string" },
estimated_hours: { type: "number" },
required_skills: {
type: "array",
items: { type: "string" }
}
},
required: ["priority", "estimated_hours", "required_skills"],
additionalProperties: false
}
}
}
});
两种方案的特点对比:
- Python方案:模型定义简洁,类型系统天然支持
- JavaScript方案:运行时验证类型,和TypeScript项目结合很好
ChatGPT 结构化输出错误处理与生产环境调试指南
处理模型拒绝的情况: 有时候模型会因为安全原因拒绝请求,这时候需要检查refusal字段:
if response.choices[0].message.refusal:
print(f"模型拒绝请求:{response.choices[0].message.refusal}")
# 实施fallback逻辑
else:
parsed_data = response.choices[0].message.parsed
# 正常处理数据
常见错误和解决办法:
Schema相关错误:
Maximum schema size exceeded:schema太大了,需要简化结构- 字段缺失:检查required字段是否都定义了,可选字段用联合类型
- 类型不匹配:看看期望的类型和实际生成的是否一致
- 枚举值问题:确认枚举选项是否完整正确
解析和模型错误:
openai.LengthFinishReasonError:token不够用了,增加max_tokens或简化输出- 模型差异:
gpt-4o-mini处理复杂schema时比gpt-4o容易出错 - 环境问题:本地能跑但部署时出错,检查环境变量和API版本
调试技巧:
- 换个模型试试:问题解决不了时从
gpt-4o-mini换到gpt-4o - 在线验证schema:用在线工具检查JSON Schema格式是否正确
- 注意响应格式:用
response_format时不用手动解析JSON - 关注token使用:复杂schema特别容易撞上token限制
生产环境监控要点:
- 成功率监控:结构化输出的解析成功率,目标是100%
- 错误模式分析:记录schema相关错误,找出规律
- 响应时间跟踪:新schema首次使用会有5-10秒延迟,这是正常的
- 设置报警:schema遵循率低于95%时要及时发现
ChatGPT 结构化输出高级应用场景与系统架构设计
结构化输出在多智能体 AI 系统中的架构应用
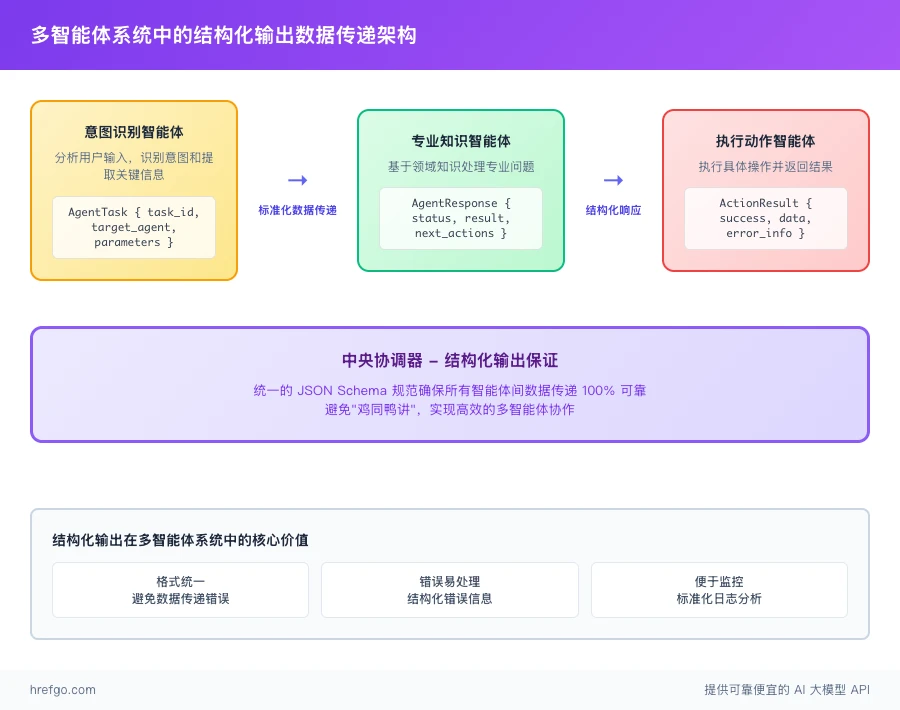
构建复杂AI系统时,让多个智能体互相"对话"往往是个头疼问题。ChatGPT结构化输出正好能解决这个痛点。
多智能体数据传递架构:
class AgentTask(BaseModel):
task_id: str
target_agent: str
parameters: dict
expected_output_schema: str
class AgentResponse(BaseModel):
task_id: str
status: str
result: dict
next_actions: list[AgentTask]
这样做的好处:
- 格式统一:所有智能体都用同样的数据格式,不会出现"鸡同鸭讲"
- 错误好处理:出错时信息结构化,更容易找问题和恢复
- 便于监控:数据格式标准化,监控和日志分析都更容易
实际案例:比如智能客服系统,意图识别智能体识别出用户需求后,用标准格式传给专业知识智能体,避免信息在传递过程中丢失或变形。
ChatGPT 函数调用结合结构化输出的工具集成方案
结构化输出在函数调用中特别有用,能确保传给工具的参数格式正确。想了解更多函数调用的高级用法,可以看看ChatGPT API 核心概念完整指南。
工具调用参数验证:
class DatabaseQuery(BaseModel):
table: str
conditions: dict
limit: int
# 在function calling中使用
tools = [
openai.pydantic_function_tool(
DatabaseQuery,
name="query_database",
description="查询数据库获取用户数据"
)
]
带来的价值:
- 参数不出错:避免因为参数类型不对导致工具调用失败
- API调用稳定:传给外部API的参数格式肯定正确
- 业务流程稳定:不会因为数据格式问题导致业务中断
ChatGPT 结构化输出生产环境部署与性能优化
性能优化建议:
- 预热schema:新schema首次使用需要5-10秒,复杂的可能要1分钟,但后续就没延迟了
- 选对模型:
gpt-4o处理结构化输出比gpt-4o-mini稳定,有问题可以升级试试 - 用批处理API:支持Batch API,非实时任务能便宜50%
- Token考虑:Schema定义不占用输入Token,但复杂schema会影响处理速度
- 准备备选方案:结构化输出不可用时,可以降级到JSON Mode或用Instructor库
综合监控和可观测性实现:
import logging
import time
import json
from typing import Dict, Any, Optional
from datetime import datetime
from openai import OpenAI
class StructuredOutputMonitor:
def __init__(self, client: OpenAI):
self.client = client
self.metrics = {
'total_requests': 0,
'successful_requests': 0,
'schema_errors': 0,
'model_refusals': 0,
'avg_response_time': 0
}
def call_with_monitoring(
self,
messages: list,
schema: Any,
model: str = "gpt-4o-2024-08-06",
max_retries: int = 3
) -> Optional[Any]:
start_time = time.time()
self.metrics['total_requests'] += 1
for attempt in range(max_retries):
try:
response = self.client.chat.completions.parse(
model=model,
messages=messages,
response_format=schema
)
# 检查是否被拒绝
if response.choices[0].message.refusal:
self.metrics['model_refusals'] += 1
logging.warning(f"模型拒绝: {response.choices[0].message.refusal}")
return None
# 记录成功指标
duration = time.time() - start_time
self.metrics['successful_requests'] += 1
self._update_avg_response_time(duration)
logging.info(f"结构化输出成功 - 耗时: {duration:.2f}s, 尝试: {attempt + 1}")
return response.choices[0].message.parsed
except Exception as e:
logging.error(f"第{attempt + 1}次尝试失败: {str(e)}")
if "schema" in str(e).lower():
self.metrics['schema_errors'] += 1
if attempt == max_retries - 1:
# 最后一次尝试失败,记录并抛出异常
logging.error(f"结构化输出完全失败: {str(e)}")
raise
time.sleep(2 ** attempt) # 指数退避
return None
def _update_avg_response_time(self, duration: float):
current_avg = self.metrics['avg_response_time']
success_count = self.metrics['successful_requests']
self.metrics['avg_response_time'] = (
current_avg * (success_count - 1) + duration
) / success_count
def get_metrics(self) -> Dict[str, Any]:
success_rate = (
self.metrics['successful_requests'] / self.metrics['total_requests'] * 100
if self.metrics['total_requests'] > 0 else 0
)
return {
**self.metrics,
'success_rate_percent': round(success_rate, 2)
}

生产环境最佳实践:
API配置:
- 版本选择:用
2024-08-01-preview或更新的版本 - 模型推荐:生产环境建议用
gpt-4o-2024-08-06,别用gpt-4o-mini - 安全管理:API密钥和配置要安全存储
想了解API成本详情,可以看看ChatGPT套餐和价格指南,里面有不同方案的经济性对比。
性能优化:
- 预热处理:应用启动时先加载常用schema,减少首次延迟
- 连接管理:合理设置并发数和超时时间
- 缓存策略:相同输入的结果可以用Redis缓存
错误处理:
- 智能重试:网络错误时用指数退避策略重试
- 降级机制:结构化输出失败时自动切换到JSON Mode
- 监控报警:错误率和响应时间要实时监控
安全考虑:
- 数据验证:即使有结构化输出,解析后的数据还是要验证
- 内容审核:用户输入可能触发模型拒绝,要有应对机制
- 信息保护:敏感信息不能出现在日志里
版本管理:
- Schema版本化:每个schema都要有版本管理和升级策略
- 灰度发布:新功能通过A/B测试逐步上线
- 回滚准备:随时能回退到稳定版本
ChatGPT API 结构化输出常见问题与解决方案
技术实现常见问题
Q:ChatGPT API结构化输出功能支持哪些AI模型版本?
A: 目前支持gpt-4o-2024-08-06及更新版本,还有gpt-4o-mini系列。这些模型底层支持约束生成,能在生成token时实时应用JSON Schema验证。
Q:OpenAI结构化输出与传统JSON Mode的核心技术差异是什么? A: 最大区别是验证时机。结构化输出边生成边验证,100%符合schema;JSON模式先生成再验证,可能要重试好几次。结构化输出更靠谱,更稳定。
Q:如何使用Python Pydantic库集成ChatGPT API结构化输出功能?
A: 写个继承BaseModel的Pydantic类,然后在API调用时把这个类传给response_format参数。SDK会自动生成schema和解析响应。
Q:ChatGPT API结构化输出的strict模式有什么技术要求?
A: Strict模式要求schema里必须设置additionalProperties: false,所有字段都标记为required。这样能确保模型只生成你定义的字段,不会画蛇添足。
应用场景与实践问题
Q:ChatGPT API结构化输出技术适用于哪些具体的开发场景? A: 主要用在需要可靠数据结构的地方:数据提取分类、动态生成UI、多智能体系统、API集成、数据库操作等。特别是生产环境中对数据一致性要求高的AI应用。
Q:在多智能体AI系统架构中如何有效应用结构化输出? A: 定义统一的通信协议schema,让智能体之间的数据传递格式保持一致。这样系统更容易监控,错误处理也更简单,智能体协作不会那么复杂。
Q:当ChatGPT模型因安全策略拒绝响应时,结构化输出如何处理?
A: 模型因为安全原因拒绝时,会返回refusal字段而不是结构化数据。程序要检查这个字段,然后做相应处理,比如用默认值或者提示用户改下请求。
性能优化与部署问题
Q:ChatGPT API结构化输出对系统性能和响应时间有何影响? A: 最新数据显示:新schema首次使用平均延迟5-10秒,复杂的可能要1分钟。但后续用同个schema就没延迟了。和JSON模式40%的准确率相比,结构化输出100%可靠,整体效率更高,不用重试。
Q:如何优化ChatGPT结构化输出的Token消耗和API成本? A: 简化schema设计,用清楚的字段名,别嵌套太深。合理用枚举类型能减少模型的选择范围,间接提升token使用效率。
Q:ChatGPT结构化输出在生产环境部署时需要注意哪些关键事项? A: 主要注意几点:提前预热常用schema减少首次延迟,建立完善的错误处理和监控,准备JSON Mode做降级方案,还有合适的缓存策略来优化性能。
ChatGPT 结构化输出框架集成与替代技术方案对比
主流 AI 框架的结构化输出集成方案
LangChain集成:
from langchain_openai import ChatOpenAI
from pydantic import BaseModel
class ResponseSchema(BaseModel):
answer: str
confidence: float
# 使用OpenAI结构化输出
model = ChatOpenAI(model="gpt-4o")
structured_llm = model.with_structured_output(
ResponseSchema,
method="json_schema", # 指定使用结构化输出API
strict=True
)
result = structured_llm.invoke("估算中国的人口数量")
Instructor库替代方案:
import instructor
from openai import OpenAI
client = instructor.from_openai(OpenAI())
response = client.chat.completions.create(
model="gpt-4o",
response_model=ResponseSchema,
messages=[
{"role": "user", "content": "估算中国的人口数量"}
]
)
结构化输出技术方案选择指南
| 特性 | OpenAI结构化输出 | Instructor库 | JSON Mode |
|---|---|---|---|
| 可靠性 | 100%遵循率 | ~95%遵循率 | ~40%遵循率 |
| 多提供商支持 | 仅OpenAI | 15+提供商 | 仅OpenAI |
| 复杂验证 | 基础验证 | 高级验证+重试 | 需自建 |
| 学习成本 | 低 | 中等 | 高 |
| 社区支持 | 官方支持 | 活跃社区 | 基础支持 |
选择建议:
- 只用OpenAI,场景简单:选OpenAI结构化输出
- 多个厂商或复杂验证:选Instructor库
- 老系统兼容:保留JSON Mode做降级
ChatGPT API 结构化输出技术总结与未来发展趋势
ChatGPT API 结构化输出技术作为 OpenAI 在 AI 数据可靠性领域的重大创新,为开发者提供了前所未有的数据格式保证能力。
综合分析这项技术的核心价值:
核心技术价值:
- 受限解码机制实现了 100% 的 schema 准确率,彻底解决 AI 输出格式混乱的问题
- 边生成边验证比传统的后处理验证更可靠、更高效
- 严格模式通过强制约束,生成高质量、可预测的结构化数据
实践应用价值:
- 双语言支持:Python 和 JavaScript 都有完整的集成方案,覆盖主流技术栈
- 系统架构价值:在多智能体系统中展现出色的数据传递能力
- 生产实战经验:从性能优化到错误处理的全套指导
未来发展方向:
在 AI 技术快速演进的背景下,ChatGPT API 结构化输出将与 OpenAI 生态系统实现更深层次的技术融合。
未来可期待:更复杂的 JSON Schema 支持、更高效的约束解码算法、与更多主流开发框架的原生集成,以及在企业级 AI 应用中的更广泛部署。
对于 AI 应用开发团队而言,掌握 ChatGPT API 结构化输出技术已成为构建可靠 AI 系统的核心竞争力。
无论是对现有 AI 产品进行数据可靠性升级,还是构建下一代智能应用架构,结构化输出技术都能提供显著的商业价值和技术优势。
立即开始在你的开发项目中集成 ChatGPT API 结构化输出功能,亲身体验这项实现 100% 数据格式准确率的革命性 AI 技术。
对于希望深入了解 ChatGPT 最新技术发展的开发者,推荐阅读 GPT-5 完整指南,获取 AI 模型演进的最前沿信息。