
全面解析主流 AI image generator 工具,助您精准选择最适合的 AI 图像生成方案
AI 图像生成模型(AI image model)能够通过文本描述自动创建高质量图像。 它运用深度学习和扩散模型等技术,将用户的语言文字转化为视觉作品,广泛应用于创意设计、内容营销、产品原型等领域。目前主流的 AI 图像生成工具包括 Stable Diffusion、Midjourney AI、Adobe Firefly、Leonardo AI、Gemini 2.5 Flash Image 等,每种工具都有其独特的技术特色和适用场景。
主流的 AI 图像生成模型对比:
| 工具名称 | 核心特色 | 主要优势 | 适用场景 |
|---|---|---|---|
| Stable Diffusion 3.5 | 开源领军者 | 完全免费,本地部署 | 个人创作,技术研发 |
| Adobe Firefly 4.0 | 专业创意集成 | 商业安全,工作流集成 | 商业设计,企业应用 |
| OpenAI DALL-E | 对话式生成 | GPT-4o 集成,智能交互 | 内容创作,教育培训 |
| Midjourney v7 | 艺术创作专家 | 最高艺术质量,美学表现 | 艺术创作,视觉设计 |
| Leonardo AI | 易用性典范 | 新手友好,界面简洁 | 快速原型,入门学习 |
| FLUX.1-Kontext | 技术创新者 | Flow-matching,编辑能力强 | 专业编辑,技术探索 |
| Google Imagen 4 | 高分辨率专家 | 2K 质量,92% 拼写准确率 | 高质量输出,文本渲染 |
| Gemini 2.5 Flash Image | 多模态编辑专家 | Nano Banana 技术,精确编辑 | 图像编辑,产品优化 |
| Ideogram 3.0 | 文本渲染专家 | 永久免费,文字生成优秀 | 标识设计,文字图像 |
AI 图像生成模型概述
技术发展历程
回望 AI 图像生成技术的发展历程,我们见证了一场从 GAN(生成对抗网络)到 Diffusion 模型的技术革命。虽然早期的 GAN 模型展现了生成图像的可能性,但总是受到训练不稳定、模式坍塌等技术障碍的困扰。直到 2021 年,基于 Diffusion Model 的 DALL-E 如一颗璀璨明珠般出现,为文本转图像技术带来了划时代的突破。同期,Google Research 在 Imagen 项目中展示了大规模语言模型在图像生成领域的巨大潜力。
紧接着,Stability AI 发布的 Stable Diffusion 开源项目如同打开了潘多拉魔盒,彻底重塑了整个行业的生态格局,让原本高不可攀的 AI 图像生成技术真正走进了千家万户。对于那些追求精细控制的专业用户,ComfyUI 界面更是提供了前所未有的强大操控体验。2022-2024 年间,Midjourney、Adobe Firefly、Leonardo AI 等商业化工具相继成熟,形成了当前多元化的技术生态。
最新的 Flow-matching 技术代表了下一代发展方向,FLUX 系列模型在这一领域取得了突破性进展,生成速度和质量都有显著提升。
市场发展现状
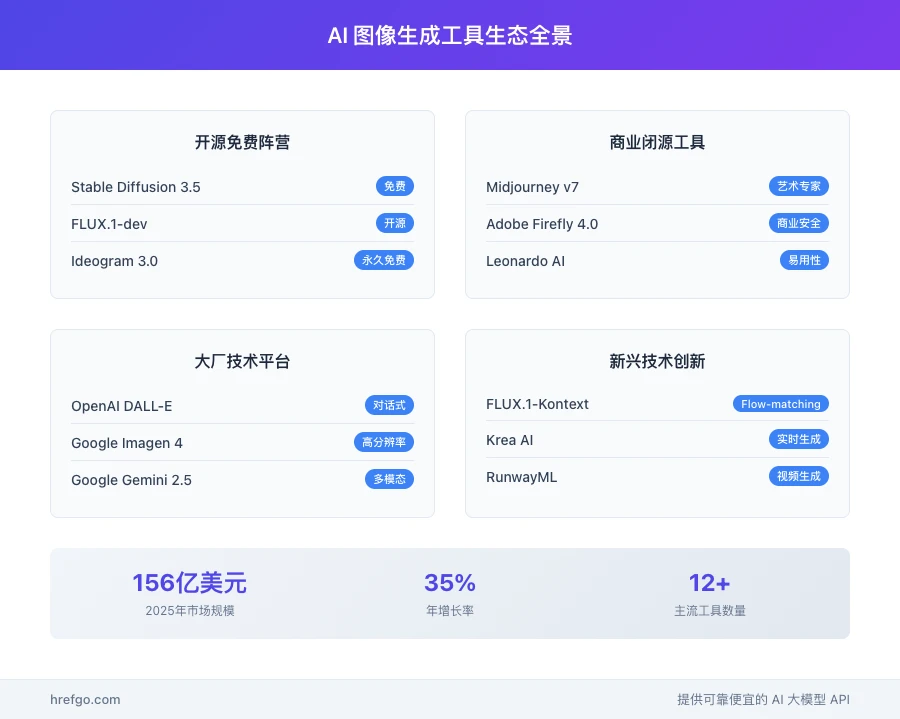
最新的市场调研数据显示了一个令人振奋的前景:全球 AI 图像生成工具市场正以惊人的速度增长,预计 2025 年市场规模将突破 156 亿美元大关,年增长率更是超过了 35% 的傲人成绩。Papers with Code 的文本到图像生成基准评测显示,市场呈现出开源与闭源并存的竞争格局:
| 阵营类型 | 代表工具 | 核心特色 | 发展重点 |
|---|---|---|---|
| 开源阵营 | Stable Diffusion 3.5 | 技术创新活跃 | 提示遵循和图像质量显著提升 |
| 商业闭源 | Midjourney v7、Adobe Firefly 4.0 | 产品化成熟 | 专注用户体验和商业应用 |
| 大厂布局 | Google Imagen 4、OpenAI GPT-4o、Google Gemini 2.5 Flash | 资源雄厚 | 积极投入研发和多模态能力 |
| 技术创新 | FLUX.1-Kontext、Black Forest Labs | 技术突破 | Flow-matching 技术和多模态编辑能力 |
商业应用场景正在快速拓展,从最初的艺术创作扩展到营销设计、产品原型、教育培训、娱乐内容等多个领域。对于 AI 图像编辑需求,Google Gemini 2.5 Flash Image 提供了强大的编辑能力。
主流 AI 图像生成工具深度分析
开源领军者:Stable Diffusion
Stable Diffusion 的核心优势是什么?
Stable Diffusion 作为开源 AI image generator 的优秀代表,具有四大核心优势:
- 完全免费和开源,用户可自由使用和修改;
- 支持本地部署,保障数据隐私和安全;
- 强大的社区生态,拥有丰富的模型和插件;
- 高度可定制性,支持 LoRA、ControlNet 等扩展功能。作为最受欢迎的免费 AI 图像生成器,它适用于个人创作、企业定制化部署、研究开发等多种场景。
技术架构特点
| 技术特性 | 具体描述 | 技术优势 |
|---|---|---|
| 潜在扩散技术 | 在压缩的潜在空间中进行扩散过程 | 降低计算成本,保持图像品质 |
| CLIP文本理解 | 强大的文本-图像语义对齐能力 | 精确理解用户意图 |
| VAE高质量解码 | 确保最终图像的细节和质量 | 输出图像细节丰富 |
| 多模型版本支持 | Large(8.1B 参数)、Turbo、Medium 等不同规模版本 | 满足不同性能需求 |
| 开源生态兼容性 | 与广泛的开源工具和插件生态系统完全兼容 | 扩展性强,定制灵活 |
Stable Diffusion 技术解析
Stable Diffusion 堪称开源 AI 图像生成领域的一颗明珠,它基于精巧的潜在扩散模型(Latent Diffusion Model)架构,通过在神秘的潜在空间中执行扩散魔法,创造出令人叹为观止的高质量图像。它的技术核心由三大组件构成:善解人意的文本编码器(CLIP)、精准高效的 U-Net 去噪网络,以及巧夺天工的变分自编码器(VAE)。相比传统的像素空间扩散模型,Stable Diffusion 选择在低维潜在空间中施展魔法,既大幅降低了计算成本,又完美保持了图像的卓越品质。
技术架构组成:
| 组件名称 | 功能描述 | 技术特点 |
|---|---|---|
| CLIP 文本编码器 | 将文本描述转换为语义向量 | 强大的文本-图像语义对齐能力 |
| U-Net 去噪网络 | 在潜在空间中逐步去除噪声 | 高效的潜在空间扩散处理 |
| VAE 解码器 | 将潜在表示转换为最终图像 | 确保最终图像的细节和质量 |

适用场景分析
| 应用场景 | 核心优势 | 具体特点 | 适用人群 |
|---|---|---|---|
| 个人艺术创作 | 完全免费使用 | 无生成次数限制,丰富的艺术风格模型,支持精细化参数调整 | 个人创作者、艺术爱好者 |
| 企业级部署 | 私有化部署 | 保护数据安全,可根据业务需求定制模型,灵活的 API 集成方案 | 企业用户、技术团队 |
| 研究开发 | 开源生态 | GitHub 开源仓库提供完整代码库,支持自定义模型训练,活跃的技术社区支持 | 研究人员、开发者 |
核心功能矩阵
| 功能类型 | 具体能力 | 技术实现 | 适用场景 |
|---|---|---|---|
| 文本生图 | 根据描述生成图像 | Latent Diffusion | 创意设计、内容创作 |
| 图像转换 | 风格迁移、变体生成 | Image-to-Image | 图像编辑、风格化 |
| 精确控制 | ControlNet控制生成 | 条件扩散模型 | 精确构图、姿态控制 |
| 风格定制 | LoRA微调训练 | 低秩适应技术 | 个性化风格、品牌定制 |
性能与配置要求
| 配置类型 | 硬件要求 | 性能表现 | 适用场景 |
|---|---|---|---|
| 最低配置 | 4GB 显存,GTX 1660 级别显卡 | 30-60 秒/张生成速度 | 基础使用、学习体验 |
| 推荐配置 | 8GB+ 显存,RTX 3070 以上显卡 | 15-30 秒/张生成速度 | 专业创作、批量处理 |
| 输出分辨率 | 512×512 到 2048×2048 可调 | 根据需求灵活调整 | 不同用途适配 |
版权使用说明
Stable Diffusion 采用 CreativeML OpenRAIL-M 许可证,允许商业使用但需要注意:
| 使用限制 | 具体要求 | 风险等级 | 建议措施 |
|---|---|---|---|
| 用途限制 | 不得用于非法或有害用途 | 高风险 | 严格遵守使用条款 |
| 版权保护 | 生成内容不得侵犯他人版权 | 中风险 | 进行相似性检查 |
| 商业使用 | 建议咨询法律意见 | 中风险 | 寻求专业法律建议 |
| 训练数据 | 某些训练数据可能存在版权争议 | 低风险 | 了解数据来源 |
艺术创作之王:Midjourney
Midjourney v7 有什么突破性功能?
Midjourney v7 作为顶级 AI image generator,于 2025 年 4 月正式发布,带来了革命性的功能升级。核心突破包括:1)默认模型精度显著提升,可处理长提示和图像提示;2)新增 Draft Mode 草图模式,支持快速预览和迭代优化;3)Omni Reference 全能参考功能,提高创作灵活性;4)增强的 Vary Region 局部编辑能力,可选定图像区域进行再生;5)改进的 Remix 模式,支持在选中区域同时修改提示词。这使得 midjourney ai 成为艺术创作领域的领先选择,v7 在图像质量、角色和物体细节上优于以前版本,生成速度也更快。
技术特色与优势
艺术表现力
Midjourney v7 在美学创造力与细节表现方面达到业界顶级水平,其生成算法特别擅长:
| 艺术能力 | 具体表现 | v7版本改进 |
|---|---|---|
| 色彩光影 | 色彩搭配和光影效果 | 更自然的色彩过渡 |
| 风格表达 | 艺术风格的准确表达 | 风格一致性提升 |
| 构图美感 | 构图美感的智能优化 | 更平衡的视觉布局 |
| 细节渲染 | 细节纹理的精致渲染 | 纹理细节更丰富 |
| 人体结构 | 手部与解剖结构渲染 | 显著改善人体结构细节 |
| 工作流 | Remix 和 Blend 工作流 | 支持更复杂的创作流程 |
风格控制能力
| 控制参数 | 功能描述 | 使用效果 |
|---|---|---|
| 风格参数 | --style 提供丰富的艺术风格选项 | 精确控制艺术风格 |
| 风格权重 | --stylize 控制风格化程度 | 调整风格强度 |
| 混合模式 | 支持多个风格的融合生成 | 创造独特风格组合 |
| 参考图像 | --sref 功能实现风格参考 | 基于参考图生成风格 |
v7版本核心新特性
| 功能类别 | 具体特性 | 技术优势 | 用户体验提升 |
|---|---|---|---|
| 个性化生成算法 | 学习用户历史偏好,自动调整生成风格 | 智能学习用户偏好 | 个人化推荐系统,风格一致性保持 |
| Draft 模式创新 | 快速预览生成(10-15 秒),多版本对比选择 | 大幅提升生成效率 | 迭代优化工作流,成本效率大幅提升 |
| 增强功能特性 | 文本渲染质量显著改善,人像生成更加真实 | 技术精度提升 | 中文语音命令支持,风格控制参数精细化 |
适用场景详解
| 应用领域 | 具体场景 | 核心优势 | 目标用户 |
|---|---|---|---|
| 专业艺术创作 | 概念艺术设计、插画和封面创作、艺术风格探索、创意灵感激发 | 最高艺术质量,美学表现力强 | 专业艺术家、概念设计师 |
| 商业设计项目 | 品牌视觉设计、营销素材创作、产品概念可视化、广告创意生成 | 商业级质量,品牌适配性强 | 品牌设计师、营销团队 |
| 内容创作领域 | 社交媒体配图、文章插图制作、视频缩略图设计、创意内容产出 | 快速迭代,创意表达丰富 | 内容创作者、自媒体运营 |
性能优势对比
| 指标 | v6 | v7 | 提升幅度 |
|---|---|---|---|
| 生成速度 | 60-90 秒 | 40-60 秒 | 30%+ |
| 艺术质量 | 优秀 | 行业领先 | 显著提升 |
| 文本渲染 | 基础 | 精确 | 质的飞跃 |
| 个性化 | 无 | 智能学习 | 全新功能 |
定价策略分析
| 订阅类型 | 月费用 | 快速生成次数 | 核心功能 | 适用人群 |
|---|---|---|---|---|
| 基础订阅 | $10/月 | 200 次快速生成 | 无限制放松模式,基础商业使用权,社区画廊访问 | 个人创作者、初学者 |
| 标准订阅 | $30/月 | 900 次快速生成 | 无限制放松模式,隐私模式可选,完整商业授权 | 专业创作者、小团队 |
| 专业订阅 | $60/月 | 1800 次快速生成 | 优先队列处理,高级功能访问,企业级支持 | 专业工作室、企业用户 |
专业工具集成:Adobe Firefly
Adobe Firefly 的独特优势有哪些?
Adobe Firefly 的核心特色在于与 Creative Cloud 的深度集成和商业安全保障。主要功能包括:AI 文本转图像、生成式填充、文本效果生成、矢量图形生成和 AI 视频编辑。Adobe Firefly 官方平台展示的所有生成内容都经过版权安全训练,确保商业使用合规。与 Photoshop、Illustrator、Express 等 Adobe 软件无缝集成,支持云端同步和团队协作。对于初学者,可以参考 Nano Banana 提示词技巧 来提升 AI 图像生成效果。
技术集成优势
Creative Cloud 生态整合
Adobe Firefly 最大的优势在于与现有 Creative Cloud 工具的深度集成:
| 集成工具 | 核心功能 | 工作流优势 | 使用场景 |
|---|---|---|---|
| Photoshop 集成 | 生成式填充功能直接在 PS 中使用 | 无缝编辑体验 | 图像后期处理、背景替换 |
| Illustrator 整合 | 矢量图形生成无缝对接 | 矢量设计效率提升 | Logo设计、矢量插画 |
| Express 集成 | 快速设计工作流优化 | 简化设计流程 | 社交媒体素材、快速设计 |
| After Effects 支持 | AI 视频内容生成 | 视频制作创新 | 动态图形、视频特效 |
工作流无缝衔接
| 功能特性 | 具体表现 | 商业价值 |
|---|---|---|
| 云端同步 | 确保文件一致性 | 团队协作效率提升 |
| 团队协作 | 功能完善 | 多人协作项目管理 |
| 版本控制 | 历史记录管理 | 设计迭代追踪 |
| 批量处理 | 自动化支持 | 大规模内容生产 |
商业安全保障
版权合规训练
Adobe Firefly 的训练数据经过严格筛选:
| 数据来源 | 安全等级 | 商业保障 | 风险控制 |
|---|---|---|---|
| Adobe Stock 授权内容 | 最高 | 完全商业授权 | 零版权风险 |
| 公开领域图像 | 高 | 自由使用 | 无版权限制 |
| 用户许可内容 | 高 | 明确授权 | 用户同意使用 |
| 法律保护 | 最高 | 额外赔偿保护 | 企业级保障 |
企业级安全特性
| 安全功能 | 具体措施 | 企业价值 |
|---|---|---|
| 数据处理透明度 | 透明度报告 | 合规性保障 |
| 隐私保护机制 | 企业级隐私保护 | 数据安全 |
| 合规性审核 | 审核支持 | 法律合规 |
| 商业使用赔偿 | 赔偿保护 | 风险转移 |
核心功能详解
核心功能详解
| 功能类别 | 具体能力 | 技术特色 | 应用场景 |
|---|---|---|---|
| 生成式填充 | 智能背景扩展、物体移除和替换、场景元素添加、无缝融合效果 | 革命性图像编辑 | 图像后期处理、背景替换 |
| 文本效果生成 | 3D 文字效果、艺术字体设计、纹理和材质应用、动态效果预览 | 专业文字视觉设计 | 标题设计、文字特效 |
| AI 矢量图形 | 可编辑的矢量路径、无损缩放支持、品牌色彩适配、图标和 Logo 设计 | 面向专业设计 | Logo设计、矢量插画 |
适用场景分析
| 应用场景 | 主要功能 | 优势特点 | 目标用户 |
|---|---|---|---|
| 专业设计 | 完整工具链集成 | 工作流效率最高 | 设计师、创意总监 |
| 企业营销 | 品牌安全素材生成 | 版权风险最低 | 市场营销团队 |
| 内容创作 | 批量素材处理 | 规模化生产能力 | 内容创作机构 |
| 教育培训 | 教学素材制作 | 安全合规使用 | 教育机构 |
商业模式说明
Adobe Firefly 包含在 Creative Cloud 订阅中:
| 版本类型 | 月费用 | 核心功能 | 适用场景 |
|---|---|---|---|
| 个人版 | $20.99/月 | 包含基础 AI 功能 | 个人创作者、自由职业者 |
| 团队版 | $33.99/月/用户 | 增强协作功能 | 小团队、工作室 |
| 企业版 | $79.99/月/用户 | 完整商业保护 | 大型企业、机构 |
对话式生成:OpenAI DALL-E 与 GPT-4o Image
技术架构特点
DALL-E 基于 GPT 架构的多模态生成模型,具有独特的技术优势:
GPT 架构优势
| 技术优势 | 具体表现 | 用户体验 |
|---|---|---|
| 自然语言理解 | 强大的自然语言理解能力 | 直观的文本交互 |
| 概念组合创新 | 概念组合和创新能力 | 创意表达丰富 |
| 上下文处理 | 上下文相关性处理 | 连贯的对话体验 |
| 交互体验 | 对话式交互体验 | 自然的人机交互 |
GPT-4o Image 多模态创新
OpenAI 最新的 GPT-4o Image 代表了多模态大模型的重要突破,实现了图文、音视频、代码的同源理解。这意味着模型不仅能生成图像,还能深度理解各种形式的输入内容,提供更智能的创作建议。
o3 模型的"图像思考"能力
即将推出的 o3 模型带来了"Thinking with Images"的创新概念,在处理复杂推理任务时表现卓越。这种能力让 AI 不仅仅是生成图像,而是能够理解图像背后的逻辑关系和概念结构。
多模态集成
| 集成能力 | 技术特点 | 应用优势 |
|---|---|---|
| 深度融合 | 文本和图像的深度融合 | 更准确的理解和生成 |
| 跨模态理解 | 跨模态语义理解 | 多形式内容处理 |
| 概念抽象 | 概念抽象能力强 | 复杂概念表达 |
| 创意想象 | 创意想象力突出 | 创新性内容生成 |
与ChatGPT集成优势
与ChatGPT集成优势
| 集成特性 | 具体功能 | 用户体验 | 技术优势 |
|---|---|---|---|
| 对话式创作 | 自然语言交互界面,迭代式需求优化,创意 brainstorming 支持,智能建议和改进 | 直观易用 | 自然语言处理 |
| 工作流集成 | ChatGPT Plus 用户直接访问,API 接入简单便捷,开发者友好的接口,OpenAI 官方文档提供完整的集成指南 | 无缝集成 | 标准化接口 |
核心应用场景
| 应用领域 | 具体场景 | 核心优势 | 目标用户 |
|---|---|---|---|
| 快速概念可视化 | 产品想法快速原型、创意概念表达、设计方案讨论、用户需求可视化 | 快速迭代,概念表达清晰 | 产品经理、设计师 |
| 教育内容创作 | 教学插图生成、概念解释图表、科学实验示意、历史场景重现 | 教育价值高,解释性强 | 教育工作者、学生 |
| 社交媒体内容 | 个性化头像创作、社交平台配图、表情包制作、创意内容分享 | 个性化强,传播效果好 | 内容创作者、个人用户 |
技术规格说明
生成质量特点
| 质量维度 | 表现特点 | 技术优势 |
|---|---|---|
| 概念理解 | 准确度高 | 强大的语言理解能力 |
| 细节表现 | 表现力较强 | 良好的细节渲染 |
| 色彩搭配 | 协调自然 | 智能色彩处理 |
| 构图设计 | 相对简洁 | 清晰的视觉表达 |
定价模式分析
定价模式分析
| 定价类型 | 价格标准 | 适用场景 | 成本优势 |
|---|---|---|---|
| 标准尺寸 | $0.040/张(1024×1024) | 常规使用 | 性价比出众 |
| 特殊尺寸 | $0.080/张(1024×1792 或 1792×1024) | 特殊需求 | 物有所值 |
| 批量优惠 | 批量折扣 | 大量使用 | 成本进一步降低 |
| 企业折扣 | 专属优惠 | 企业用户 | 专属折扣优惠 |
成本效益评估
| 用户群体 | 使用特点 | 成本优势 | 适用性 |
|---|---|---|---|
| 个人创作者 | 偶尔使用 | 按需付费,无月费负担 | 高 |
| 项目团队 | 需求不确定 | 灵活付费,避免浪费 | 高 |
| 试验性艺术家 | 创意探索 | 低成本试验,风险可控 | 高 |
| 教育研究机构 | 预算控制严格 | 精确成本控制 | 高 |
易用性典范:Leonardo AI & Krea AI
Leonardo AI核心特色
用户体验设计 Leonardo AI如同一位贴心的AI创作助手,它的最大使命就是让AI图像生成变得简单易学:
Leonardo AI核心特色
| 功能类别 | 具体特性 | 技术优势 | 用户体验 |
|---|---|---|---|
| Phoenix模型 | 更好的prompt理解能力,更稳定的生成质量,更快的处理速度,更丰富的风格表现 | 技术性能提升 | 生成效果更佳 |
| 实时Canvas | 实时预览生成过程,交互式编辑体验,即时参数调整,可视化创作过程 | 实时交互技术 | 创作体验流畅 |
| 社区生态 | 丰富的预设模型库,用户作品分享平台,学习教程和案例,活跃的用户社区 | 社区驱动发展 | 学习资源丰富 |
Krea AI技术创新
实时生成技术 Krea AI在实时图像生成领域取得突破:
Krea AI技术创新
| 技术类别 | 核心功能 | 技术突破 | 应用价值 |
|---|---|---|---|
| 实时Canvas | 闪电般的毫秒级响应速度,手绘草图瞬间变为精美图像,风格切换随心所欲,多人协作编辑 | 实时生成技术突破 | 创作效率革命性提升 |
| AI Patterns | 无缝纹理生成,图案设计自动化,品牌元素应用,批量变体生成 | 自动化设计能力 | 批量生产效率 |
| 增强器工具 | 图像分辨率提升,细节优化增强,噪声去除处理,色彩校正功能 | 后处理技术优化 | 图像质量提升 |
适用场景对比
| 工具 | 主要优势 | 适用场景 | 学习成本 | 价格区间 |
|---|---|---|---|---|
| Leonardo AI | 界面友好,功能全面 | 新手入门,快速出图 | 极低 | $12-48/月 |
| Ideogram 3.0 | 文本渲染,永久免费 | Logo设计,文字图像 | 极低 | 永久免费 |
功能对比分析
| 工具名称 | 核心功能 | 技术特色 | 商业价值 |
|---|---|---|---|
| Leonardo AI | 文本转图像生成,AI视频制作工具,图像升级和增强,3D纹理生成,批量处理功能 | 功能全面,易用性强 | 付费订阅模式 |
| Ideogram 3.0 | 专业文本渲染和排版,Canvas无限画布工作流,Magic Fill和Extend编辑,角色参考和风格一致性,商业使用免费授权 | 文本渲染专业,永久免费 | 免费商业使用 |
技术创新者:FLUX系列
详细了解:FLUX AI图像生成技术深度解析
Flow-matching技术突破
FLUX系列代表了AI图像生成技术的最新发展方向:
技术架构创新 传统的扩散模型存在采样步骤多、生成速度慢的问题。FLUX采用Flow-matching技术实现了质的突破:
Flow-matching技术突破
| 技术原理 | 具体优势 | 性能提升 | 技术价值 |
|---|---|---|---|
| Flow-matching原理 | 直接学习从噪声到图像的映射路径,减少采样步骤,更稳定的训练过程,更高的图像质量上限 | 生成速度提升50%以上 | 技术路线创新 |
| 性能优化 | 图像细节表现增强30%,内存使用效率优化25%,多分辨率支持更灵活 | 整体性能显著提升 | 实用性大幅增强 |
FLUX模型矩阵
FLUX模型矩阵
| 版本类型 | 核心特性 | 技术规格 | 适用场景 |
|---|---|---|---|
| FLUX.1-Kontext [max] | 最高画质和编辑能力,原生上下文编辑支持,角色一致性和本地编辑,商业级API服务 | 旗舰版本 | 商业级应用 |
| FLUX.1-Kontext [pro] | 高质量图像生成和编辑,合作伙伴平台支持(Krea AI、Leonardo等),完整商业授权,风格参考和交互式编辑 | 专业版本 | 专业创作 |
| FLUX.1-Kontext [dev] | 12B参数开源研究版本,私人测试发布阶段,支持本地部署,社区技术支持 | 开发版本 | 研究开发 |
技术创新亮点
| 技术特性 | 具体表现 | 技术优势 |
|---|---|---|
| Flow-matching技术 | 流匹配技术 | 技术路线创新 |
| 上下文编辑 | 无需微调的上下文编辑 | 编辑能力突破 |
| 推理速度 | 10倍推理速度提升 | 性能大幅提升 |
| 统一模型 | 统一的文本生成和图像编辑模型 | 多模态集成 |
技术前瞻性分析
行业影响预测 FLUX技术的成功将可能引发整个行业的技术路线转向:
技术前瞻性分析
| 影响维度 | 具体变化 | 行业影响 | 发展趋势 |
|---|---|---|---|
| 技术冲击 | 传统Diffusion模型面临技术压力,生成速度成为新的竞争重点,API服务成本结构重新洗牌,开源社区关注度转移 | 技术路线转向 | 行业格局重塑 |
| 未来趋势 | Flow-matching技术逐步普及,实时生成成为标准功能,多模态融合加速发展,个性化定制门槛降低 | 技术普及加速 | 用户体验提升 |
| 2025年发展 | 视频生成集成(Google Veo 3),提示理解增强,多主体一致性改善 | 技术能力扩展 | 应用场景拓展 |
多模态编辑专家:Google Gemini 2.5 Flash Image
核心技术突破
什么是 Gemini 2.5 Flash Image?
Google Gemini 2.5 Flash Image 代表了 AI 图像生成领域的最新突破,它不仅是一个文本到图像生成器,更是一个强大的多模态图像编辑平台。作为 Google 最新发布的 AI image generator,它集成了先进的多模态理解能力,能够同时处理文本、图像和用户指令,实现前所未有的图像编辑精度。
Nano Banana 技术创新
Gemini 2.5 Flash Image 的突出特色是其独创的 Nano Banana 编辑技术,这项技术允许用户通过简单的文本指令对现有图像进行精确修改:
| 技术特性 | 具体能力 | 技术优势 | 应用价值 |
|---|---|---|---|
| 智能对象识别 | 自动识别图像中的各类对象和元素 | 精确理解图像内容 | 编辑精度提升 |
| 精确区域编辑 | 支持指定区域的精确修改和替换 | 局部编辑能力 | 编辑灵活性 |
| 风格保持技术 | 在编辑过程中保持原图整体风格一致性 | 风格连贯性 | 视觉一致性 |
| 多轮对话编辑 | 支持迭代式的细化修改过程 | 交互式编辑 | 用户体验优化 |
功能特色分析
功能特色分析
| 功能类别 | 具体能力 | 技术特色 | 应用场景 |
|---|---|---|---|
| 图像编辑 | 添加元素、移除对象、风格转换、场景重构 | 智能编辑,保持视觉和谐 | 图像后期处理 |
| 多模态集成 | 自然语言交互、上下文理解、实时预览、批量处理 | 对话式编辑体验 | 高效内容创作 |
图像编辑能力详解
| 编辑类型 | 具体功能 | 技术优势 |
|---|---|---|
| 添加元素 | 在现有图像中智能添加新对象,保持视觉和谐 | 智能融合技术 |
| 移除对象 | 精确移除指定元素,自动补全背景 | 背景修复算法 |
| 风格转换 | 改变图像整体或局部的艺术风格 | 风格迁移技术 |
| 场景重构 | 修改背景环境或整体场景布局 | 场景理解能力 |
使用场景与优势
| 应用场景 | 具体用途 | 核心优势 | 目标用户 |
|---|---|---|---|
| 产品图像优化 | 电商产品图片的精确修改和优化 | 编辑精度高 | 电商运营、产品经理 |
| 创意内容制作 | 广告设计中的元素调整和风格统一 | 操作简单直观 | 广告设计师、营销团队 |
| 教育内容创作 | 教学材料中图像的定制化编辑 | 集成度良好 | 教育工作者、内容创作者 |
| 个人创作项目 | 艺术作品的细节完善和创意探索 | 更新频率快 | 个人创作者、艺术家 |
核心竞争优势
| 竞争优势 | 具体表现 | 技术支撑 |
|---|---|---|
| 编辑精度 | 得益于 Google 强大的 AI 技术积累 | 先进AI技术 |
| 操作体验 | Nano Banana 提示词技巧 让编辑变得简单易学 | 用户友好设计 |
| 生态集成 | 与 Google 生态系统深度整合 | 平台优势 |
| 技术更新 | 持续的技术改进和功能增强 | 持续创新 |
定价与可用性
| 服务类型 | 具体内容 | 适用场景 | 技术门槛 |
|---|---|---|---|
| 免费体验 | 新用户可获得有限的免费编辑次数 | 试用体验 | 低 |
| 按需付费 | 根据实际使用量灵活付费 | 灵活使用 | 低 |
| 企业套餐 | 为企业用户提供专业级服务支持 | 企业应用 | 中等 |
技术门槛评估
| 用户类型 | 使用特点 | 适用性 | 学习成本 |
|---|---|---|---|
| 设计师 | 需要精确图像编辑 | 高 | 低 |
| 营销团队 | 寻求高效内容创作 | 高 | 低 |
| 技术爱好者 | 追求创新体验 | 高 | 低 |
| 企业用户 | 重视集成体验 | 高 | 中等 |
更多详细的使用指南和技巧,可以参考 Google Gemini 2.5 Flash Image 编辑器 的完整教程。
综合对比与选择指南
工具选择决策框架
如何选择最适合的AI图像生成工具?
选择最佳的AI image generator需要考虑八个关键维度:
- 成本预算(免费vs付费);
- 使用场景(艺术创作vs商业应用);
- 技术门槛(一键生成vs专业调参);
- 版权安全(商业使用合规性);
- 集成需求(独立工具vs工作流集成);
- 输出质量(艺术效果vs真实感);
- 文本渲染能力;
- 编辑功能支持。
八维度功能对比矩阵
| 工具名称 | 成本 | 易用性 | 艺术质量 | 版权安全 | 技术灵活性 | 商业集成 | 文本渲染 | 编辑能力 |
|---|---|---|---|---|---|---|---|---|
| Stable Diffusion 3.5 | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
| Midjourney v7 | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| Adobe Firefly 4.0 | ⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| OpenAI DALL-E | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| Leonardo AI | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
| FLUX.1-Kontext | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| Google Imagen 4 | ⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐ |
| Gemini 2.5 Flash Image | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| Ideogram 3.0 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |

使用场景选择矩阵
| 使用场景 | 首选工具 | 理由分析 | 月成本预估 | 学习难度 | 替代方案 |
|---|---|---|---|---|---|
| 个人艺术创作 | Midjourney | 艺术表现力最强,社区活跃 | $10-30 | 中等 | Stable Diffusion |
| 商业设计项目 | Adobe Firefly | 版权安全+完整工具集成 | $21起 | 低 | Leonardo AI |
| 技术研发实验 | Stable Diffusion | 开源免费+完全可控 | 仅硬件成本 | 高 | FLUX Dev |
| 快速原型设计 | Leonardo AI | 界面友好+模板丰富 | $12-48 | 低 | Krea AI |
| 企业级部署 | Adobe Firefly | 商业合规+批量处理 | 企业授权 | 中等 | API组合 |
| 教育培训 | DALL-E + ChatGPT | 对话式交互+概念解释 | $20 | 低 | Leonardo AI |
| 内容创作 | Midjourney | 高质量输出+快速迭代 | $10-30 | 中等 | FLUX Schnell |
| 图像精确编辑 | Gemini 2.5 Flash Image | Nano Banana技术+多模态编辑 | 按需付费 | 低 | Adobe Firefly |
成本效益分析框架
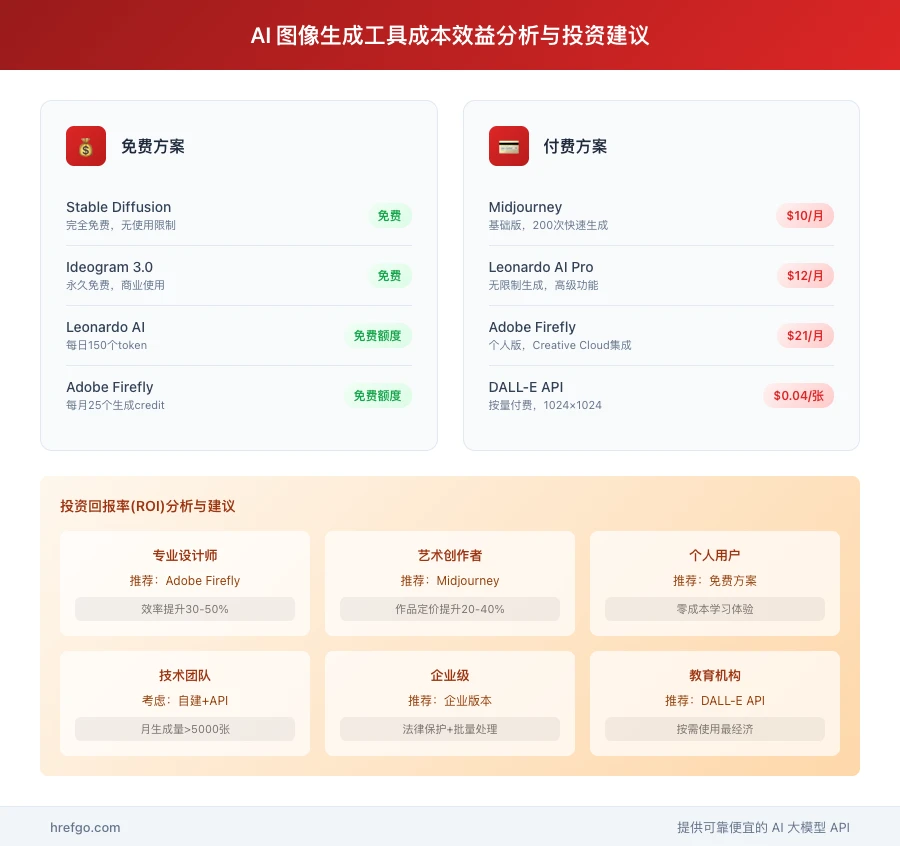
免费方案对比
Stable Diffusion
- ✅ 完全免费,无使用限制
- ✅ 社区模型资源丰富
- ❌ 需要技术配置和硬件投入
- ❌ 学习成本较高
有限免费额度工具对比
| 工具名称 | 免费额度 | 限制条件 | 续费方式 |
|---|---|---|---|
| Leonardo AI | 每日150个token | 需要注册账户 | $12-48/月 |
| Adobe Firefly | 每月25个生成credit | 需要Adobe账户 | $21起/月 |
| DALL-E | ChatGPT Plus用户包含额度 | 需要Plus订阅 | $20/月 |
付费方案ROI分析
专业设计师推荐
- 首选:Adobe Firefly($21/月)
- ROI分析:工具集成价值超过单独订阅成本
- 预期回报:工作效率提升30-50%
艺术创作者推荐
- 首选:Midjourney Standard($30/月)
- ROI分析:艺术质量带来的商业价值
- 预期回报:作品定价可提升20-40%
技术团队评估
- 考虑因素:API成本vs开发效率
- 阈值分析:月生成量超过5000张建议自建
- 混合策略:开源+商业API组合使用
版权安全与商业应用指南
版权风险评估矩阵
工具版权安全等级
最高安全级别:Adobe Firefly
- ✅ 商业训练数据验证
- ✅ 版权侵权赔偿保护
- ✅ 企业级合规支持
- ✅ 透明的数据来源政策
较高安全级别:DALL-E
- ✅ OpenAI商业许可明确
- ✅ 使用条款清晰详细
- ✅ 定期的政策更新
- ⚠️ 某些用途仍有限制
中等安全级别:Midjourney
- ✅ 付费版本提供商业授权
- ⚠️ 训练数据来源相对模糊
- ⚠️ 需要仔细阅读使用条款
- ⚠️ 社区分享可能有风险
较低安全级别:Stable Diffusion
- ⚠️ 开源许可但训练数据复杂
- ⚠️ 需要用户自行评估风险
- ⚠️ 衍生模型许可各不相同
- ❌ 无官方商业保护
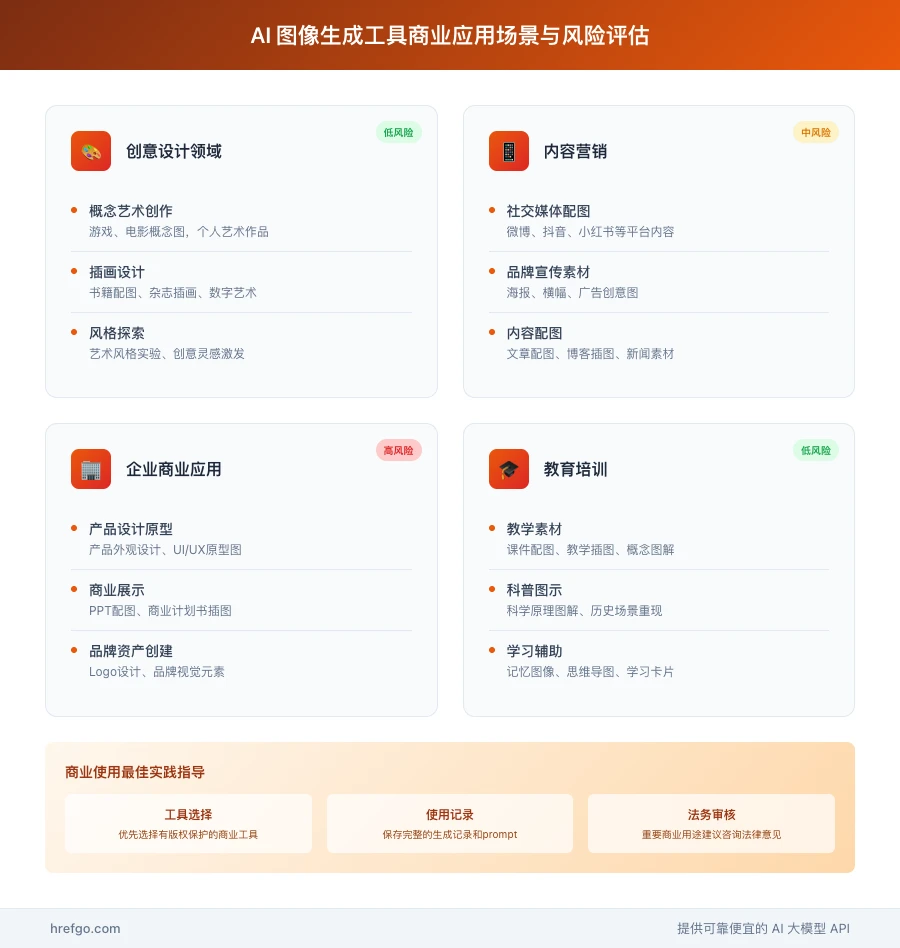
商业使用最佳实践
合规使用清单
使用前准备
- ✅ 仔细研读工具使用条款
- ✅ 了解训练数据来源政策
- ✅ 建立生成内容档案记录
- ✅ 制定内容审核标准
生成过程管控
- ✅ 避免使用受版权保护的IP名称
- ✅ 不生成真实人物肖像
- ✅ 谨慎处理品牌和Logo元素
- ✅ 记录详细的prompt信息
使用后检查
- ✅ 进行相似性搜索检查
- ✅ 咨询法律专业意见
- ✅ 购买商业保险覆盖
- ✅ 建立应急处理预案
不同场景风险建议
品牌营销使用
- 推荐工具:Adobe Firefly
- 风险等级:低
- 注意事项:避免竞品元素,保持品牌一致性
内容创作媒体
- 推荐工具:Midjourney商业版
- 风险等级:中
- 注意事项:标注AI生成来源,避免误导性内容
产品设计应用
- 推荐工具:Leonardo AI Pro
- 风险等级:中
- 注意事项:确保设计原创性,避免抄袭嫌疑
技术开发集成
- 推荐工具:API组合使用
- 风险等级:中-高
- 注意事项:建立完整的法务审核流程
常见问题解答
工具选择FAQ
Q1:完全免费的 AI 图像生成工具有哪些?
A1:Stable Diffusion 是唯一完全免费的高质量选择,但需要一定技术配置能力。Leonardo AI和Adobe Firefly提供有限的免费额度,适合轻度使用。建议初学者先从免费额度工具开始,了解功能差异后再考虑付费升级。
Q2:商业使用最安全的工具是什么?
A2:Adobe Firefly 提供最高级别的商业使用安全保障,其训练数据经过严格版权筛选,并提供额外法律保护。OpenAI DALL-E次之,有明确的商业许可条款。其他工具需要仔细评估版权风险。
Q3:哪个工具最适合专业设计师?
A3:推荐 Adobe Firefly,原因包括:与Creative Cloud深度集成、工作流无缝衔接、版权安全有保障、专业功能丰富。Midjourney适合需要高艺术表现力的项目,Leonardo AI适合快速原型设计需求。
Q4:个人创作者预算有限如何选择?
A4:建议分阶段投入:1)首先学习Stable Diffusion,掌握免费高质量生成;2)根据创作需求选择Midjourney基础版($10/月)或Leonardo AI($12/月);3)有商业化需求时再考虑Adobe Firefly专业版。
Q5:AI 生成图像可以直接用于商业用途吗?
A5:需要根据具体工具的许可条款判断。Adobe Firefly可直接商用且有法律保护,Midjourney需要付费版本授权,Stable Diffusion需要仔细评估版权风险,DALL-E有一定商业使用限制。建议使用前详细阅读条款。
技术使用FAQ
Q6: 如何提高AI生成图像的质量?
A6: 质量提升的关键策略:
- 优化prompt描述:使用具体、详细的描述语言
- 学习专业术语:掌握艺术、摄影、设计专业词汇
- 添加质量修饰词:如"高质量"、"4K"、"专业摄影"等
- 参考优秀案例:学习社区分享的高质量prompt
- 多次迭代优化:通过反复调整获得最佳效果
Q7: 不同工具的学习成本如何?
A7: 学习难度排序(从易到难):
- Leonardo AI:界面最友好,30分钟上手
- Adobe Firefly:集成简单,1小时掌握基础
- DALL-E:对话交互,1-2小时熟练
- Midjourney:需要学习prompt技巧,1-2周精通
- Stable Diffusion:技术门槛最高,需要1-2月深度学习
Q8: 如何处理生成的低质量图像?
A8: 改进低质量结果的方法:
- 优化prompt描述:增加细节描述和质量要求
- 调整参数设置:尝试不同的风格和质量参数
- 使用增强工具:通过AI升级和后期处理改善
- 多次生成对比:选择多个结果中的最佳版本
- 学习优质案例:分析高质量作品的prompt特点
Q9: Gemini 2.5 Flash Image 的 Nano Banana 技术有什么特殊优势?
A9: Nano Banana 技术的核心优势包括:
- 精确编辑能力:能够对图像进行精确的区域编辑和对象修改
- 多模态理解:同时理解文本指令和图像内容的语义关系
- 自然语言交互:通过简单的对话完成复杂的图像编辑任务
- 风格保持技术:在编辑过程中保持原图的整体风格一致性
- 实时预览:即时展示编辑效果,支持快速调整和优化 特别适合需要精确控制图像编辑结果的专业用户和设计师。
Q10: 什么情况下应该选择 Gemini 2.5 Flash Image 而不是其他工具?
A10: 建议在以下场景选择 Gemini 2.5 Flash Image:
- 精确图像编辑需求:需要对现有图像进行精细修改
- 产品图像优化:电商或营销中的产品图片精确调整
- 多轮对话编辑:需要通过对话方式逐步完善图像效果
- Google生态集成:已在使用Google工作流程的团队
- 技术门槛限制:希望通过简单对话实现专业编辑效果
Q11: 2025年选择AI图像生成工具时应该重点考虑哪些因素?
A11: 基于最新技术发展趋势,选择AI图像生成工具时应该重点考虑:
- 精确度要求:不同工具在细节控制和准确性方面差异显著
- 控制程度:从简单一键生成到复杂参数调节的不同需求
- 商业合规性:版权安全和商业使用授权的重要性日益增强
- 界面模式:API集成、Web界面、桌面应用等不同交互方式
- 专业化程度:OpenAI专注多模态协作,Midjourney强调艺术创造力,Stability AI维持开源生态,Google突出安全性和高分辨率
选择时建议优先明确自己的核心需求,然后从技术特色、成本效益、学习成本三个维度进行综合评估。
结语
AI 图像生成技术正以前所未有的速度发展,从传统的 Stable Diffusion 到最新的 Gemini 2.5 Flash Image 的 Nano Banana 技术,每一项创新都在推动整个行业向前发展。无论您是艺术创作者、设计师、开发者还是企业用户,都能在这个多元化的工具生态中找到最适合自己需求的解决方案。
随着技术的不断进步,我们可以期待看到更多创新功能的出现:更精确的图像编辑能力、更自然的人机交互方式、更强大的多模态理解能力。选择合适的工具不仅能提高工作效率,更能释放创造力的无限潜能。
在这个快速变化的领域中,保持学习和探索的心态至关重要。每一个工具都有其独特的优势和适用场景,理解并掌握它们的特点,将帮助您在 AI 图像生成的道路上走得更远。