
如果你正在评估或准备接入 Gemini 3 API,这篇文章就是为你写的。Gemini 3 是 Google 目前最智能的一代 Gemini 模型家族,官方 Gemini 3 Developer Guide 将其描述为“基于最新推理技术构建的模型家族”,专注解决复杂推理、多模态理解和代理式工作流等高难度任务。通过 Gemini 3 API,你可以在后端服务、Web 应用或企业系统中直接调用 gemini-3-pro-preview 等模型,用于对话、文档分析、代码生成、图像/视频理解等多种场景。
接下来,我们会用一篇中文长文,从以下几个维度系统介绍 Gemini 3 API:
- Gemini 3 模型家族与 Gemini 3 Pro 的定位
- 新增的关键 API 参数:
thinking_level、media_resolution、thought_signatures等 - Gemini 3 Pro 的定价模型:标准调用、Batch API 与上下文缓存
- 如何在 5 分钟内完成首次 Gemini 3 API 调用(Python/Node.js 示例)
- 多模态、长上下文等高阶场景的实践建议
- 常见踩坑与最佳实践
阅读完这篇文章,你应该能回答三个问题:Gemini 3 API 适不适合我?要花多少钱?实际接入时应该怎么设计参数和架构?

一、什么是 Gemini 3 API?
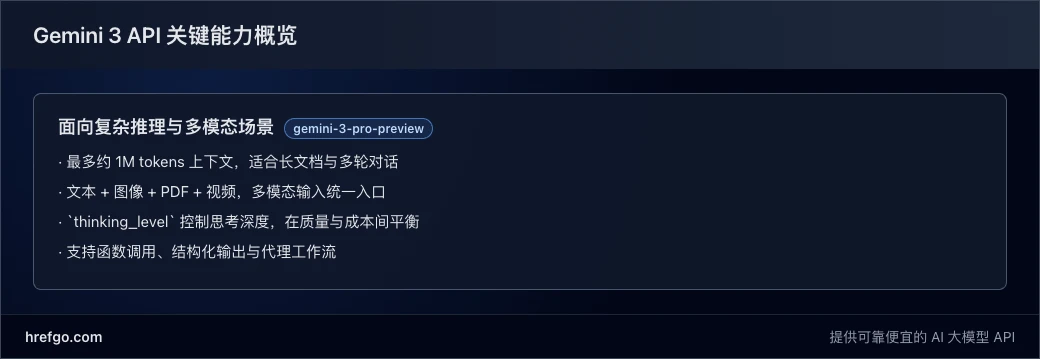
简单地说,Gemini 3 API 是 Google 提供的云端多模态大模型接口,开发者可以通过 HTTP/REST 或官方 SDK 调用最新的 Gemini 3 系列模型(目前主要是 gemini-3-pro-preview),在一个统一的接口下完成文本、图像、PDF、视频等多模态任务。和早期的 Gemini 2.x 相比,Gemini 3 更强调“深度推理 + 代理工作流 + 长上下文”的组合能力。
从 官方文档 可以看到,Gemini 3 Pro 具备以下核心特征:
- 模型 ID:
gemini-3-pro-preview - 上下文窗口:约 1M tokens 输入 / 64k tokens 输出
- 知识截止时间:2025 年 1 月
- 调用方式:REST、Python、JavaScript、Go、Java、C#,并支持 OpenAI 兼容模式
这意味着,你可以在一次请求中放入大量上下文(例如多份长文档或大量聊天历史),让模型在“知道更多的前提下”做更复杂的推理。
Gemini 3 模型家族与 Gemini 3 Pro
Gemini 3 是一个模型家族,Gemini 3 Pro 则是其中面向通用复杂任务的旗舰模型:
- Gemini 3 Pro:适合需要高阶推理和复杂多模态理解的任务,例如长文档审阅、代码审查、复杂问答和多步骤代理。
- 与早期 Gemini 2.5 相比,3 代在复杂推理、视觉理解和代理任务上都有明显提升,同时将上下文窗口推到百万级别。
对大多数“应用层开发者”来说,只要记住一件事:当你需要一个“能自己思考、能处理多模态、能读很长文档”的模型时,就应该优先考虑 Gemini 3 Pro。
二、Gemini 3 的关键新特性一览
相比之前的 Gemini 2.x,Gemini 3 在 API 级别引入了几个非常重要的新参数,它们直接决定了模型的“思考深度、视觉效果和成本表现”。
1. thinking_level:控制思考深度的新参数
Gemini 3 在 API 中新增了 thinking_level 参数,用来控制模型在生成答案前允许的内部推理深度。官方文档中给出的几个等级大致可以理解为:
low:尽可能降低延迟和费用,适合简单问答、闲聊或高并发场景;high(默认):允许模型进行更深的内部推理,适合复杂问题求解、代码审查和多步骤推理;medium:文档中标记为“即将推出”,在正式 GA 前可能暂不可用。
和传统的 max_output_tokens 不同,thinking_level 更像是“思考预算”的上限,而不是硬性的 token 限制。实践上,你可以:
- 对于在线交互或 UI 较敏感的场景,优先使用
low; - 对于代码审查、长文档分析、复杂决策类任务,可以默认使用
high; - 在部分“灰度实验”中,为关键路径任务开启
high,为普通日志/报表类任务使用low,在质量与成本之间做平衡。
2. media_resolution:多模态分辨率与成本平衡
在多模态方向,Gemini 3 引入了 media_resolution 参数,用于控制图像、PDF、视频帧等输入的“视觉分辨率”和对应的 token 使用量。官方推荐大致如下:
- 图像:推荐使用
media_resolution_high(约 1120 tokens),适合需要读取细小文字或复杂细节的场景; - PDF:通常
media_resolution_medium(约 560 tokens)就够用,继续提高分辨率对 OCR 质量提升有限; - 视频:一般推荐
media_resolution_low或medium(约 70 tokens/帧),只有在“需要读视频中小字”的场景才考虑提升到high。
在实际项目中,这个参数直接决定了多模态请求的成本和延迟 —— 如果你对图像/视频质量要求不高,可以优先尝试低或中档分辨率。
3. thought_signatures 与结构化输出
Gemini 3 还引入了与“思维过程可观察性”相关的能力,例如 thought signatures。它可以理解为模型在内部推理后给出的一种“推理轨迹摘要”,可以与结构化输出(JSON Schema)和工具调用结合起来,用于:
- 做安全审计:检查模型在重要决策前后是否经过合理推理;
- 做代理工作流:先让模型输出一个结构化计划,再根据计划调用外部 API 或代码执行环境;
- 做调试与评估:帮助你理解模型在失败案例中的“想错在哪”。
对于构建复杂 Agent 系统的团队,Gemini 3 在这方面的增强非常关键。
三、Gemini 3 Pro 定价与成本控制
官方 Gemini Developer API 定价文档 的信息比较详细,这里只抽取对大多数开发者最重要的部分(具体数值以官方文档为准):
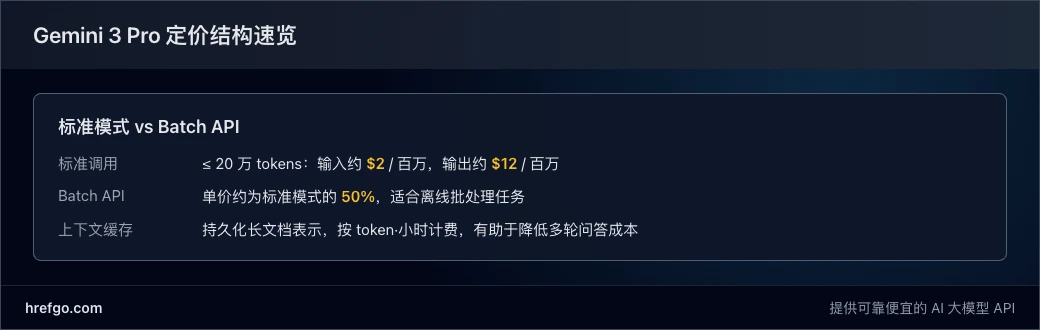
| 模式 / 档位 | 标准模式(≤ 20 万 tokens) | 标准模式(> 20 万 tokens) | 批量模式(≤ 20 万 tokens) | 批量模式(> 20 万 tokens) |
|---|---|---|---|---|
| 输入费用(每百万 tokens) | $2.00 | $4.00 | $1.00 | $2.00 |
| 输出费用(每百万 tokens) | $12.00 | $18.00 | $6.00 | $9.00 |
| 上下文缓存(每百万 token·小时) | $0.20 | $0.40 | $0.20 | $0.40 |
可以看到,Batch API 的单价大约是标准模式的一半,适合离线批处理、日志分析、批量生成等不需要实时响应的场景。
标准调用 vs Batch API:怎么选?
一个简单的决策思路是:
- 如果你的调用是用户实时交互(例如聊天、搜索、在线工具),首选标准模式;
- 如果是离线任务或定时任务(例如每天晚上批量生成报告、批量处理文档),可以考虑 Batch API,降低成本;
- 对于“半实时”场景,可以通过队列和异步处理将部分请求引导到批量任务中。
利用上下文缓存降低长上下文成本
当你频繁在同一批长文档上做多轮推理时,可以使用 上下文缓存(caching) 把文档预先编码并重复使用,这样:
- 首次上传文档时支付较高的 token 成本;
- 后续在同一文档上发起的请求只需支付增量的 prompt 成本。
对于知识库问答、长报告审阅等场景,上下文缓存可以显著降低长期成本,这是在设计系统时值得重点考虑的一点。
四、如何开始使用 Gemini 3 API?(5 分钟 Quickstart)
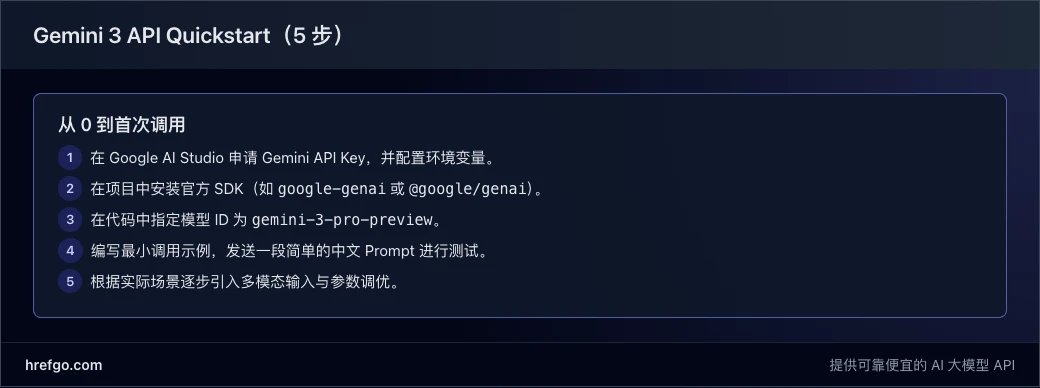
下面用一个简化的流程帮你在 5 分钟内完成首次调用。我们假设你已经拥有 Google 账号,并且可以访问 Google AI Studio。
步骤 1:申请 Gemini API Key
- 访问 Google AI Studio。
- 在 “Get API key” 页面创建一个新的 API Key。
- 将生成的 Key 保存在安全位置,并配置为环境变量,例如
GEMINI_API_KEY。
步骤 2:安装官方 SDK
以 Python 和 Node.js 为例:
pip install google-genai
npm install @google/genai
步骤 3:编写最小 Python 示例
from google import genai
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
response = client.models.generate_content(
model="gemini-3-pro-preview",
contents="用两三句话解释一下什么是 Gemini 3 API。",
)
print(response.text)
这个示例做了几件事:
- 使用
gemini-3-pro-preview模型; - 通过
generate_content发送一个简单的文本 prompt; - 将模型返回的
response.text打印到终端。
步骤 4:编写最小 Node.js 示例
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({
apiKey: process.env.GEMINI_API_KEY,
});
async function main() {
const result = await ai.models.generateContent({
model: "gemini-3-pro-preview",
contents: "用中文简要介绍 Gemini 3 Pro 的主要特性。",
});
console.log(result.response.text());
}
main().catch(console.error);
此处需要注意:
- 不同语言 SDK 的细节略有差异,但核心参数基本一致:
model、contents、可选的generation_config等; - 在生产环境中,不要把 API Key 写死在代码里,应通过环境变量或密钥管理服务注入。
五、多模态与长上下文的实践示例
Gemini 3 API 的一大亮点,是在多模态和长上下文场景下的能力提升。下面给出两个常见场景的设计思路。
场景 1:长文档问答(PDF + 问题)
典型需求:给模型一份 100 页的技术白皮书,让它回答“这份白皮书的核心结论是什么?”、“有哪些和隐私相关的约束?” 等问题。
可以考虑的设计:
- 将 PDF 上传到 Files API 或使用 URL 引用的方式,让模型在后台预处理文档内容;
- 通过
media_resolution_medium处理 PDF,大多数情况下足够; - 使用上下文缓存,将文档表示缓存起来,后续多次问答复用;
- 在 prompt 中明确告知模型“先阅读文档,再回答问题”,避免模型幻想未在文档中出现的信息。
场景 2:图像 + 文本联合分析
例如让模型阅读用户上传的原型图,并结合文字需求生成前端代码草稿。在这种场景下:
- 对图像通常使用
media_resolution_high,保证 UI 元素和文字的可读性; - 在 prompt 中说明“先理解图片中的界面结构,再结合文字说明生成代码”;
- 可以结合工具调用(例如一个 code execution 工具)让模型直接给出可运行的代码片段。
设计 1M 上下文的 Prompt 策略
虽然 Gemini 3 Pro 支持 1M tokens 上下文,但并不意味着你应该把所有东西一次性塞进去。一个更稳妥的策略是:
- 按“章节 / 文件 / 对话阶段”对内容分块,必要时多轮交互;
- 利用缓存与检索,将真正相关的内容拼接到 prompt 中,而不是全部塞入;
- 对于极长的上下文,尽量采用“先总结后推理”的分步式提示结构。
六、实战最佳实践与常见踩坑
结合官方文档和社区经验,下面列出一些在使用 Gemini 3 API 时常见的问题与建议。
1. 认证与配额
- 始终通过 HTTPS 访问官方 endpoint,不要使用非官方代理;
- 在服务器端存储和使用 API Key,避免暴露到前端;
- 注意免费层与付费层的差异:免费层内容可能会用于产品优化,付费层默认不用于训练;
- 对关键服务设置超时和重试策略,并根据官方 Rate Limits 文档设置合理的 QPS。
2. 参数调优:质量 vs 成本
几个常用参数的简单经验值:
temperature:- 0.2–0.4:适合需要稳定输出的任务,如代码生成、结构化摘要;
- 0.7 左右:适合创意写作、头脑风暴;
thinking_level:low:高并发、轻量任务;high:代码审查、复杂推理、法律/金融文档分析;
media_resolution:- 对性能敏感时优先从
low/medium起步,再根据质量需求提升。
- 对性能敏感时优先从
3. 错误处理与调试
常见错误包括:认证失败(Key 配置错误)、请求体格式错误、超出上下文限制、超出速率限制等。建议:
- 对所有错误做结构化日志记录(包含请求 ID、模型、提示长度等);
- 在开发环境中打开更详细的日志输出,必要时结合 thought signatures 分析失败案例;
- 对明显可重试的错误(如暂时性 5xx 或超时)采用指数退避重试策略。
七、常见问题解答(FAQ)
Q1:如何申请 Gemini 3 API Key?
A:前往 Google AI Studio,在 “Get API key” 页面创建一个新的 API Key。生成后将其配置到后端服务的环境变量中(例如 GEMINI_API_KEY),不要直接写在代码仓库里。不同账号和地区可能有访问与配额差异,建议提前阅读官方文档中的使用政策和可用区域说明。
Q2:Gemini 3 与 Gemini 2.5 有什么区别?
A:Gemini 3 在推理能力、多模态表现和上下文窗口方面都有明显提升。Gemini 3 Pro 提供约 1M tokens 的输入上下文,并通过 thinking_level 等参数让你更精细地控制“思考深度”。如果你的应用涉及复杂推理、长文档或多模态任务,升级到 Gemini 3 通常能获得更好的效果。
Q3:Gemini 3 Pro 有免费额度吗?
A:官方为 Gemini API 提供一定的免费额度(额度和细则会随时间调整),具体以官方定价页面为准。需要注意的是,免费层和付费层在数据使用政策上可能不同:免费层内容可能用于模型与产品优化,付费层则通常不会用于训练。对于企业或对隐私敏感的场景,建议使用付费层或 Vertex AI/Gemini Enterprise。
Q4:如何在企业环境中使用 Gemini 3 Pro?
A:对于企业用户,通常会通过 Vertex AI 或 Gemini Enterprise 来访问 Gemini 3 Pro。这样可以获得更细粒度的身份认证与权限控制、更丰富的日志与监控,以及与现有云基础设施(VPC、私有网络、数据加密等)的集成能力。定价与配额也会与 Developer API 略有不同,建议让云架构师结合企业现有架构进行整体评估。
八、总结与下一步行动
Gemini 3 API 为开发者带来了一个“能真正思考、能读懂复杂多模态输入、还能在长上下文中保持稳定表现”的大模型平台。通过 gemini-3-pro-preview,你可以在一个统一的接口下完成文本对话、多文档问答、图像/视频理解和代理式工作流等任务;而诸如 thinking_level、media_resolution、Batch API 和上下文缓存等新能力,则为你在质量、延迟和成本之间提供了更多“调节旋钮”。
如果用一句话概括本文的要点,那就是:先用官方文档和本文的大纲理解 Gemini 3 API 的整体能力,再结合自己的业务场景,在“模型、参数、上下文设计与成本控制”四个维度做权衡。
下一步,你可以:
- 按本文的 Quickstart 部分完成首次调用;
- 选取一个真实的业务问题(例如长文档审阅、多模态检索或自动编码),尝试用 Gemini 3 Pro 重新实现;
- 逐步引入
thinking_level、多模态和 Batch API 等能力,在实践中摸索一套适合自己团队的参数与架构模板。
只要合理设计提示、控制成本并结合权威文档更新,Gemini 3 API 完全可以成为你在 2025 年之后构建智能应用和代理系统的核心基础设施之一。
在企业用户部分,官方还提供了专门的 Gemini Enterprise 产品页面,介绍了企业级访问 Gemini 3 Pro 时在安全、合规和集成能力上的差异。